python批量小说txt文件转json文件
最新推荐文章于 2024-04-04 12:29:08 发布

rightstar_
 最新推荐文章于 2024-04-04 12:29:08 发布
最新推荐文章于 2024-04-04 12:29:08 发布
 阅读量1.8k
阅读量1.8k
 收藏
14
收藏
14
 点赞数
点赞数
最新推荐文章于 2024-04-04 12:29:08 发布
阅读量1.8k
收藏
14

 点赞数
点赞数

前言
最近在做一个项目涉及小说文件的处理,项目要提供小说在线观看的功能。
因为小说文件大概有10GB放在mysql不切实际,而且希望用redis做一些缓冲,故小说文件转为json格式更方便数据操作。
由于资源网站获取来的小说文件为txt格式,故需要用python进行一些转换,下文为本人的处理方式
原文件
-
文件名格式

-
小说内容格式
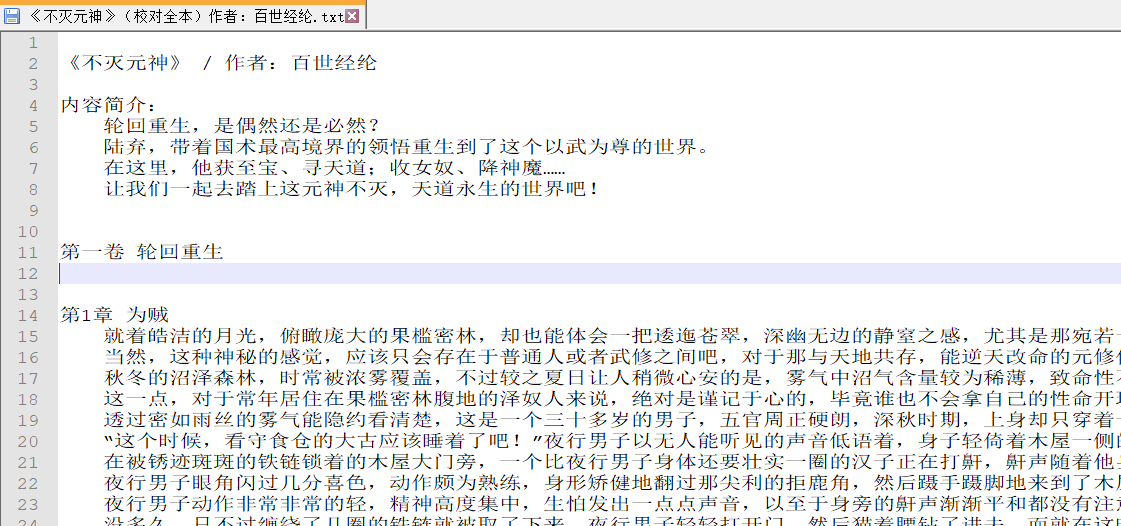
-
编码格式
小说txt文件为UTF-8编码
注:原txt文件不为UTF-8需转换工具:下载
目标文件
-
小说汇总文件book.json

-
各小说内容文件
- 文件名格式 bookID.json
- 文件格式


python代码
import os,sys
import json,re
class fileScanner(object):
def __init__(self,dir):
self.dir = dir
self.files = []
self.size = 0;
def scanFile(self):
##扫描所有txt文件
filetype ='.txt'
file = {
'fileName':'',
'filePath':''
}
for parent,dirnames,filenames in os.walk(self.dir):
for filename in filenames:
file = {
'fileName':'',
'filePath':''
}
file['fileName'] = filename
file['filePath']= os.path.join(parent, filename)
if file['filePath'].find(filetype)!=-1:
self.files.append(file)
print("扫描到: "+file['filePath'])
self.size+=1
class bookTojson(object):
def __init__(self,files):
self.files = files
self.books = []
def readBookDetail(self,n):
detail = {
'bookID':n,
'bookName':'无',
'autor':'无',
'bookType':'无'
}
fileName = self.files[n]['fileName']
fileName = fileName.replace('.txt','') #文件名清理
fileName= re.sub(r'【(.*)】', "", fileName) #文件名清理
detail['bookName'] = fileName #初始赋值小说名,防止为空
if re.search(r'《(.*)》',fileName):
#print('书名:'+re.search(r'《(.*)》',fileName).group().strip('《》'))
detail['bookName'] = re.search(r'《(.*)》',fileName).group().strip('《》')
fileName= re.sub(r'《(.*)》', "", fileName)
if re.search(r'\[(.*)\]',fileName):
#print('类别:'+re.search(r'\[(.*)\]',fileName).group().strip('[]'))
detail['bookType'] = re.search(r'\[(.*)\]',fileName).group().strip('[]')
if len(fileName.split('作者:'))>1:
#print('作者:'+fileName.split('作者:')[1])#文件名编码为GB2312
detail['autor'] = fileName.split('作者:')[1]
self.books.append(detail)
#输出小说内容为json
def writeJson(self,book,bookID):
jsonArr = json.dumps(book, ensure_ascii=False, sort_keys=False, indent=4, separators=(',', ': '))
filePath ='D:\\BaiduNetdiskDownload\\books\\bookJson\\'+str(bookID)+'.json'
with open(filePath, 'w+', encoding='utf-8') as f:
f.writelines(jsonArr)
#
#处理小说输出章节及内容
def readBookContent(self,n):
book = {
'bookID':n,
'bookName':self.books[n]['bookName'],
'autor':self.books[n]['autor'],
'bookType':self.books[n]['bookType'],
'chapters':[],##章节 item {}
'contents':{}##
}
chapterName = ''
content = ''
fopen=open(self.files[n]['filePath'],encoding = 'utf-8',mode = 'r')
lines=[]
lines=fopen.readlines()
index = 1 #章节号
flag = 0 #读取到章节内容的标志
for line in lines:
if len(line)>0:
if re.match(r'^(\\s*)',line)==None:
if ord(line[0])!=12288:
#读取到章节标题
#print(line)
chapterName+=(line+' ')
flag = 0
else:
#读取到章节内容
if flag == 0:
flag =1
#可以写入章节内容
else:
flag+=1
content+=line
else:
#读取到章节内容
if flag == 0:
flag =1
#可以写入章节内容
else:
flag+=1
content+=line
if flag == 1 :
#上一章内容写入
if index > 1:
book['contents'][str(n)+str(index-1)] = content
content = line #新章节内容开始
if chapterName != None:
chapter = {
'chapterID':'',
'chapterName':'无',
} #注意字典for内赋值问题
chapter['chapterID'] = str(n)+str(index)
chapter['chapterName'] = chapterName
chapterName = ''
book['chapters'].append(chapter)
#章节标题读取结束
index += 1
#末端章节
book['contents'][str(n)+str(index-1)] = content
self.writeJson(book,n)
#print(json.dumps(book, ensure_ascii=False, sort_keys=False, indent=4, separators=(',', ': ')))
def runFun(self,n):
try:
self.readBookDetail(n)
self.readBookContent(n)
except Exception:
print('文件'+str(n)+'错误')
if __name__ == "__main__":
#填入小说文件夹名
fs = fileScanner("D:\\BaiduNetdiskDownload\\books\\books") #注意路径带双斜杠 防止出现转义字符\n等
print('获取小说文件名:')
fs.scanFile()
bTj = bookTojson(fs.files)
print('开始处理小说:')
for i in range(0,len(fs.files)):
bTj.runFun(i)
sys.stdout.write(" 已处理:%.3f%%" % float(((i/len(fs.files)))*100) + '\r')
sys.stdout.flush()
print('小说处理完成')
data=bTj.books
jsonArr = json.dumps(data, ensure_ascii=False, sort_keys=False, indent=4, separators=(',', ': '))
print('文件json格式已输出')
with open('books.json', 'w+', encoding='utf-8') as f:
f.writelines(jsonArr)
print("小说数%d"%fs.size)
运行结果


后言
然后10个G的2000部小说大概跑了一个小时才全部转为json ヽ(ー_ー)ノ ,算法问题欢迎大佬指正下方留言,注:需要资源也可下方留言















 1647
1647










 高校学生
高校学生
























 到【灌水乐园】发言
到【灌水乐园】发言










m0_62471092: 我已经私信你了,可以帮我看一下吗,谢谢
预备全栈工程师的小白: 啥错误啊
m0_62471092: 我打开显示错误,请问能帮忙看一下吗
m0_62471092: 我打开显示错误,请问能帮忙看一下吗
m0_62471092: 我打开cu