

前言
本文是笔者对 Mario Kosaka写的 inside look at modern web browser系列文章的翻译。这里的翻译不是指直译,而是结合个人的理解将作者想表达的意思表达出来,而且会尽量补充一些相关的内容来帮助大家更好地理解。
这篇文章是我对之前发表的窥探浏览器内部原理系列文章的一个整合,大家如果觉得内容太多可以按篇查看以前的文章:
- 窥探现代浏览器架构(一)
- 窥探现代浏览器架构(二)
- 窥探现代浏览器架构(三)
- 窥探现代浏览器架构(四)
CPU,GPU,内存和多进程架构
在本篇文章中,我将会从Chrome浏览器的高层次架构(high-level architecture)开始说起,一直深入讲到页面渲染流水线(rendering pipeline)的具体细节。如果你想知道浏览器是怎么把你编写的代码转变成一个可用的网站,或者你不知道为什么一些特定的代码写法可以提高网站的性能的,那你就来对地方了,这篇文章就是为你准备的。
首先我们先了解一些关键的计算机术语以及Chrome浏览器的多进程架构。
计算机的核心 - CPU和GPU
要想理解浏览器的运行环境,我们先要搞明白一些计算机组件以及它们的作用。
CPU
首先我们要说的是计算机的大脑 - CPU(Central Processing Unit)。CPU是计算机里面的一块芯片,上面有一个或者多个核心(core)。我们可以把CPU的一个核心(core)比喻成一个办公室工人,他功能强大,上知天文下知地理,琴棋书画无所不能,它可以串行地一件接着一件处理交给它的任务。很久之前的时候大多数CPU只有一个核心,不过在现在的硬件设备上CPU通常会有多个核心,因为多核心CPU可以大大提高手机和电脑的运算能力。
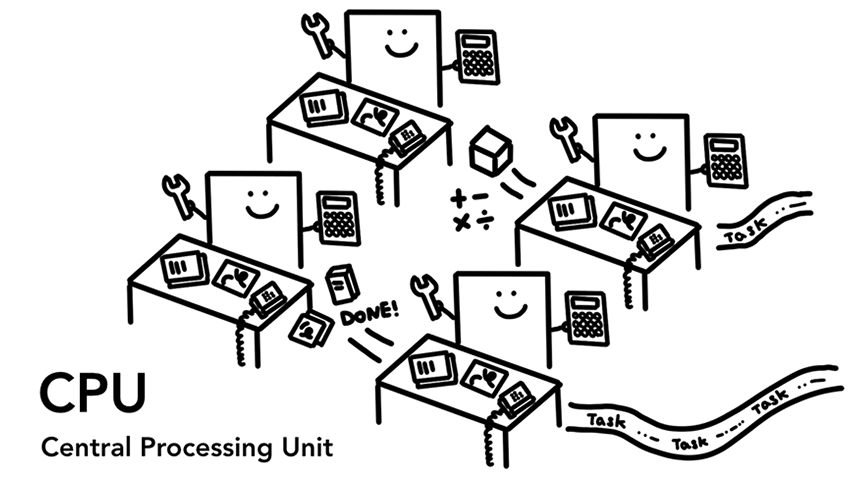
四个CPU核心愉快地在各自工位上一个接着一个地处理交给它们的任务
GPU
图形处理器 - 或者说GPU(Graphics Processing Unit)是计算机的另外一个重要组成部分。和功能强大的CPU核心不一样的是,单个GPU核心只能处理一些简单的任务,不过它胜在数量多,单片GPU上会有很多很多的核心可以同时工作,也就是说它的并行计算能力是非常强的。图形处理器(GPU)顾名思义一开始就是专门用来处理图形的,所以在说到图形使用GPU(using)或者GPU支持(backed)时,人们就会联想到图形快速渲染或者流畅的用户体验相关的概念。最近几年来,随着GPU加速概念的流行,在GPU上单独进行的计算也变得越来越多了。
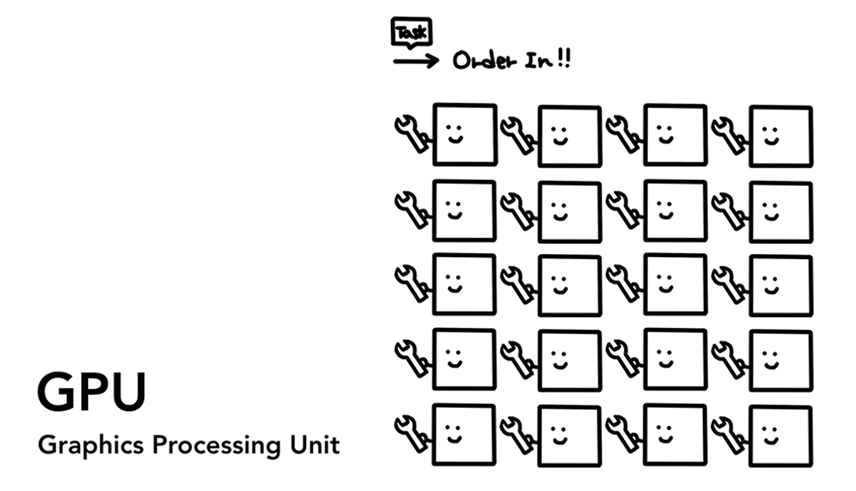
每个GPU核心手里只有一个扳手,这就说明它的能力是非常有限的,可是它们人多啊!
当你在手机或者电脑上打开某个应用程序的时候,背后其实是CPU和GPU支撑着这个应用程序的运行。通常来说,你的应用要通过操作系统提供的一些机制才能跑在CPU和GPU上面。
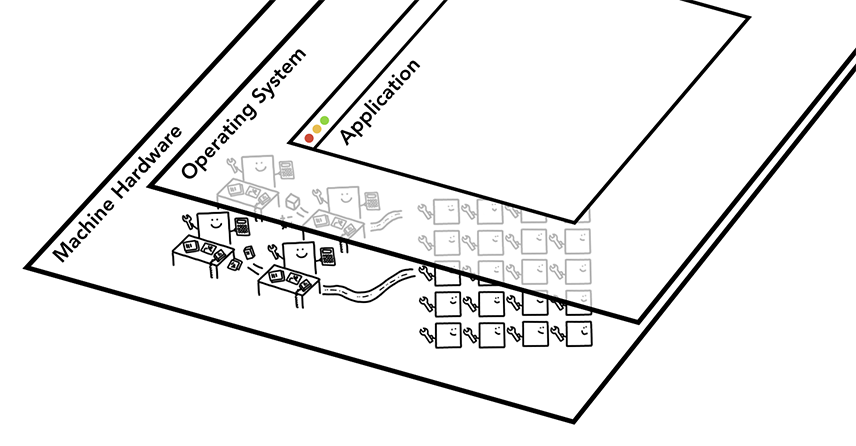
计算机的三层架构,最下层是硬件机器,操作系统夹在中间,最上层是运行的应用
在进程和线程上执行程序
在深入到浏览器的架构之前我们还得了解一下进程(process)和线程(thread)的相关概念。进程可以看成正在被执行的应用程序(executing program)。而线程是跑在进程里面的,一个进程里面可能有一个或者多个线程,这些线程可以执行任何一部分应用程序的代码。
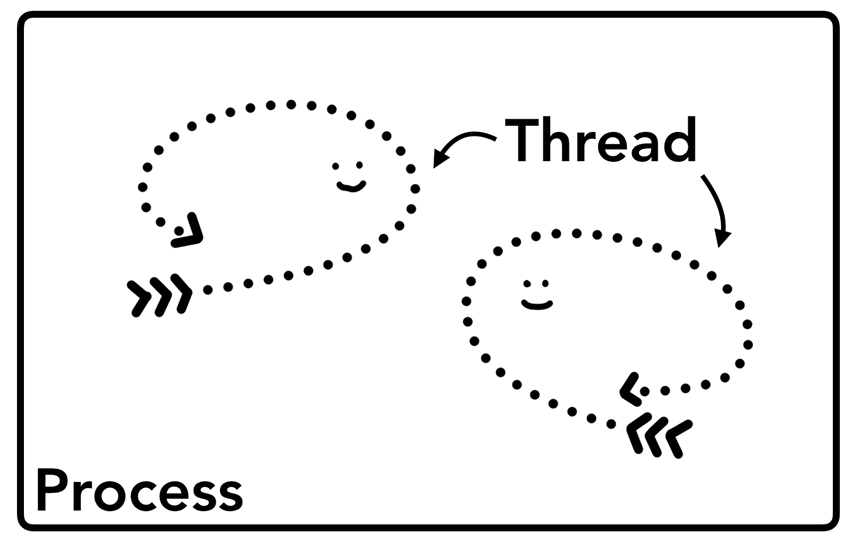
进程就像一个大鱼缸,而线程就是浴缸里面畅游的鱼儿
当你启动一个应用程序的时候,操作系统会为这个程序创建一个进程同时还为这个进程分配一片私有的内存空间,这片空间会被用来存储所有程序相关的数据和状态。当你关闭这个程序的时候,这个程序对应的进程也会随之消失,进程对应的内存空间也会被操作系统释放掉。
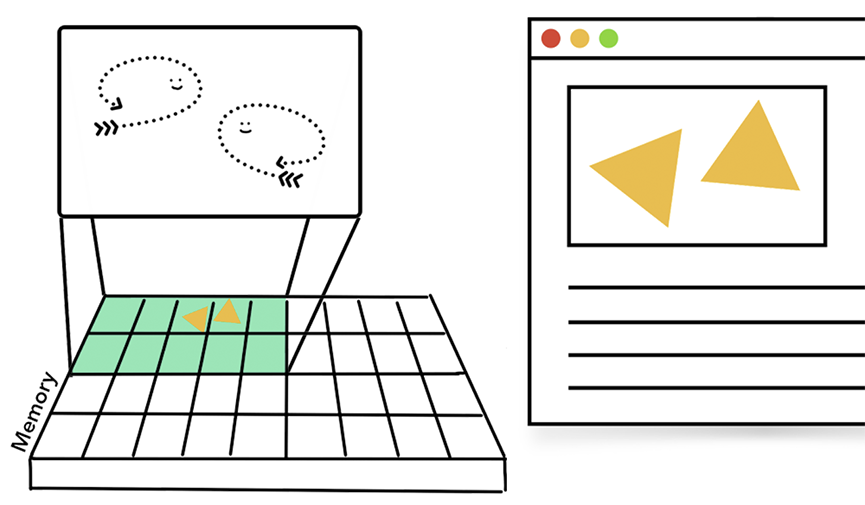
进程使用系统分配的内存空间去存储应用的数据
有时候为了满足功能的需要,创建的进程会叫系统创建另外一些进程去处理其它任务,不过新建的进程会拥有全新的独立的内存空间而不是和原来的进程共用内存空间。如果这些进程需要通信,它们要通过IPC机制(Inter Process Communication)来进行。很多应用程序都会采取这种多进程的方式来工作,因为进程和进程之间是互相独立的它们互不影响,换句话来说,如果其中一个工作进程(worker process)挂掉了其他进程不会受到影响,而且挂掉的进程还可以重启。
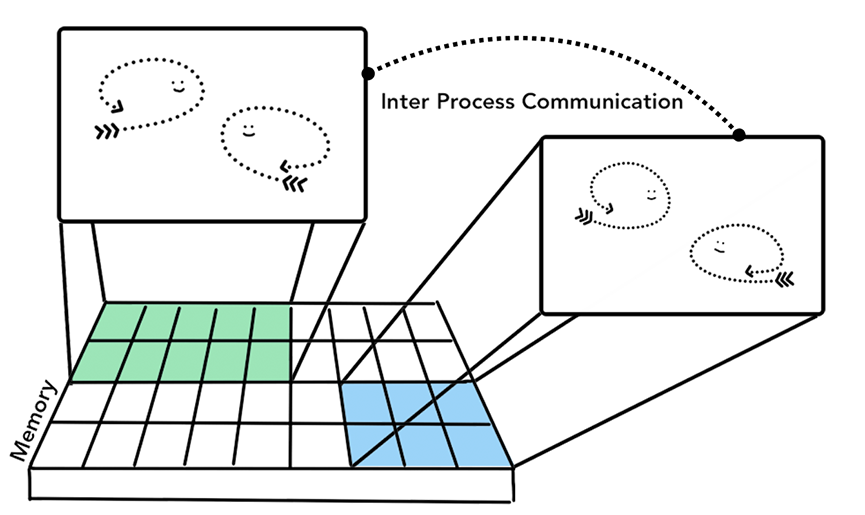
不同的进程通过IPC来通信
浏览器架构
那么浏览器是怎么使用进程和线程来工作的呢?其实大概可以分为两种架构,一种是单进程架构,也就是只启动一个进程,这个进程里面有多个线程工作。第二种是多进程架构,浏览器会启动多个进程,每个进程里面有多个线程,不同进程通过IPC进行通信。
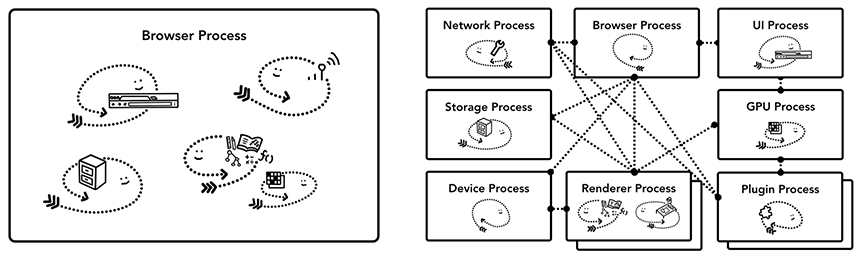
单进程和多进程浏览器的架构图
上面的图表架构其实包含了浏览器架构的具体实现了,在现实中其实并没有一个大家都遵循的浏览器实现标准,所以不同浏览器的实现方式可能会完全不一样。
为了更好地在本系列文章中展开论述,我们主要讨论最新的Chrome浏览器架构,它采用的是多进程架构,以下是架构图:
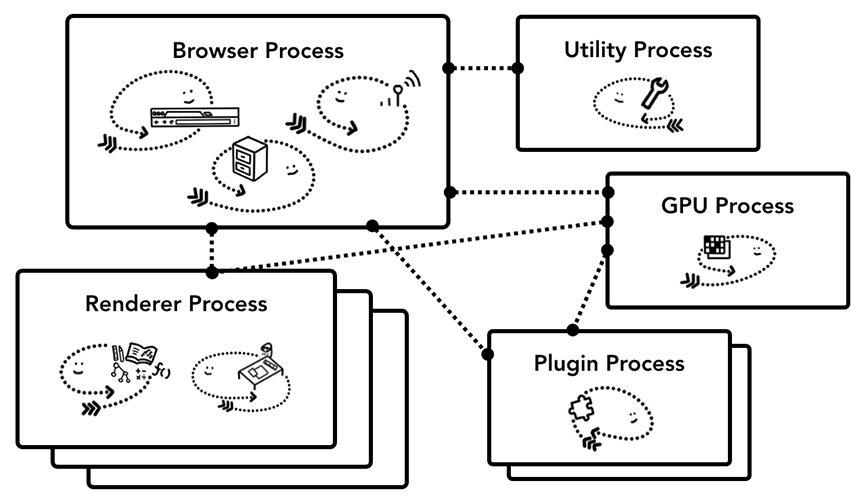
Chrome的多进程架构图,多个渲染进程的卡片(render process)是用来表明Chrome会为每一个tab创建一个渲染进程。
Chrome浏览器会有一个浏览器进程(browser process),这个进程会和其他进程一起协作来实现浏览器的功能。对于渲染进程(renderer process),Chrome会尽可能为每一个tab甚至是页面里面的每一个iframe都分配一个单独的进程。
各个进程如何分工合作呢?
以下是各个进程具体负责的工作内容:
| 进程 | 负责的工作 |
|---|---|
| Browser | 负责浏览器的“Chrome”部分, 包括导航栏,书签, 前进和后退按钮。同时这个进程还会控制那些我们看不见的部分,包括网络请求的发送以及文件的读写。 |
| Renderer | 负责tab内和网页展示相关的所有工作。 |
| Plugin | 控制网页使用的所有插件,例如flash插件。 |
| GPU | 负责独立于其它进程的GPU任务。它之所以被独立为一个进程是因为它要处理来自于不同tab的渲染请求并把它在同一个界面上画出来。 |
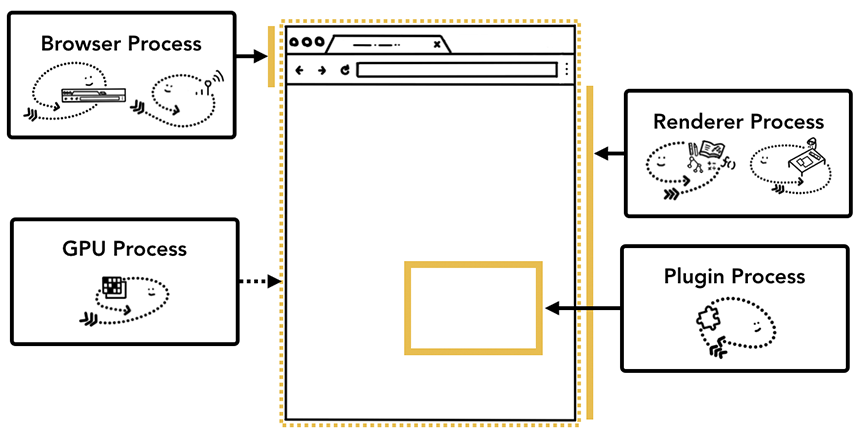
不同的进程负责浏览器不同部分的界面内容
除了上面列出来的进程,Chrome还有很多其他进程在工作,例如扩展进程(Extension Process)和工具进程(utility process)。如果你想看一下你的Chrome浏览器现在有多少个进程在跑可以点击浏览器右上角的更多按钮,选择更多工具和任务管理器:
Chrome多进程架构的好处
那么为什么Chrome会采取多进程架构工作呢?
其中一个好处是多进程可以使浏览器具有很好的容错性。对于大多数简单的情景来说,Chrome会为每个tab单独分配一个属于它们的渲染进程(render process)。举个例子,假如你有三个tab,你就会有三个独立的渲染进程。当其中一个tab的崩溃时,你可以随时关闭这个tab并且其他tab不受到影响。可是如果所有的tab都跑在同一个进程的话,它们就会有连带关系,一个挂全部挂。
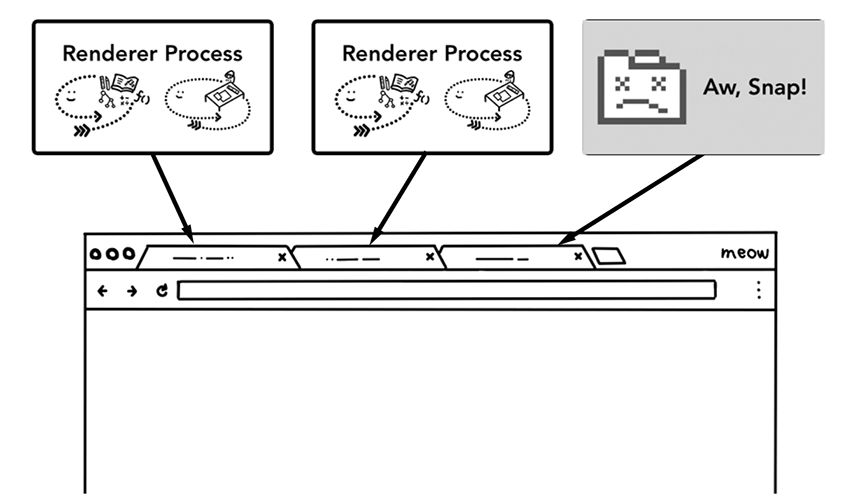
不同的tab会有不同的渲染进程来负责
Chrome采用多进程架构的另外一个好处就是可以提供安全性和沙盒性(sanboxing)。因为操作系统可以提供方法让你限制每个进程拥有的能力,所以浏览器可以让某些进程不具备某些特定的功能。例如,由于tab渲染进程可能会处理来自用户的随机输入,所以Chrome限制了它们对系统文件随机读写的能力。
不过多进程架构也有它不好的地方,那就是进程的内存消耗。由于每个进程都有各自独立的内存空间,所以它们不能像存在于同一个进程的线程那样共用内存空间,这就造成了一些基础的架构(例如V8 JavaScript引擎)会在不同进程的内存空间同时存在的问题,这些重复的内容会消耗更多的内存。所以为了节省内存,Chrome会限制被启动的进程数目,当进程数达到一定的界限后,Chrome会将访问同一个网站的tab都放在一个进程里面跑。
节省更多的内存 - Chrome的服务化
同样的优化方法也可以被使用在浏览器进程(browser process)上面。Chrome浏览器的架构正在发生一些改变,目的是将和浏览器本身(Chrome)相关的部分拆分为一个个不同的服务,服务化之后,这些功能既可以放在不同的进程里面运行也可以合并为一个单独的进程运行。
这样做的主要原因是让Chrome在不同性能的硬件上有不同的表现。当Chrome运行在一些性能比较好的硬件时,浏览器进程相关的服务会被放在不同的进程运行以提高系统的稳定性。相反如果硬件性能不好,这些服务就会被放在同一个进程里面执行来减少内存的占用。其实在这次架构变化之前,Chrome在Android上面已经开始采取类似的做法了。
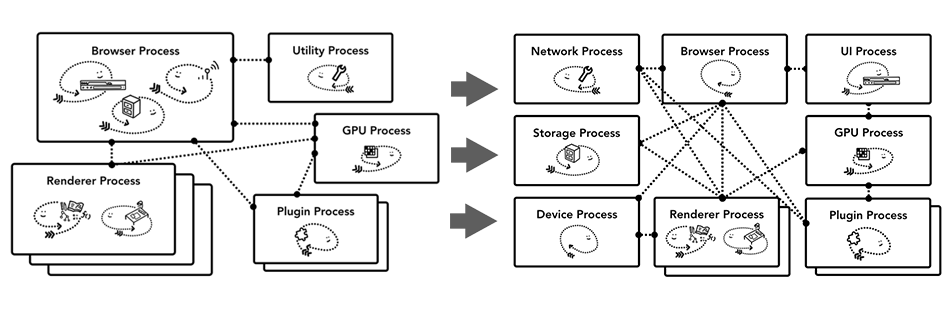
Chrome将浏览器相关的服务放在同一个进程里面运行和放在不同的进程运行的区别
单帧渲染进程 - 网站隔离(Site Isolation)
网站隔离(Site Isolation)是最近Chrome浏览器启动的功能,这个功能会为网站内不同站点的iframe分配一个独立的渲染进程。之前说过Chrome会为每个tab分配一个单独的渲染进程,可是如果一个tab只有一个进程的话不同站点的iframe都会跑在这个进程里面,这也意味着它们会共享内存,这就有可能会破坏 同源策略。同源策略是浏览器最核心的安全模型,它可以禁止网站在未经同意的情况下去获取另外一个站点的数据,因此绕过同源策略是很多安全攻击的主要目的。而进程隔离(proces isolation)是隔离网站最好最有效的办法了。再加上CPU存在 Meltdown和Spectre的隐患,网站隔离变得势在必行。因此在Chrome 67版本之后,桌面版的Chrome会默认开启网站隔离功能,这样每一个跨站点的iframe都会拥有一个独立的渲染进程。
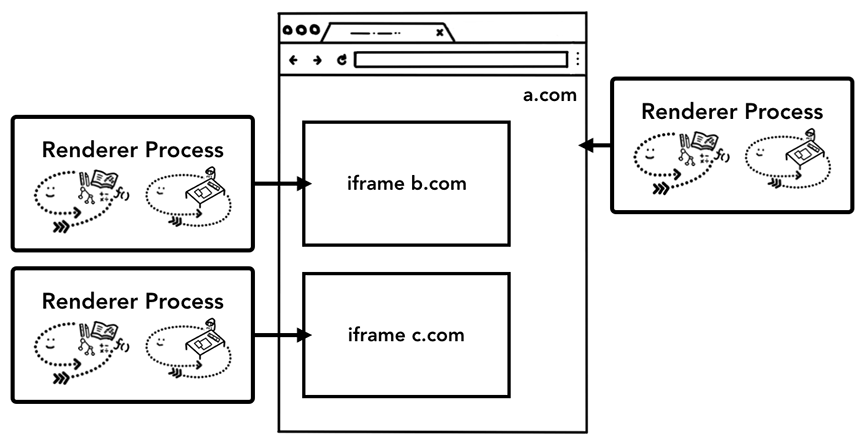
网站隔离功能会让跨站的iframe拥有独立的进程
网站隔离技术汇聚了我们工程师好几年的研发努力,它其实远远没有想象中那样只是为不同站点的iframe分配一个独立的渲染进程那么简单,因为它从根本上改变了各个iframe之间的通信方式。网站隔离后,对于有iframe的网站,当用户打开右边的devtool时,Chrome浏览器其实要做很多幕后工作才能让开发者感觉不出这和之前的有什么区别,这其实是很难实现的。对于一些很简单的功能,例如在devtool里面用Ctrl + F键在页面搜索某个关键词,Chrome都要遍历多个渲染进程去完成。所以我们的浏览器工程师在网站隔离这个功能发布后都感叹这是一个里程碑式的成就。
导航的时候都发生了什么
我们探讨了浏览器高层次的架构设计以及多进程架构的带来的好处。同时我们还讨论了服务化和网站隔离这些和浏览器多进程架构息息相关的技术。接下来我们要开始深入了解这些进程和线程是如何呈现我们的网站页面的了。
让我们来看一个用户浏览网页最简单的情景:你在浏览器导航栏里面输入一个URL然后按下回车键,浏览器接着会从互联网上获取相关的数据并把网页展示出来。在本篇文章中,我们将会重点关注这个简单场景中网站数据请求以及浏览器在呈现网页之前做的准备工作 - 也就是导航(navigation)的过程。
一切都从浏览器进程开始
上面的文章中提到,浏览器中tab外面发生的一切都是由浏览器进程(browser process)控制的。浏览器进程有很多负责不同工作的线程(worker thread),其中包括绘制浏览器顶部按钮和导航栏输入框等组件的UI线程(UI thread)、管理网络请求的网络线程(network thread)、以及控制文件读写的存储线程(storage thread)等。当你在导航栏里面输入一个URL的时候,其实就是UI线程在处理你的输入。
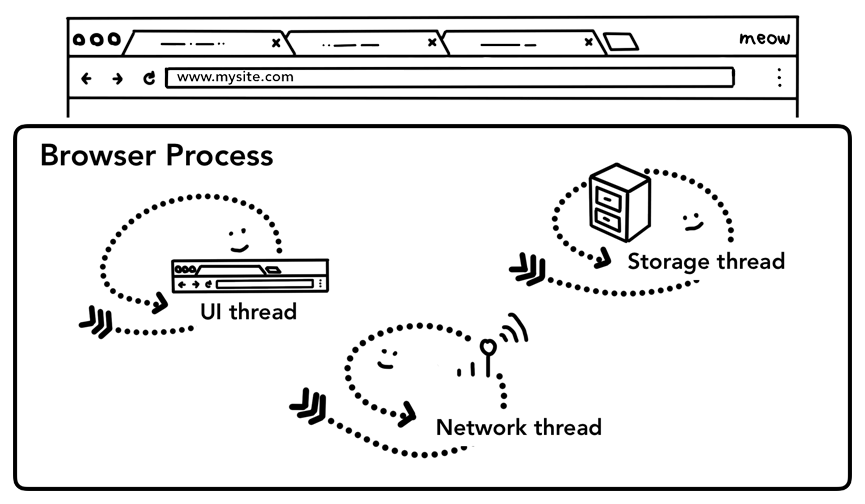
UI,网络和存储线程都是属于浏览器进程的
一次简单的导航
第一步:处理输入
当用户开始在导航栏上面输入内容的时候,UI线程(UI thread)做的第一件事就是询问:“你输入的字符串是一些搜索的关键词(search query)还是一个URL地址呢?”。因为对于Chrome浏览器来说,导航栏的输入既可能是一个可以直接请求的域名还可能是用户想在搜索引擎(例如Google)里面搜索的关键词信息,所以当用户在导航栏输入信息的时候UI线程要进行一系列的解析来判定是将用户输入发送给搜索引擎还是直接请求你输入的站点资源。
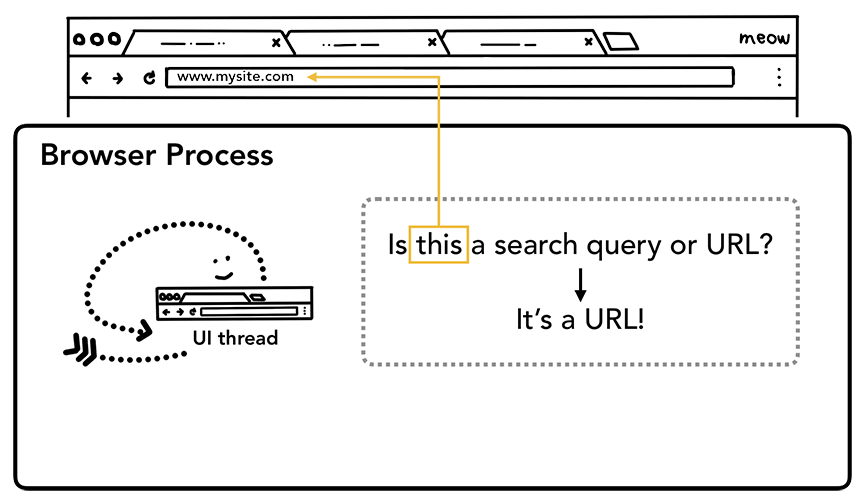
UI线程在询问输入的字符串是搜索关键词还是一个URL
第二步:开始导航
当用户按下回车键的时候,UI线程会叫网络线程(network thread)初始化一个网络请求来获取站点的内容。这时候tab上会展示一个提示资源正在加载中的旋转圈圈,而且网络线程会进行一系列诸如DNS寻址以及为请求建立TLS连接的操作。
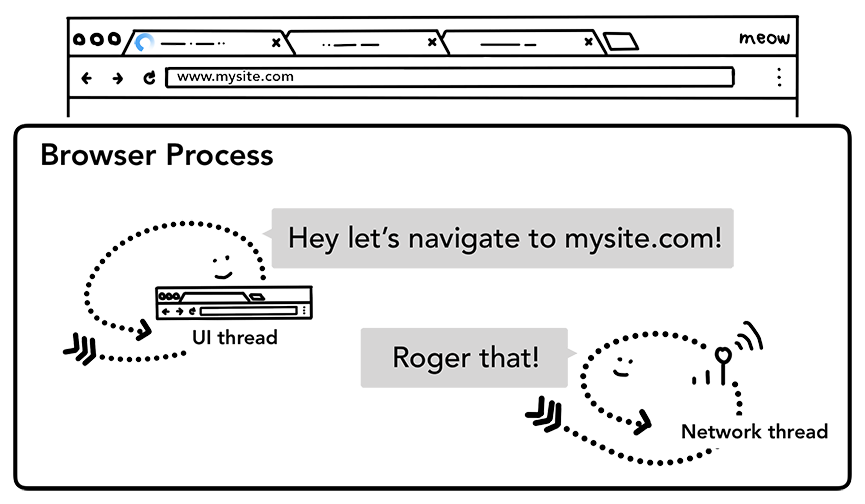
UI线程告诉网络线程跳转到mysite.com
这时如果网络线程收到服务器的HTTP 301重定向响应,它就会告知UI线程进行重定向然后它会再次发起一个新的网络请求。
第三步:读取响应
网络线程在收到HTTP响应的主体(payload)流(stream)时,在必要的情况下它会先检查一下流的前几个字节以确定响应主体的具体媒体类型(MIME Type)。响应主体的媒体类型一般可以通过HTTP头部的Content-Type来确定,不过Content-Type有时候会缺失或者是错误的,这种情况下浏览器就要进行 MIME类型嗅探来确定响应类型了。MIME类型嗅探并不是一件容易的事情,你可以从 Chrome的源代码的注释来了解不同浏览器是如何根据不同的Content-Type来判断出主体具体是属于哪个媒体类型的。
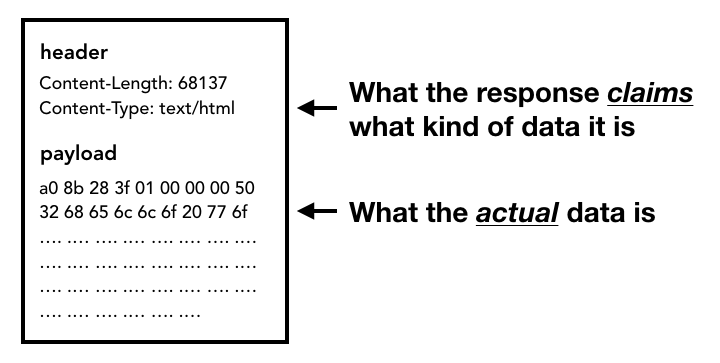
响应的头部有Content-Type信息,而响应的主体有真实的数据
如果响应的主体是一个HTML文件,浏览器会将获取的响应数据交给渲染进程(renderer process)来进行下一步的工作。如果拿到的响应数据是一个压缩文件(zip file)或者其他类型的文件,响应数据就会交给下载管理器(download manager)来处理。
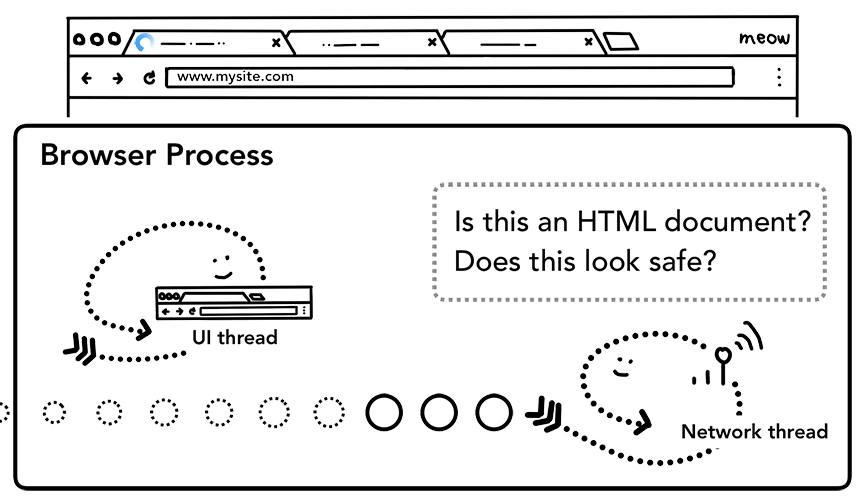
网络线程在询问响应的数据是不是来自安全源的HTML文件
网络线程在把内容交给渲染进程之前还会对内容做 SafeBrowsing检查。如果请求的域名或者响应的内容和某个已知的病毒网站相匹配,网络线程会给用户展示一个警告的页面。除此之外,网络线程还会做 CORB(Cross Origin Read Blocking)检查来确定那些敏感的跨站数据不会被发送至渲染进程。
第四步:寻找一个渲染进程(renderer process)
在网络线程做完所有的检查后并且能够确定浏览器应该导航到该请求的站点,它就会告诉UI线程所有的数据都已经被准备好了。UI线程在收到网络线程的确认后会为这个网站寻找一个渲染进程(renderer process)来渲染界面。
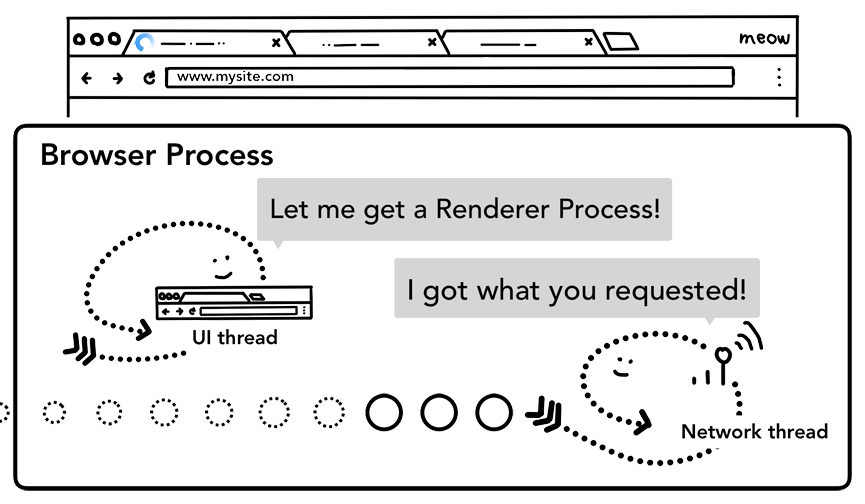
网络线程告诉UI线程去寻找一个渲染进程来渲染界面
由于网络请求可能需要长达几百毫秒的时间才能完成,为了缩短导航需要的时间,浏览器会在之前的一些步骤里面做一些优化。例如在第二步中当UI线程发送URL链接给网络线程后,它其实已经知晓它们要被导航到哪个站点了,所以在网络线程干活的时候,UI线程会主动地为这个网络请求启动一个渲染线程。如果一切顺利的话(没有重定向之类的东西出现),网络线程准备好数据后页面的渲染进程已经就准备好了,这就节省了新建渲染进程的时间。不过如果发生诸如网站被重定向到不同站点的情况,刚刚那个渲染进程就不能被使用了,它会被摒弃,一个新的渲染进程会被启动。
第五步:提交(commit)导航
到这一步的时候,数据和渲染进程都已经准备好了,浏览器进程(browser process)会通过IPC告诉渲染进程去提交本次导航(commit navigation)。除此之外浏览器进程还会将刚刚接收到的响应数据流传递给对应的渲染进程让它继续接收到来的HTML数据。一旦浏览器进程收到渲染线程的回复说导航已经被提交了(commit),导航这个过程就结束了,文档的加载阶段(document loading phase)会正式开始。
到了这个时候,导航栏会被更新,安全指示符(security indicator)和站点设置UI(site settings UI)会展示新页面相关的站点信息。当前tab的会话历史(session history)也会被更新,这样当你点击浏览器的前进和后退按钮也可以导航到刚刚导航完的页面。为了方便你在关闭了tab或窗口(window)的时候还可以恢复当前tab和会话(session)内容,当前的会话历史会被保存在磁盘上面。
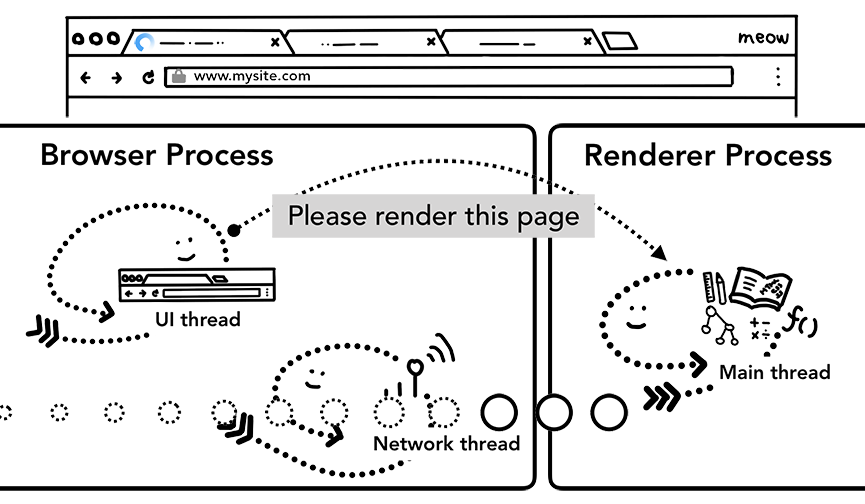
浏览器进程通过IPC来对渲染进程发起渲染页面的请求
额外步骤:初始加载完成(Initial load complete)
当导航提交完成后,渲染进程开始着手加载资源以及渲染页面。我会在后面的文章中讲述渲染进程渲染页面的具体细节。一旦渲染进程“完成”(finished)渲染,它会通过IPC告知浏览器进程(注意这发生在页面上所有帧(frames)的onload事件都已经被触发了而且对应的处理函数已经执行完成了的时候),然后UI线程就会停止导航栏上旋转的圈圈。
我这里用到“完成”这个词,因为后面客户端的JavaScript还是可以继续加载资源和改变视图内容的。
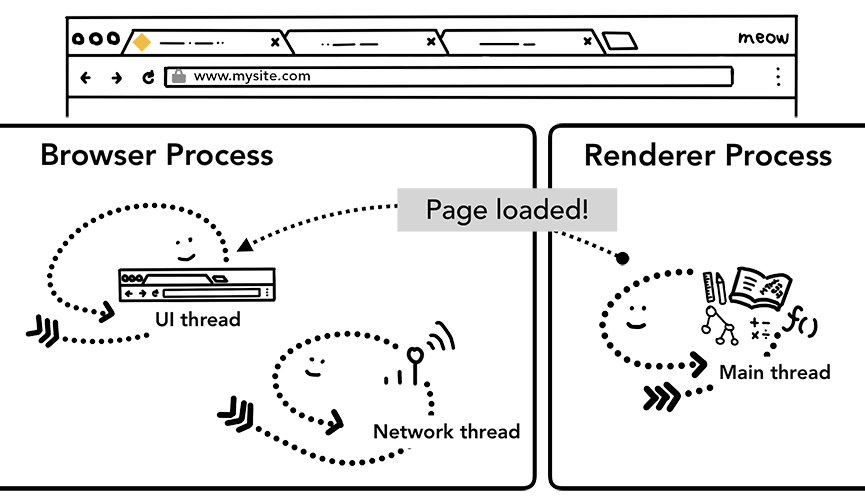
渲染进程通过IPC告诉浏览器进程页面已经加载完成了
导航到不同的站点
一个最简单的导航情景已经描述完了!可是如果这时用户在导航栏上输入一个不一样的URL会发生什么呢?如果是这样,浏览器进程会重新执行一遍之前的那几个步骤来完成新站点的导航。不过在浏览器进程做这些事情之前,它需要让当前的渲染页面做一些收尾工作,具体就是询问一下当前的渲染进程需不需要处理一下 beforeunload事件。
beforeunload可以在用户重新导航或者关闭当前tab时给用户展示一个“你确定要离开当前页面吗?”的二次确认弹框。浏览器进程之所以要在重新导航的时候和当前渲染进程确认的原因是,当前页面发生的一切(包括页面的JavaScript执行)是不受它控制而是受渲染进程控制,所以它也不知道里面的具体情况。
注意:不要随便给页面添加beforeunload事件监听,你定义的监听函数会在页面被重新导航的时候执行,因此这会增加重导航的时延。beforeunload事件监听函数只有在十分必要的时候才能被添加,例如用户在页面上输入了数据,并且这些数据会随着页面消失而消失。
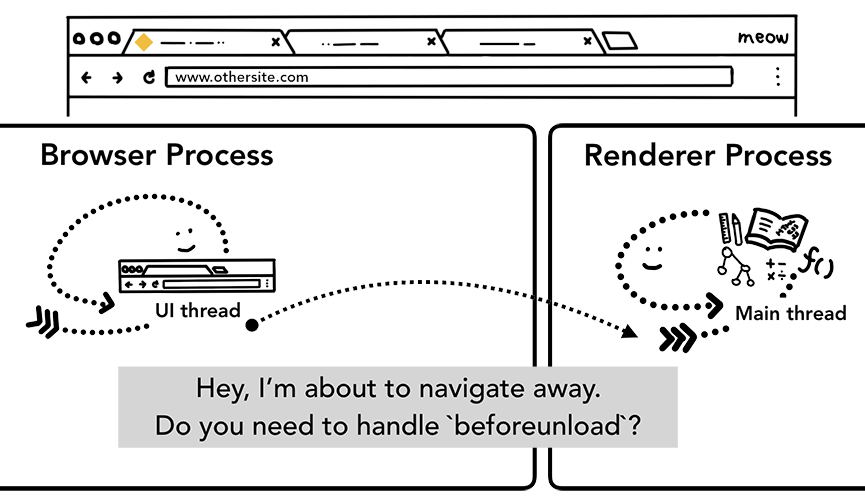
浏览器进程通过IPC告诉渲染进程它将要离开当前页面导航到新的页面了
如果重新导航是在页面内被发起的呢?例如用户点击了页面的一个链接或者客户端的JavaScript代码执行了诸如window.location = " newsite.com"的代码。这种情况下,渲染进程会自己先检查一个它有没有注册beforeunload事件的监听函数,如果有的话就执行,执行完后发生的事情就和之前的情况没什么区别了,唯一的不同就是这次的导航请求是由渲染进程给浏览器进程发起的。
如果是重新导航到不同站点(different site)的话,会有另外一个渲染进程被启动来完成这次重导航,而当前的渲染进程会继续处理现在页面的一些收尾工作,例如unload事件的监听函数执行。 Overview of page lifecycle states这篇文章会介绍页面所有的生命周期状态, the Page Lifecycle API会教你如何在页面中监听页面状态的变化。
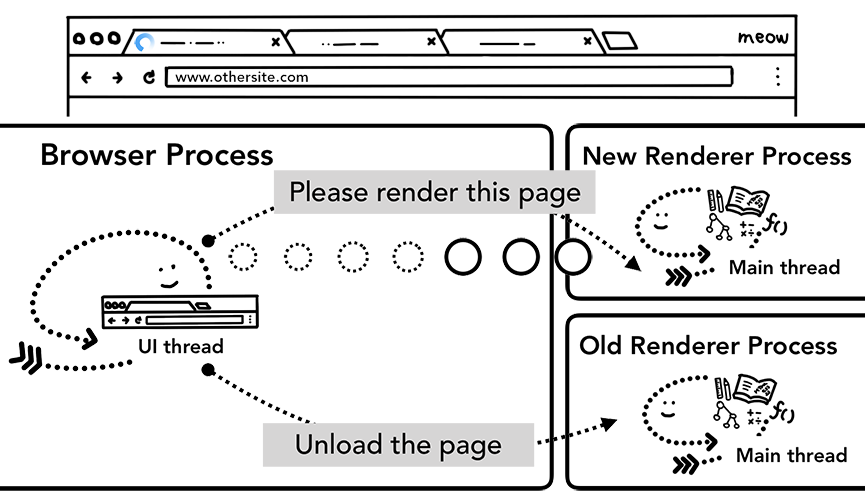
浏览器进程告诉新的渲染进程去渲染新的页面并且告诉当前的渲染进程进行收尾工作
Service Worker的情景
这个导航过程最近发生的一个改变是引进了 service worker的概念。因为Service worker可以用来写网站的网络代理(network proxy),所以开发者可以对网络请求有更多的控制权,例如决定哪些数据缓存在本地以及哪些数据需要从网络上面重新获取等等。如果开发者在service worker里设置了当前的页面内容从缓存里面获取,当前页面的渲染就不需要重新发送网络请求了,这就大大加快了整个导航的过程。
这里要重点留意的是service worker其实只是一些跑在渲染进程里面的JavaScript代码。那么问题来了,当导航开始的时候,浏览器进程是如何判断要导航的站点存不存在对应的service worker并启动一个渲染进程去执行它的呢?
其实service worker在注册的时候,它的作用范围(scope)会被记录下来(你可以通过文章 The Service Worker Lifecycle了解更多关于service worker作用范围的信息)。在导航开始的时候,网络线程会根据请求的域名在已经注册的service worker作用范围里面寻找有没有对应的service worker。如果有命中该URL的service worker,UI线程就会为这个service worker启动一个渲染进程(renderer process)来执行它的代码。Service worker既可能使用之前缓存的数据也可能发起新的网络请求。
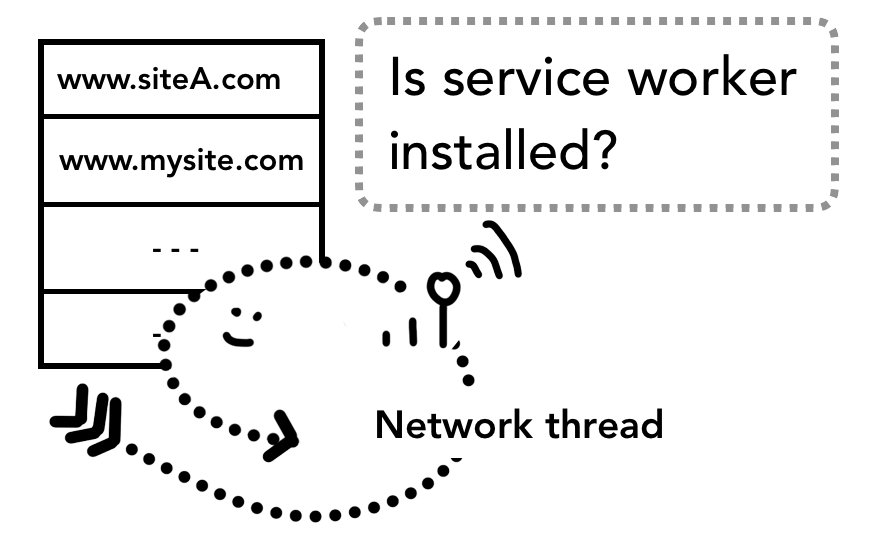
网络线程会在收到导航任务后寻找有没有对应的service worker
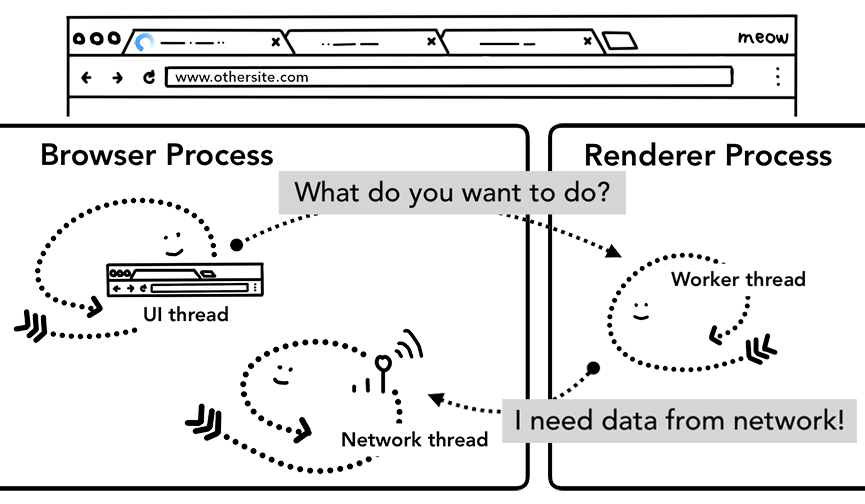
UI线程会启动一个渲染进程来运行找到的service worker代码,代码具体是由渲染进程里面的工作线程(worker thread)执行
导航预加载 - Navigation Preload
在上面的例子中,你应该可以感受到如果启动的service worker最后还是决定发送网络请求的话,浏览器进程和渲染进程这一来一回的通信包括service worker启动的时间其实增加了页面导航的时延。 导航预加载就是一种通过在service worker启动的时候并行加载对应资源的方式来加快整个导航过程效率的技术。预加载资源的请求头会有一些特殊的标志来让服务器决定是发送全新的内容给客户端还是只发送更新了的数据给客户端。
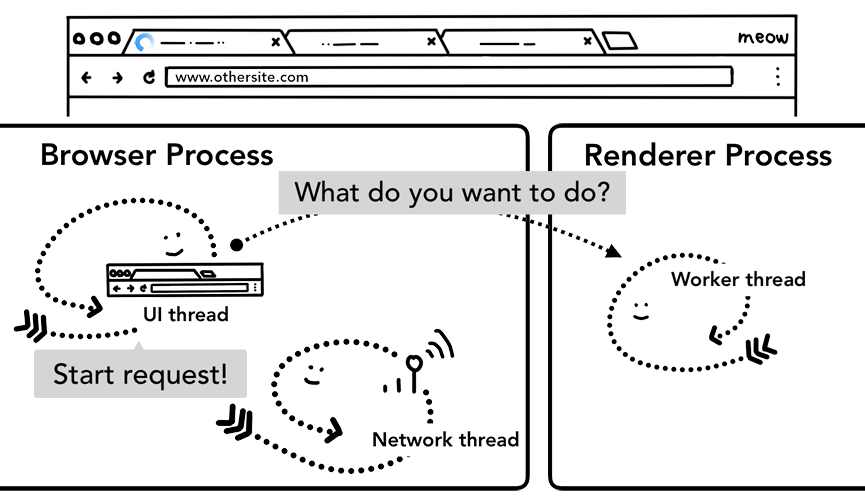
UI线程在启动一个渲染进程去运行service worker代码的同时会并行发送网络请求
渲染进程里面发生的事
了解了导航具体都发生了哪些事情以及浏览器优化导航效率采取的一些技术方案,接着让我们深入了解浏览器的渲染进程是如何解析我们的HTML/CSS/JavaScript来呈现出网页内容的。
渲染进程会影响到Web性能的很多方面。页面渲染的时候发生的东西实在太多了,这里只能作一个大体的介绍。如果你想要了解更多相关的内容, Web Fundamentals的Performance栏目有很多资源可以查看。
渲染进程处理页面内容
渲染进程负责标签(tab)内发生的所有事情。在渲染进程里面,主线程(main thread)处理了绝大多数你发送给用户的代码。如果你使用了web worker或者service worker,相关的代码将会由工作线程(worker thread)处理。合成(compositor)以及光栅(raster)线程运行在渲染进程里面用来高效流畅地渲染出页面内容。
渲染进程的主要任务是将HTML,CSS,以及JavaScript转变为我们可以进程交互的网页内容。
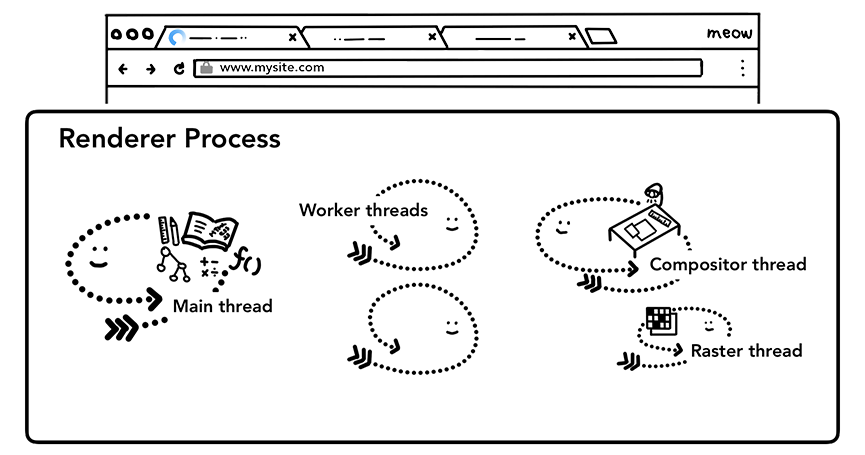
渲染进程里面有:一个主线程(main thread),几个工作线程(worker threads),一个合成线程(compositor thread)以及一个光栅线程(raster thread)
解析
构建DOM
上文提到,渲染进程在导航结束的时候会收到来自浏览器进程提交导航(commit navigation)的消息,在这之后渲染进程就会开始接收HTML数据,同时主线程也会开始解析接收到的文本数据(text string)并把它转化为一个DOM(Document Object Model)对象
DOM对象既是浏览器对当前页面的内部表示,也是Web开发人员通过JavaScript与网页进行交互的数据结构以及API。
如何将HTML文档解析为DOM对象是在 HTML标准中定义的。不过在你的web开发生涯中,你可能从来没有遇到过浏览器在解析HTML的时候发生错误的情景。这是因为浏览器对HTML的错误容忍度很大。举些例子:如果一个段落缺失了闭合p标签(</p>),这个页面还是会被当做为有效的HTML来处理;Hi! <b>I'm <i>Chrome</b>!</i> (闭合b标签写在了闭合i标签的前面) ,虽然有语法错误,不过浏览器会把它处理为Hi! <b>I'm <i>Chrome</i></b><i>!</i>。如果你想知道浏览器是如何对这些错误进行容错处理的,可以参考HTML规范里面的 An introduction to error handling and strange cases in the parser内容。
子资源加载
除了HTML文件,网站通常还会使用到一些诸如图片,CSS样式以及JavaScript脚本等子资源。这些文件会从缓存或者网络上获取。主线程会按照在构建DOM树时遇到各个资源的循序一个接着一个地发起网络请求,可是为了提升效率,浏览器会同时运行“预加载扫描”(preload scanner)程序。如果在HTML文档里面存在诸如<img>或者<link>这样的标签,预加载扫描程序会在HTML解析器生成的token里面找到对应要获取的资源,并把这些要获取的资源告诉浏览器进程里面的网络线程。
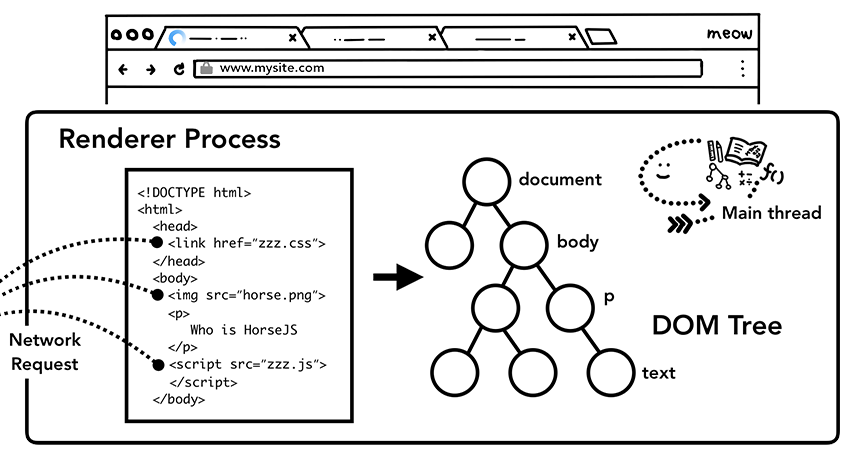
主线程会解析HTML内容并且构建出DOM树
JavaScript会阻塞HTML的解析过程
当HTML解析器碰到script标签的时候,它会停止HTML文档的解析从而转向JavaScript代码的加载,解析以及执行。为什么要这样做呢?因为script标签中的JavaScript可能会使用诸如document.write()这样的代码改变文档流(document)的形状,从而使整个DOM树的结构发生根本性的改变(HTML规范里面的 overview of the parsing model部分有很好的示意图)。因为这个原因,HTML解析器不得不等JavaScript执行完成之后才能继续对HTML文档流的解析工作。如果你想知道JavaScipt的执行过程都发生了什么,V8团队有很多关于这个话题的 讨论以及博客。
给浏览器一点如何加载资源的提示
Web开发者可以通过很多方式告诉浏览器如何才能更加优雅地加载网页需要用到的资源。如果你的JavaScript不会使用到诸如document.write()的方式去改变文档流的内容的话,你可以为script标签添加一个 async或者 defer属性来使JavaScript脚本进行异步加载。当然如果能满足到你的需求,你也可以使用 JavaScript Module。同时<link rel="preload">资源预加载可以用来告诉浏览器这个资源在当前的导航肯定会被用到,你想要尽快加载这个资源。更多相关的内容,你可阅读 Resource Prioritization - Getting the Browser to Help You这篇文章。
样式计算 - Style calculation
拥有了DOM树我们还不足以知道页面的外貌,因为我们通常会为页面的元素设置一些样式。主线程会解析页面的CSS从而确定每个DOM节点的计算样式(computed style)。计算样式是主线程根据CSS样式选择器(CSS selectors)计算出的每个DOM元素应该具备的具体样式,你可以打开devtools来查看每个DOM节点对应的计算样式。
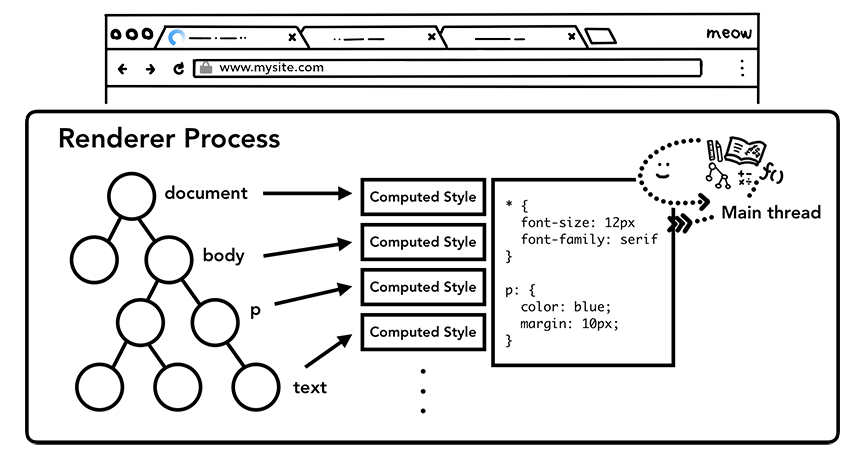
主线程解析CSS来确定每个元素的计算样式
即使你的页面没有设置任何自定义的样式,每个DOM节点还是会有一个计算样式属性,这是因为每个浏览器都有自己的默认样式表。因为这个样式表的存在,页面上的h1标签一定会比h2标签大,而且不同的标签会有不同的magin和padding。如果你想知道Chrome的默认样式是长什么样的,你可以直接查看 代码。
布局 - Layout
前面这些步骤完成之后,渲染进程就已经知道页面的具体文档结构以及每个节点拥有的样式信息了,可是这些信息还是不能最终确定页面的样子。举个例子,假如你现在想通过电话告诉你的朋友你身边的一幅画的内容:“画布上有一个红色的大圆圈和一个蓝色的正方形”,单凭这些信息你的朋友是很难知道这幅画具体是什么样子的,因为他不知道大圆圈和正方形具体在页面的什么位置,是正方形在圆圈前面呢还是圆圈在正方形的前面。
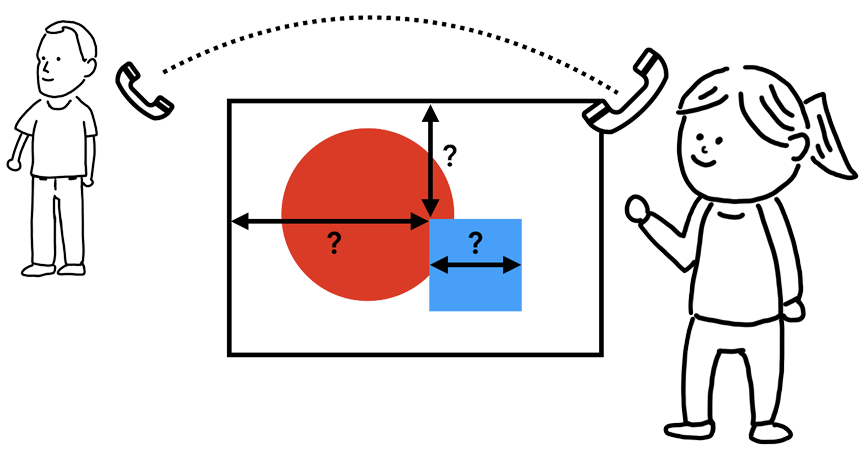
你站在一幅画面前通过电话告诉你朋友画上的内容
渲染网页也是同样的道理,只知道网站的文档流以及每个节点的样式是远远不足以渲染出页面内容的,还需要通过布局(layout)来计算出每个节点的几何信息(geometry)。布局的具体过程是:主线程会遍历刚刚构建的DOM树,根据DOM节点的计算样式计算出一个布局树(layout tree)。布局树上每个节点会有它在页面上的x,y坐标以及盒子大小(bounding box sizes)的具体信息。布局树长得和先前构建的DOM树差不多,不同的是这颗树只有那些可见的(visible)节点信息。举个例子,如果一个节点被设置为了display:none,这个节点就是不可见的就不会出现在布局树上面(visibility:hidden的节点会出现在布局树上面,你可以思考一下这是为什么)。同样的,如果一个伪元素(pseudo class)节点有诸如p::before{content:"Hi!"}这样的内容,它会出现在布局上,而不存在于DOM树上。
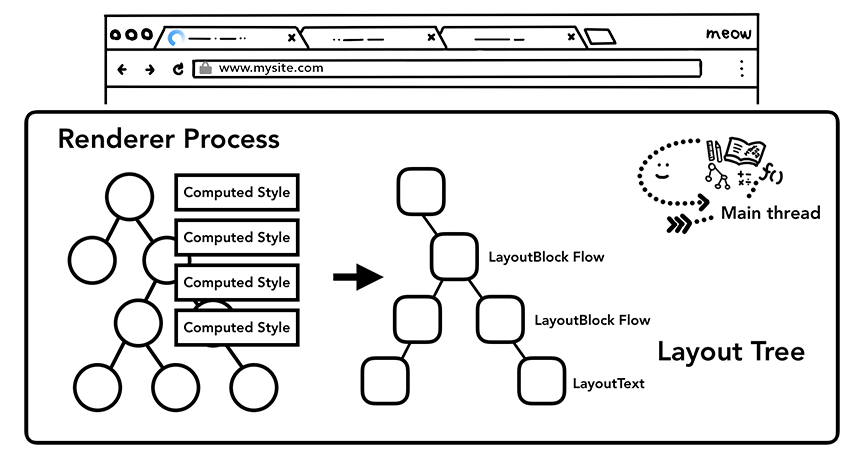
主线程会遍历每个DOM tree节点的计算样式信息来生成一棵布局树
即使页面的布局十分简单,布局这个过程都是非常复杂的。例如页面就是简单地从上而下展示一个又一个段落,这个过程就很复杂,因为你需要考虑段落中的字体大小以及段落在哪里需要进行换行之类的东西,它们都会影响到段落的大小以及形状,继而影响到接下来段落的布局。

浏览器得考虑段落是不是要换行
如果考虑到CSS的话将会更加复杂,因为CSS是一个很强大的东西,它可以让元素悬浮(float)到页面的某一边,还可以遮挡住页面溢出的(overflow)元素,还可以改变内容的书写方向,所以单是想一下你就知道布局这个过程是一个十分艰巨和复杂的任务。对于Chrome浏览器,我们有一整个负责布局过程的工程师团队。如果你想知道他们工作的具体内容,他们在 BlinkOn Conference上面的相关讨论被录制了下来,有时间的话你可以去看一下。
绘画 - Paint
知道了DOM节点以及它的样式和布局其实还是不足以渲染出页面来的。为什么呢?举个例子,假如你现在想对着一幅画画一幅一样的画,你已经知道了画布上每个元素的大小,形状以及位置,你还是得思考一下每个元素的绘画顺序,因为画布上的元素是会互相遮挡的(z-index)。
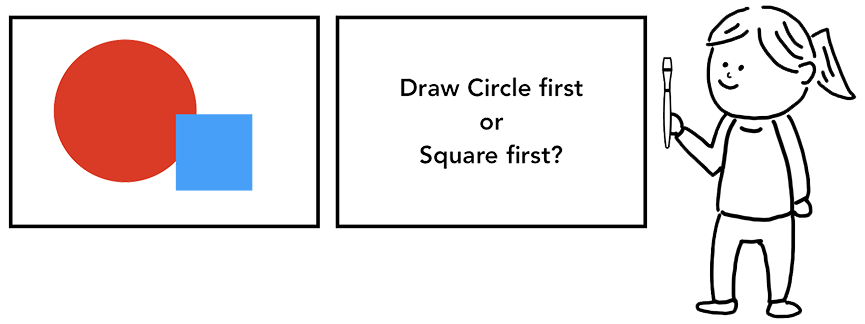
一个人拿着画笔站在画布前面,在思考着是先画一个圆还是先画一个正方形
举个例子,如果页面上的某些元素设置了z-index属性,绘制元素的顺序就会影响到页面的正确性。
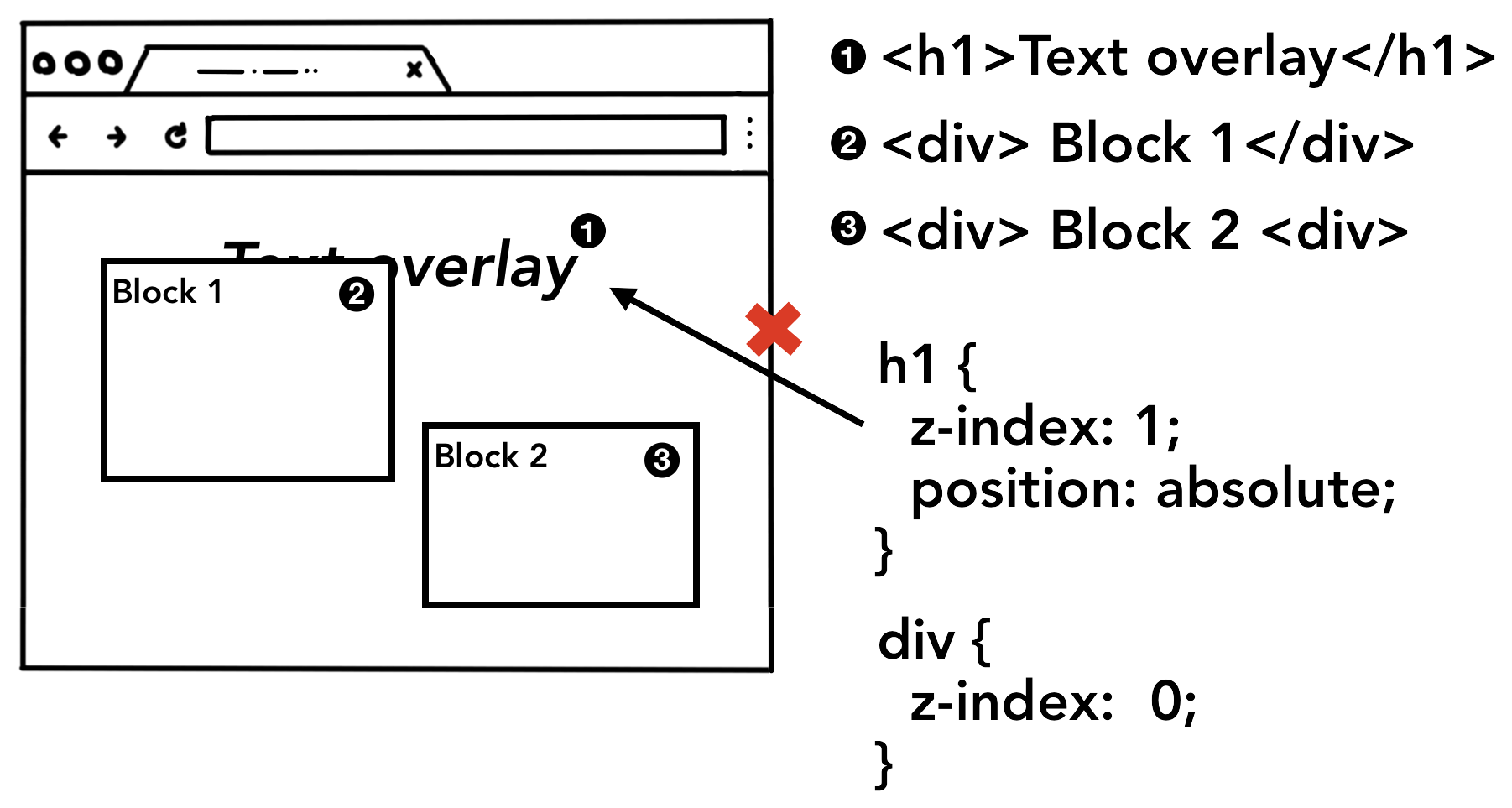
单纯按照HTML布局的顺序绘制页面的元素是错误的,因为元素的z-index元素没有被考虑到
在绘画这个步骤中,主线程会遍历之前得到的布局树(layout tree)来生成一系列的绘画记录(paint records)。绘画记录是对绘画过程的注释,例如“首先画背景,然后是文本,最后画矩形”。如果你曾经在canvas画布上有使用过JavaScript绘制元素,你可能会觉着这个过程不是很陌生。
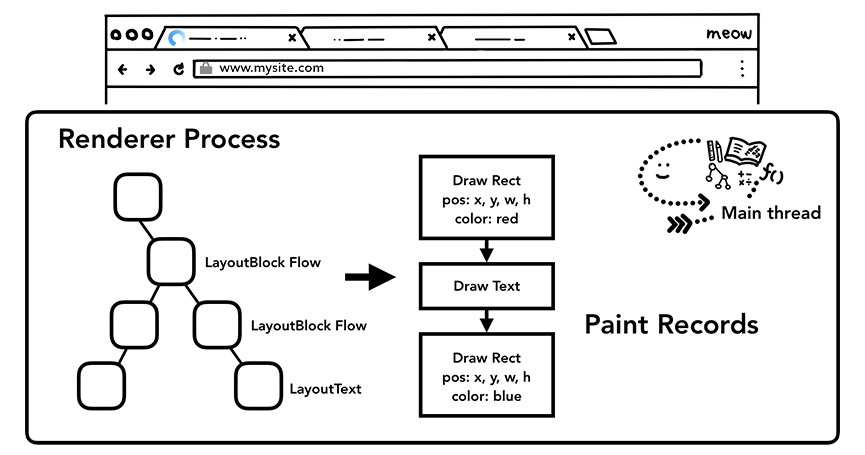
主线程遍历布局树来生成绘画记录
高成本的渲染流水线(rendering pipeline)更新
关于渲染流水线有一个十分重要的点就是流水线的每一步都要使用到前一步的结果来生成新的数据,这就意味着如果某一步的内容发生了改变的话,这一步后面所有的步骤都要被重新执行以生成新的记录。举个例子,如果布局树有些东西被改变了,文档上那些被影响到的部分的绘画顺序是要重新生成的。
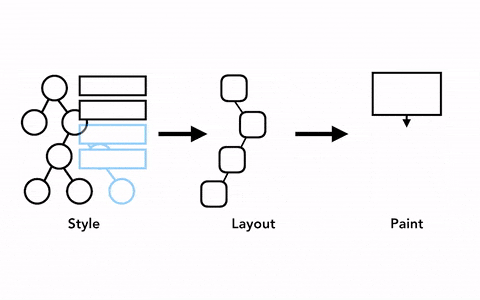
DOM+Style,布局以及绘画树
如果你的页面元素有动画效果(animating),浏览器就不得不在每个渲染帧的间隔中通过渲染流水线来更新页面的元素。我们大多数显示器的刷新频率是一秒钟60次(60fps),如果你在每个渲染帧的间隔都能通过流水线移动元素,人眼就会看到流畅的动画效果。可是如果流水线更新时间比较久,动画存在丢帧的状况的话,页面看起来就会很“卡顿”。
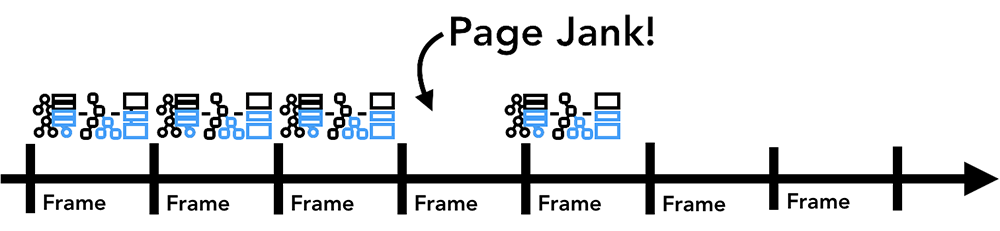
流水线更新没有赶上屏幕刷新,动画就有点卡
即使你的渲染流水线更新是和屏幕的刷新频率保持一致的,这些更新是运行在主线程上面的,这就意味着它可能被同样运行在主线程上面的JavaScript代码阻塞。
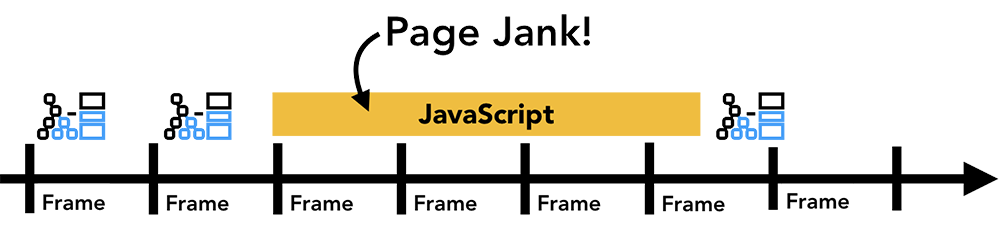
某些动画帧被JavaScript阻塞了
对于这种情况,你可以将要被执行的JavaScript操作拆分为更小的块然后通过requestAnimationFrame这个API把他们放在每个动画帧中执行。想知道更多关于这方面的信息的话,可以参考 Optimize JavaScript Execution。当然你还可以将JavaScript代码放在 WebWorkers中执行来避免它们阻塞主线程。
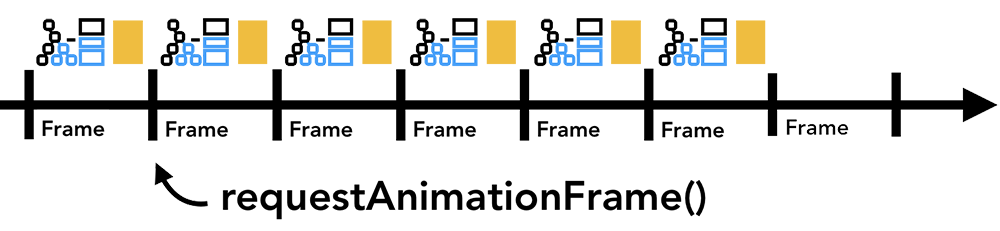
在动画帧上运行一小段JavaScript代码
合成
如何绘制一个页面?
到目前为止,浏览器已经知道了关于页面以下的信息:文档结构,元素的样式,元素的几何信息以及它们的绘画顺序。那么浏览器是如何利用这些信息来绘制出页面来的呢?将以上这些信息转化为显示器的像素的过程叫做光栅化(rasterizing)。
可能一个最简单的做法就是只光栅化视口内(viewport)的网页内容。如果用户进行了页面滚动,就移动光栅帧(rastered frame)并且光栅化更多的内容以补上页面缺失的部分。Chrome的第一个版本其实就是这样做的。然而,对于现代的浏览器来说,它们往往采取一种更加复杂的叫做合成(compositing)的做法。
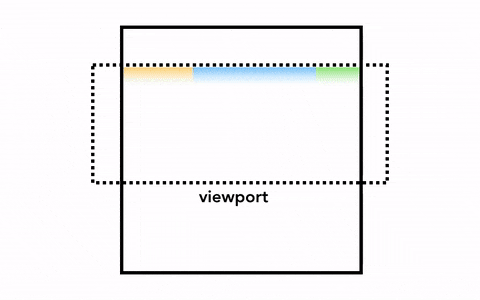
最简单的光栅化过程
什么是合成
合成是一种将页面分成若干层,然后分别对它们进行光栅化,最后在一个单独的线程 - 合成线程(compositor thread)里面合并成一个页面的技术。当用户滚动页面时,由于页面各个层都已经被光栅化了,浏览器需要做的只是合成一个新的帧来展示滚动后的效果罢了。页面的动画效果实现也是类似,将页面上的层进行移动并构建出一个新的帧即可。
你可以通过 Layers panel在DevTools查看你的网站是如何被浏览器分成不同的层的。
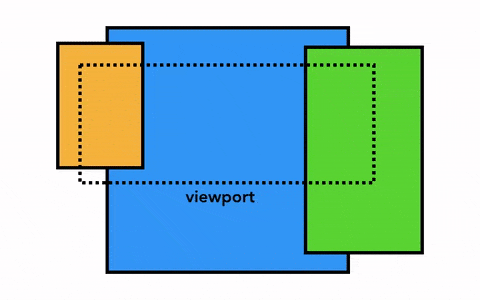
页面合成过程
页面分层
为了确定哪些元素需要放置在哪一层,主线程需要遍历渲染树来创建一棵层次树(Layer Tree)(在DevTools中这一部分工作叫做“Update Layer Tree”)。如果页面的某些部分应该被放置在一个单独的层上面(滑动菜单)可是却没有的话,你可以通过使用will-change CSS属性来告诉浏览器对其分层。
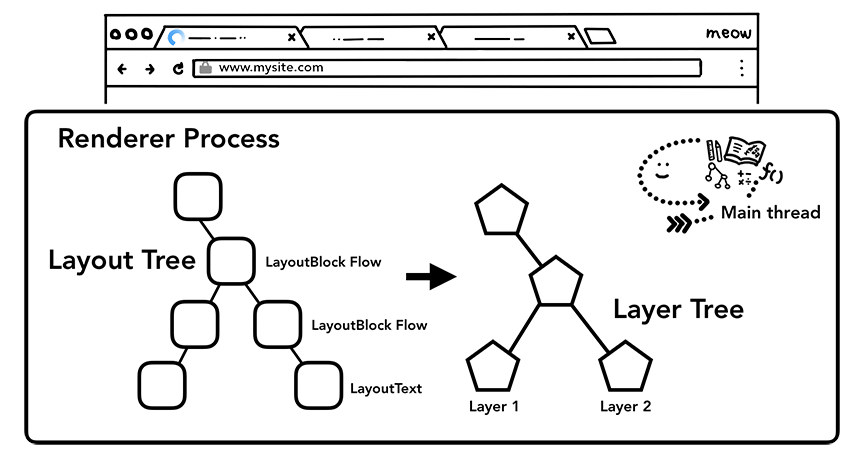
主线程遍历布局树来生成层次树
你可能会想要给页面上所有的元素一个单独的层,然而当页面的层超过一定的数量后,层的合成操作要比在每个帧中光栅化页面的一小部分还要慢,因此衡量你应用的渲染性能是十分重要的一件事情。想要获取关于这方面的更多信息,可以参考文章 Stick to Compositor-Only Properties and Manage Layer Count。
在主线程之外光栅化和合成页面
一旦页面的层次树创建出来并且页面元素的绘制顺序确定后,主线程就会向合成线程(compositor thread)提交这些信息。然后合成线程就会光栅化页面的每一层。因为页面的一层可能有整个网页那么大,所以合成线程需要将它们切分为一块又一块的小图块(tiles)然后将图块发送给一系列光栅线程(raster threads)。光栅线程会栅格化每个图块并且把它们存储在GPU的内存中。
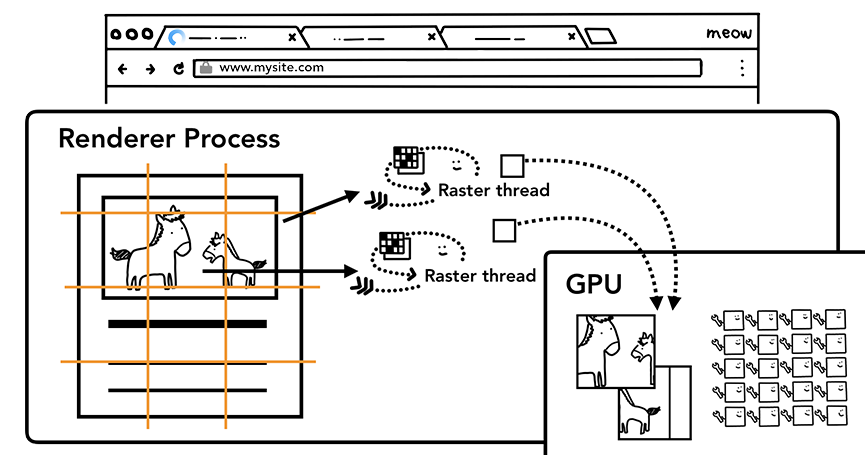
光栅线程创建图块的位图并发送给GPU
合成线程可以给不同的光栅线程赋予不同的优先级(prioritize),进而使那些在视口中的或者视口附近的页面可以先被光栅化。为了响应用户对页面的放大和缩小操作,页面的图层(layer)会为不同的清晰度配备不同的图块。
当图层上面的图块都被栅格化后,合成线程会收集图块上面叫做绘画四边形(draw quads)的信息来构建一个合成帧(compositor frame)。
- 绘画四边形:包含图块在内存的位置以及图层合成后图块在页面的位置之类的信息。
- 合成帧:代表页面一个帧的内容的绘制四边形集合。
上面的步骤完成之后,合成线程就会通过IPC向浏览器进程(browser process)提交(commit)一个渲染帧。这个时候可能有另外一个合成帧被浏览器进程的UI线程(UI thread)提交以改变浏览器的UI。这些合成帧都会被发送给GPU从而展示在屏幕上。如果合成线程收到页面滚动的事件,合成线程会构建另外一个合成帧发送给GPU来更新页面。
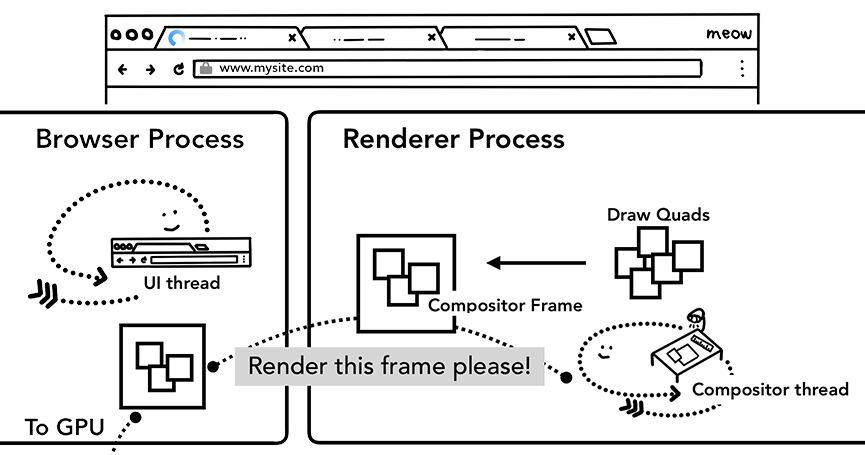
合成线程构建出合成帧,合成帧会被发送给浏览器进程然后再发送给GPU
合成的好处在于这个过程没有涉及到主线程,所以合成线程不需要等待样式的计算以及JavaScript完成执行。这也就是为什么说 只通过合成来构建页面动画是构建流畅用户体验的最佳实践的原因了。如果页面需要被重新布局或者绘制的话,主线程一定会参与进来的。
到达合成线程的输入
了解了渲染进程从解析HTML文件到合成页面整个的渲染流水线后,在接下来剩下的文章内容中,我们将要查看合成线程更多的细节,来了解一下当用户在页面移动鼠标(mouse move)以及进行点击(click)的时候浏览器会做些什么事情。
从浏览器的角度来看输入事件
当你听到“输入事件”(input events)的时候,你可能只会想到用户在文本框中输入内容或者对页面进行了点击操作,可是从浏览器的角度来看的话,输入其实代表着来自于用户的任何手势动作(gesture)。所以用户滚动页面,触碰屏幕以及移动鼠标等操作都可以看作来自于用户的输入事件。
当用户做了一些诸如触碰屏幕的手势动作时,浏览器进程(browser process)是第一个可以接收到这个事件的地方。可是浏览器进程只能知道用户的手势动作发生在什么地方而不知道如何处理,这是因为标签内(tab)的内容是由页面的渲染进程(render process)负责的。因此浏览器进程会将事件的类型(如touchstart)以及坐标(coordinates)发送给渲染进程。为了可以正确地处理这个事件,渲染进程会找到事件的目标对象(target)然后运行这个事件绑定的监听函数(listener)。
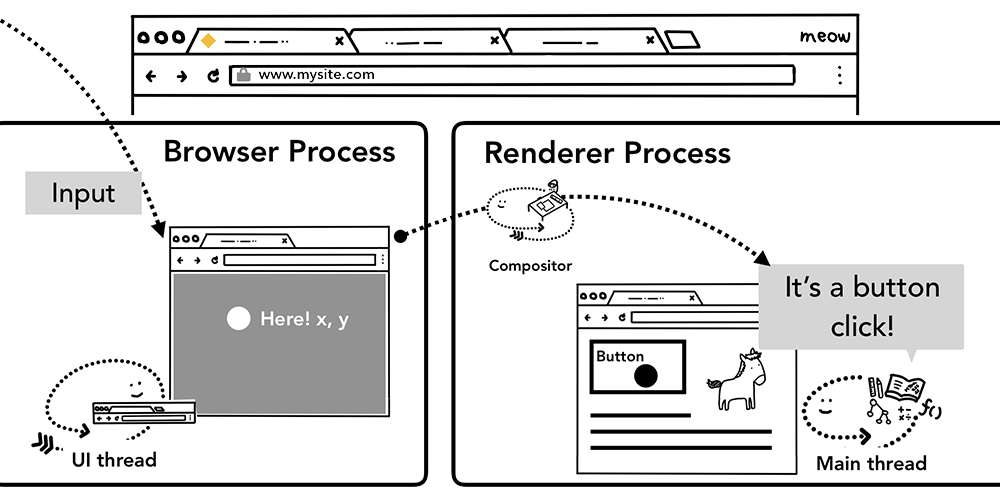
点击事件从浏览器进程路由到渲染进程
合成线程接收到输入事件
在上面的文章中,我们查看了合成线程是如何通过合并页面已经光栅化好的层来保障流畅滚动体验(scroll smoothly)的。如果当前页面不存在任何用户事件的监听器(event listener),合成线程完全不需要主线程的参与就能创建一个新的合成帧来响应事件。可是如果页面有一些事件监听器(event listeners)呢?合成线程是如何判断出这个事件是否需要路由给主线程处理的呢?
了解非快速滚动区域 - non-fast scrollable region
因为页面的JavaScript脚本是在主线程(main thread)中运行的,所以当一个页面被合成的时候,合成线程会将页面那些注册了事件监听器的区域标记为“非快速滚动区域”(Non-fast Scrollable Region)。由于知道了这些信息,当用户事件发生在这些区域时,合成线程会将输入事件发送给主线程来处理。如果输入事件不是发生在非快速滚动区域,合成线程就无须主线程的参与来合成一个新的帧。
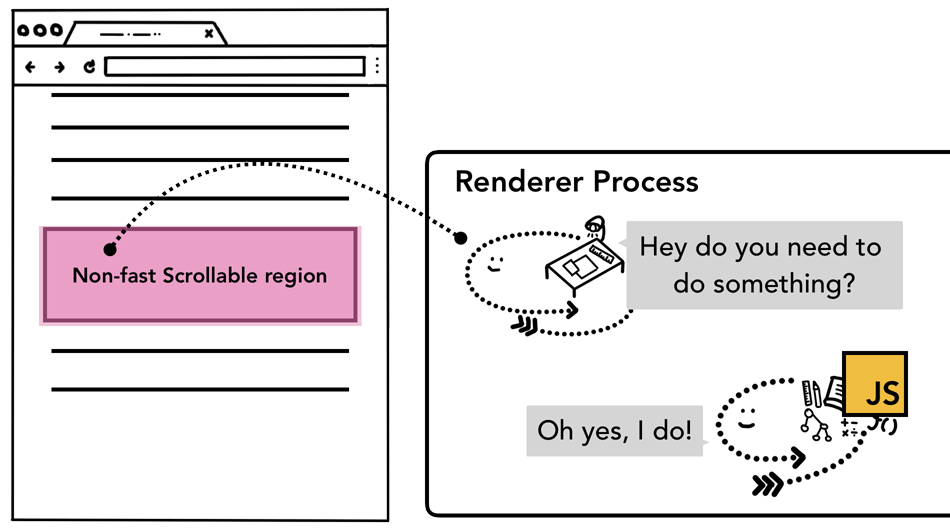
非快速滚动区域有用户事件发生时的示意图
当你写事件监听器的时候留点心眼
Web开发的一个常见的模式是事件委托(event delegation)。由于事件会冒泡,你可以给顶层的元素绑定一个事件监听函数来作为其所有子元素的事件委托者,这样子节点的事件就可以统一被顶层的元素处理了。因此你可能看过或者写过类似于下面的代码:
document.body.addEventListener('touchstart', event => {
if (event.target === area) {
event.preventDefault()
}
})
只用一个事件监听器就可以服务到所有的元素,乍一看这种写法还是挺实惠的。可是,如果你从浏览器的角度去看一下这段代码,你会发现上面给body元素绑定了事件监听器后其实是将整个页面都标记为一个非快速滚动区域,这就意味着即使你页面的某些区域压根就不在乎是不是有用户输入,当用户输入事件发生时,合成线程每次都会告知主线程并且会等待主线程处理完它才干活。因此这种情况下合成线程就丧失提供流畅用户体验的能力了(smooth scrolling ability)。
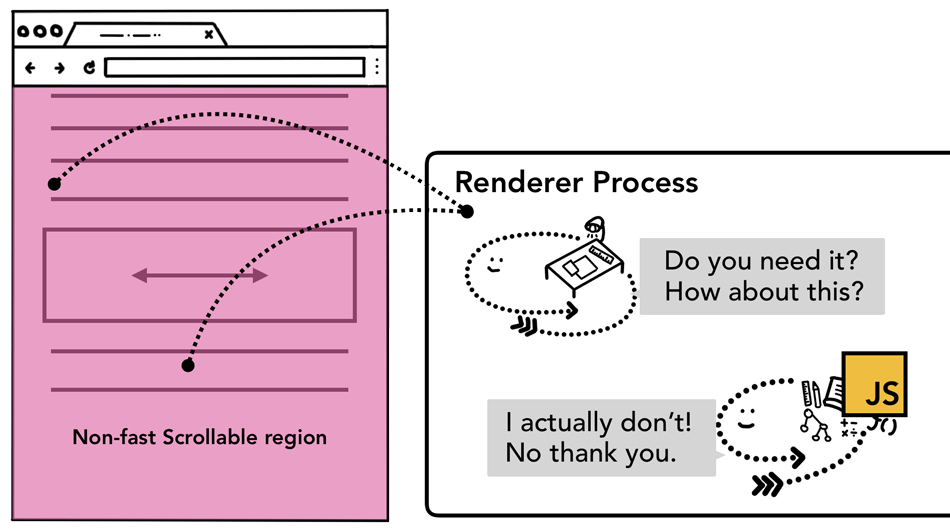
当整个页面都是非快速滚动区域时页面的事件处理示意图
为了减轻这种情况的发生,您可以为事件监听器传递passive:true选项。 这个选项会告诉浏览器您仍要在主线程中侦听事件,可是合成线程也可以继续合成新的帧。
document.body.addEventListener('touchstart', event => {
if (event.target === area) {
event.preventDefault()
}
}, {passive: true});
查找事件的目标对象(event target)
当合成线程向主线程发送输入事件时,主线程要做的第一件事是通过命中测试(hit test)去找到事件的目标对象(target)。具体的命中测试流程是遍历在渲染流水线中生成的绘画记录(paint records)来找到输入事件出现的x, y坐标上面描绘的对象是哪个。
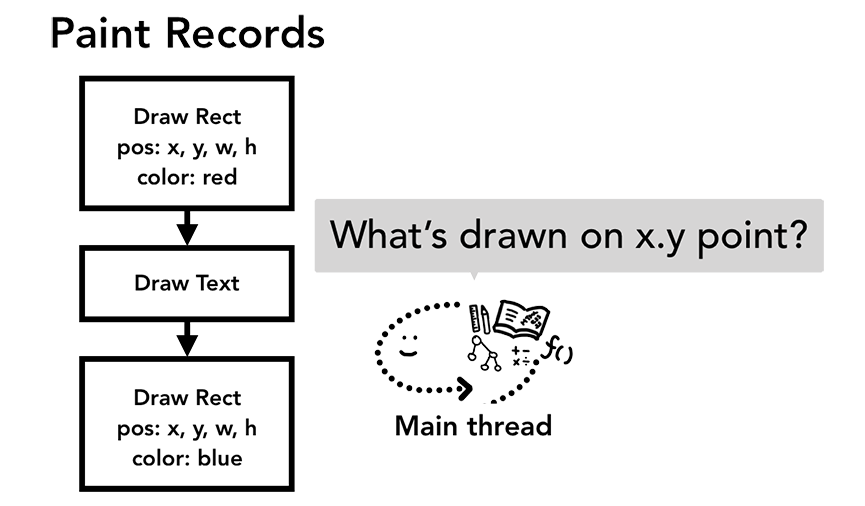
主线程通过遍历绘画记录来确定在x,y坐标上的是哪个对象
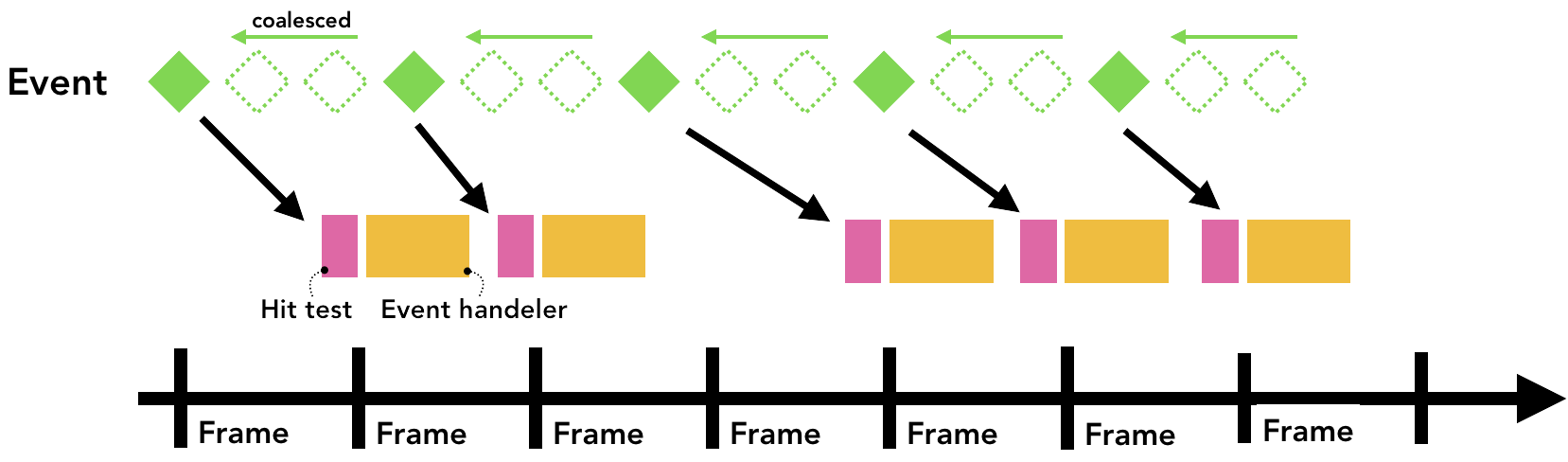
最小化发送给主线程的事件数
在上面的文章中我们有说过显示器的刷新频率通常是一秒钟60次以及我们可以通过让JavaScript代码的执行频率和屏幕刷新频率保持一致来实现页面的平滑动画效果(smooth animation)。对于用户输入来说,触摸屏一般一秒钟会触发60到120次点击事件,而鼠标一般则会每秒触发100次事件,因此输入事件的触发频率其实远远高于我们屏幕的刷新频率。
如果每秒将诸如touchmove这种连续被触发的事件发送到主线程120次,因为屏幕的刷新速度相对来说比较慢,它可能会触发过量的点击测试以及JavaScript代码的执行。
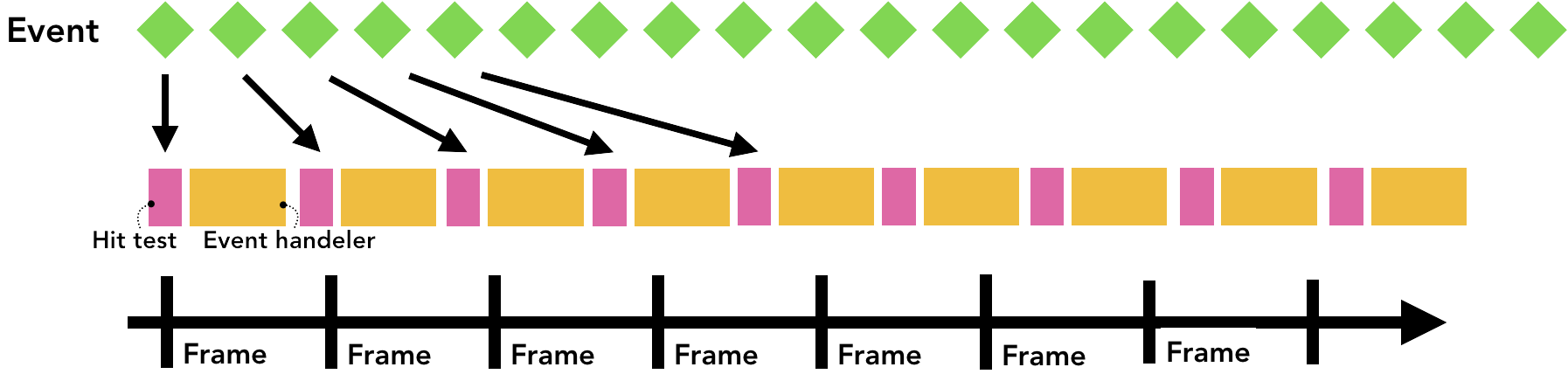
事件淹没了屏幕刷新的时间轴,导致页面很卡顿
为了最大程度地减少对主线程的过多调用,Chrome会合并连续事件(例如wheel,mousewheel,mousemove,pointermove,touchmove),并将调度延迟到下一个requestAnimationFrame之前。
和之前相同的事件轴,可是这次事件被合并并延迟调度了
任何诸如keydown,keyup,mouseup,mousedown,touchstart和touchend等相对不怎么频繁发生的事件都会被立即派送给主线程。
使用getCoalesecedEvents来获取帧内(intra-frame)事件
对于大多数web应用来说,合并事件应该已经足够用来提供很好的用户体验了,然而,如果你正在构建的是一个根据用户的touchmove坐标来进行绘图的应用的话,合并事件可能会使页面画的线不够顺畅和连续。在这种情况下,你可以使用鼠标事件的getCoalescedEvents来获取被合成的事件的详细信息。
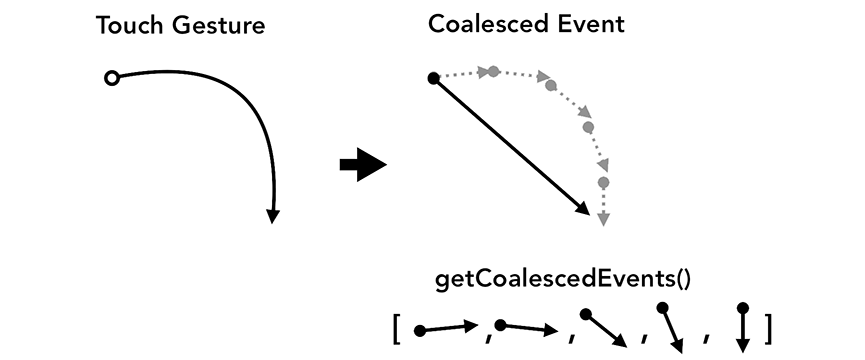
左边是顺畅的触摸手势,右边是事件合成后不那么连续的手势
window.addEventListener('pointermove', event => {
const events = event.getCoalescedEvents();
for (let event of events) {
const x = event.pageX;
const y = event.pageY;
// draw a line using x and y coordinates.
}
});
下一步
在这篇文章中,我们以Chrome浏览器为例子探讨了浏览器的内部工作原理。如果你之前从来没有想过为什么DevTools推荐你在事件监听器中使用passive:true选项或者在script标签中写async属性的话,我希望这篇文章可以给你一些关于浏览器为什么需要这些信息来提供更快更流畅的用户体验的原因。
学习如何衡量性能
不同网站的性能调整可能会有所不同,你要自己衡量自己网站的性能并确定最适合提升你的网站性能的方案。 你可以查看Chrome DevTools团队的一些教程来学习如何才能 衡量自己网站的性能。
为你的站点添加Feature Policy
如果你想更进一步,你可以了解一下 Feature Policy这个新的Web平台功能,这个功能可以在你构建项目的时候提供一些保护让您的应用程序具有某些行为并防止你犯下错误。例如,如果你想确保你的应用代码不会阻塞页面的解析(parsing),你可以在同步脚本策略(synchronius scripts policy)中运行你的应用。具体做法是将sync-script设置为'none',这样那些会阻塞页面解析的JavaScript代码会被禁止执行。这样做的好处是避免你的代码阻塞页面的解析,而且浏览器无须担心解析器(parser)暂停。
持续关注我的技术动态
我是进击的大葱,关注我和我一起进步成独当一面的全栈工程师!
文章首发于: 窥探现代浏览器架构(一)
关注我的个人公众号获取我的最新技术推送!

