程序员应如何理解include
标签: 计算机内功
相信很多同学在学习C/C++后都有这样的疑问,#include这句话到底是怎么意思?这句话的背后隐含了什么?我们常用的stdio.h存放在了哪里?
这篇文章就来解答这个问题。
谁来处理头文件
有上述疑问的同学很可能是因为不熟悉一个叫预编译器(preprocessor)的东西。
让我们简单的了解一下可执行程序的生成过程。
程序员写的大家都可读的代码是不能被CPU直接执行的,CPU可以执行的代码是二进制机器指令,因此一定有某个过程将程序员写的程序转换为了机器指令,这就是编译器。
以上大部分同学应该都知道,但是你知道编译器在将代码翻译成机器指令前其实还有一个步骤吗?这个步骤就是预编译。
那么预编译都用来做什么呢?请注意,接下来是重点:
预编译的工作非常简单,预编译器找到源文件中#include指定的文件,然后copy这些文件的内容并粘贴到#include这一行所在的位置。
假设在源文件a.c的第一行有一句#include <stdio.h>,那么预编译器怎么处理?
预编译找到stdio.h,把stdio.h的内容粘贴到a.c的第一行中。
是不是很简单,完成这一过程后才是编译器的任务。
因此我们知道,原来#include其实是告诉预编译器把指定的头文件内容粘贴到当前include所在的位置,也就是进行文本替换。
头文件是不会被编译的
从上一节中我们知道头文件原来是被预编译器处理的,编译器在编译源文件时拿到的是已经被预编译器处理过后的源文件,因此头文件是不会被编译器直接处理的。
这一点要能意识到。
#include可以被放到代码的任意位置
实际上#include可以出现在代码中的任意一行,只不过我们习惯了在开头使用#include,这是因为变量在声明之前是不能被使用的。
但是我们已经知道了#include其实就是告诉预编译器做一个简单的文本替换,因此任何需要进行文本替换的需求其实都可以通过#include来完成的,记得博主很早在阅读C代码看到#include用作文本替换时大吃一惊,原来#include还可以这样使用,类似这样:
typedef enum {#include <test.h>enum1,enum2,} test_enum;
实际上就是test.h中包含了一系列可以放到enum中的名字而已,预编译器在处理时会把test.h中的内容在这一行展开,这样编译器拿到的就是完整的enum定义了。
如何查看预编译器处理后的文件
一些好奇心强的同学可能会问那我们能不能看到预编译器处理后的文件吗?
答案是可以的。
假设使用的编译器是gcc,那么使用-E选项就可以,-E选项告诉编译器在处理源文件时不要编译、不要汇编和链接,仅预处理。
$ gcc -E test.c使用上述命令就可以看到预处理后的文件是什么样子的。
其它编译器肯定也能找到类似的支持。
两种使用头文件的方式
你一定注意到了,其实#include有两种写法,一种是#include<>;另一种是#include “”,即:
#include <code.h>#include "code.h"
那么这两种使用方法有什么区别吗?
注意,知道这两种用法背后的含义对于程序员来说是非常重要的。
预编译器要想处理头文件首先必须要能找到这个头文件。
如果一个头文件放到了<>中,那么预编译器会在系统头文件所在的路径下开始找,在Linux下这个路径是/usr/include,让我们来看一下/usr/include这个文件夹下都有什么:
我们可以看到这里有很多头文件,注意划红线的位置,原来我们常用的#include<stdio.h>就放在了这里,现在终于解答一个困扰了我们很久的问题。
实际上这里存放的就是标准库头文件,关于标准库参见《 程序员应如何理解标准库》。
接下来就简单了,如果头文件被放到了双引号“”中呢?
很显然只不过就是预编译器搜索路径不再是系统头文件所在路径了,而是以源文件所在位置开始查找,当然不同的编译器策略可能稍有差别。
当在这些路径中找不到include的头文件时就会抛出错误“fatal error: ***.h: No such file or directory”,这是程序员经常遇到的错误,现在你应该知道怎么排查这类问题了吧。
为什么要使用头文件
最后来回答一下为什么的问题,是啊,程序员为什么要使用头文件这种东西呢?
还记得开始学编程时用的经典的HelloWorld程序吗?
#include <stdio.h>int main() {printf("hello world\n");return 0;}
在这段简单的代码中实际上如果我们不使用printf函数打印东西的话根本就不需要stdio.h,那么程序就变成了这样:
int main() {return 0;}
注意该代码不依赖任何头文件,不要怀疑,该代码可以正确的编译运行。
如果程序员愿意的话可以把项目所有实现代码都放到这个文件中,就像这样:
void funA() {...}void funB() {...}int main() {...funA();funB();}
该程序不依赖任何头文件,所有实现代码都放到了一个源文件,而对于现在稍微有规模的软件项目其代码量都在十几万、甚至上百万,你能想象一个包含十几万行代码的源文件是一种怎样的场景吗?
这样的代码有没有可能写出呢?
答案是有的,只要这个项目的程序员对于所有使用到的轮子都从头到尾重复打造一遍,比如自己实现用到的标准库中的函数,比如printf,自己实现各种数据结构等等等等。
而且这样的项目有没有办法维护呢?
答案是有的,重赏之下必有勇夫,只要开出百万年薪必然有人入坑。
因此,我们发现这样写代码不但要重复造轮子还极其难以维护。
所以现在的软件工程一项原则就是复用,能复用其它人的代码绝不会自己重复写一份。
那么问题来了,我们该怎样使用其它人写好的代码呢?
我们该调用哪些函数,这些函数的返回值是什么?参数是什么?
头文件帮程序员解决了上述问题。
头文件里仔仔细细的写好了该模块有哪些函数可供使用者调用、返回值是什么、参数是什么,但头文件中并不会包含实现,这是因为C/C++语言不要求函数的声明和实现必须呆在同一个地方。
因此你会看到,头文件的作用其实是和我们常用的说明书没什么区别。
现在问题就简单了,我们再也不需要一个包含几十万代码的源文件了,程序员可以将其模块化,各个团队负责一个模块,每个模块会编写一些头文件供其它人调用,同时每个模块只写一次,其它团队有需要可以直接使用,最后再把各个模块组合起来,这样大家各司其职又能最大程度实现代码复用。
最后值得注意的一点就是,头文件其实是让编译器知道该怎样生成调用函数的机器指令,而真正将相关代码打包到可执行程序的是 链接器,因此作为程序员不仅需要指定用哪些头文件,还要指定头文件中函数的实现代码,也就是程序员常说的库在哪里。
总结
现在大家应该对头文件有一个全面的认知了吧,原来include只是告诉预编译器在当前位置展开头文件,同时我们也知道了两种include的使用方法及其区别,最后我们了解了为什么要发明头文件这种技术,希望这篇文章能帮你彻底理解头文件。
更多精彩内容,欢迎关注公众号“码农的荒岛求生”。

智能推荐

python学习0809
while True : n=int(input(‘请输入起始值’)) m=int(input(‘请输入终止值’)) if m>n : break else: print(‘输入不规范,请重新输入’) a=[] while True: a.append(int(input(‘请输入公因数,按0停止&rsquo...

在element-ui的table组件与双大括号中使用时间处理函数
需求1:在双大括号中处理时间格式 使用前: 使用前页面效果: 使用后代码: 全局注册过滤器 使用后页面效果: 需求2:在element-ui的table组件中处理时间格式 使用前代码: 使用前页面效果: 使用后代码: 当前组件的methods中 使用后页面效果: 说明:在element-ui的table组件中,自带属性formatter,用来格式化内容 &...
spring cloud 使用sleuth +zipkin 实例测试
最近研究 spring cloud sleuth,这里使用3个应用,sleuth-server,另外就是sleuth-provider和sleuth-consumer, 源码是参考这个兄弟的http://www.cnblogs.com/skyblog/p/6213683.html,但是使用他的源码没有成功,是有问题滴,所以,亲测自己项目, 这是基本的配置,大神勿喷啊,小弟也不才, 直接代码: 1:...
SpringCloud微服务实战之服务消费者Ribbon+RestTemplate
Eureka服务治理体系中有3个核心角色:服务注册中心、服务提供者、服务消费者。spring cloud的服务调用又分为两种方式:ribbon+RestTemplate和feign,本篇主要说的是ribbon+restTemplate方式。 Spring Cloud Ribbon是基于Http和Tcp协议的客户端负载均衡工具,基于Netflix Ribbon实现,它只是一个工具类,不需要独立部署。...
【pytest】pdb 调试
pdb 调试: pdb 是 Python 标准库的调试模块。在 pytest 中,可以直接使用 --pdb 参数在测试失败时开启调试; 直接使用 --pdb 参数: 断言失败,进入 pdb: pdb 提示符出现后,便可以使用 pdb 的交互调试功能,查看错误时,有以下常用命令: &nbs...
猜你喜欢
自动化测试之cucumber.md
一、简介 cucumber是BDD(Behavior-driven development,行为驱动开发)的一个自动化测试的副产品。它使用自然语言来描述测试,使得非程序员可以理解他们。Gherkin是这种自然语言测试的简单语法,而Cucumber是可以执行它们的工具。关于BDD有兴趣自行了解。附cucumber官网链接,里面也有关于BDD的信息。 cucumber本质上是使用根据正则表达式匹配自然...

笨方法学python-1(习题1-5)
继续填坑,按着计划开始看《笨方法学Python》这本书 虽然作者一再强调要按照书来,不要跳节,但是我去年已经基本把python基础知识学完了,虽然学完了但是就放下了没怎么动手实践。继续看这本书主要是想复习并提高一下python的编程能力。所以只是跑例子,还是用python3.6了. 直接 习题一:第一个程序 加分练习 1. 让你的脚本再多打印一行。 加一句print('\n') 2. 让你的脚本只...
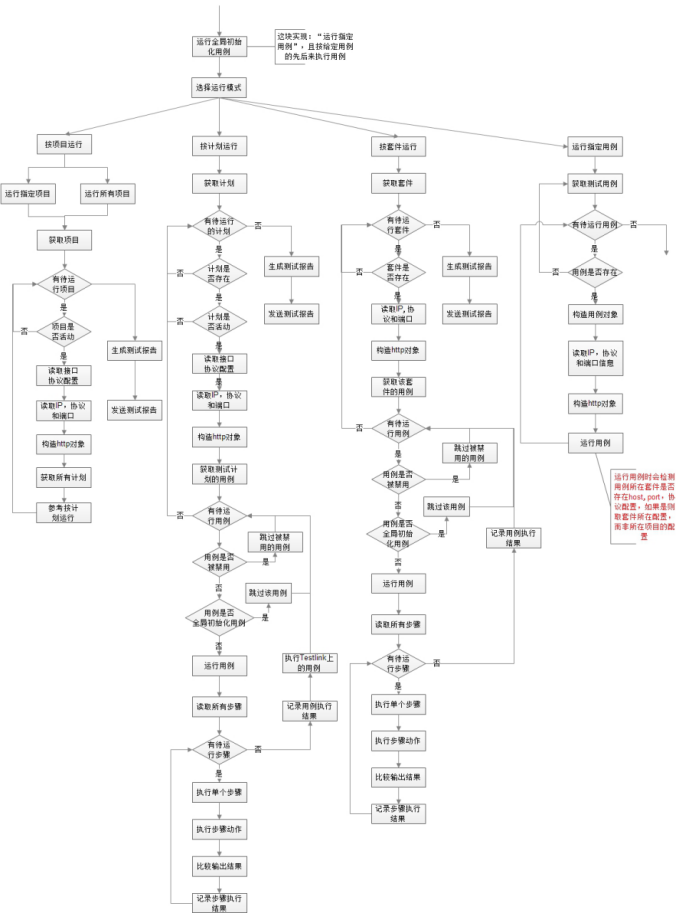
基于python+Testlink+Jenkins实现的接口自动化测试框架V3.0
基于python+Testlink+Jenkins实现的接口自动化测试框架V3.0 目录 1、 开发环境 2、 主要功能逻辑介绍 3、 框架功能简介 4、 数据库的创建 5、 框架模块详细介绍 6、 Testlink相关配置与用例管理 a) API相关配置 b) 项目相关配置 c) 用例管理 ① 步骤动作和预期结果填写规范 ② 参数化 ③ 用例执行依赖 ④ 禁用用例 7、 ...

LeetCode49字母的异位词分组
这题比较巧妙,将字符串中的每个字符赋以hash质数对字符串中的每个值可以乘以对应的质数,若发现最终的乘积结果相等,则字符串为对应的易伟慈分组,利用到hashMap的变相处理方法...

C++练习01 x,y数值的互换
大家刚刚接触C++对其充满好奇,但C++的学习需要大量的敲代码练习,希望大家坚持下去。 今天练习C++中最基础的代码练习:在程序中输入两个变量x,y,然后交换两个变量的值,并输出交换后的值。 数值交换需要借助一个中间变量去z实现,就相当于两个瓶子装满东西,要想东西互换,就需要借助一个空瓶子实现。 以下是此题的答案:...