❝有些厂商说
❞尽量避免挂表验收
,有些公众号只是简单的开箱评测
念数据,那么我们今日技术扶贫
的议题就是教会客户如何挂表验收
,即便没有表,思科ASR1000团队也研发并开源了Trex的打流工具.本文会根据不同的路由器实现告诉用户潜在的风险,帮助用户规避实施过程中的各种潜在风险。
写此文的目的是,作为各种集采测试老司机安全驾驶好多年,但是最近很多年早就转型做预研和协议设计去了,但很多关键的国内外测试又经常要来烦我,我自己已经做腻,干脆写出来,教会同事教会客户,培养一些新人,毕竟我还要更重要的事情要去做。当然也会教会友商,但是最终的目的是让大家都能够在一个理性公平的环境里竞争,各自提升自己的技术实力。
前言
路由器和交换机概述
十多年前各种代理商面试的常见问题就是:请简述7600和GSR1200的区别
,自从7600这个从6500改来的路由器一问世,路由和交换的界限就越来越模糊了,当然利用交换机的大交换矩阵连接多个线卡做分布式路由转发
是一个非常好
的技术,但是混淆 交换带宽
和路由带宽
就不好了,而最近一些年交换机,特别是数据中心交换机的快速发展,已经很多人忘了路由器和交换机的区别了。于是招投标过程中大量的单向、双向带宽、混淆处理能力、虚标流量等情况司空见惯,于是才会诞生尽量避免挂表验收
的话题。
国内另一个现状就是盲目迷信运营商级
路由器,其实很多企业用户
可能在整个路由器生命周期都用不到这么大的吞吐量,最终通常因为一些功能不支持被迫两三年以后又升级成其它的路由器了,或者在广域网上串接各种专用设备,这些专用设备
的短板
进一步限制了大容量路由器的发挥。
交换机测试
通常交换机功能相对简单,虽然多了一些EVPN业务,看上去越来越像路由器了,但大多数功能都是芯片固定的功能实现的,即便是有P4等可编程,性能上各家的差距还是决定于芯片本身,所以招投标过程相对明晰,最多就是挂表打打蛇形流量就能验收。
路由器测试
路由器并不是简单的去看bps
pps
和端口密度
等参数,或者用的什么芯片。路由器测试里面的门道远远高于交换机,即便是相同的芯片,由于不同的算法
转发流程
资源调度
带来的差异影响非常大。例如思科自己的ISR1000-4G路由器可以同时安装收购来的Viptela Vedge
软件或者思科自己的IOS XECedge
,Cedge
软件的转发性能远远高于vEdge
(过段时间空闲一点给大家挂表验收
),这也是为什么思科一定要使用Cedge
替代Vedge
的原因,毕竟几十年对于路由器数据平面的积累在那里。
另一方面是路由器的设计上有大量的保序
、调度
、Buffer设计
、查表引擎
、收敛速度
等多种调度算法的取舍,通常可以使用很诡异的手段去提高普通挂表测试的性能,但是某些业务一上来就性能差的一塌糊涂, 例如某厂家的路由器号称100G
,在一个简单的业务模型
下1G线速都达不到
。
这也是我工作中经常要回答各种客户的问题:“为什么别人家路由器随便1Tbps
,你们ASR1000只有200Gbps
",其实通常路由器放在广域网边缘,用于连接大量的分支机构,业务需求决定了带宽通常几十Gbps可能就够了,但是经常一条MSTP的接口需要承担几百个分支机构的连接,加密
、QoS
、ACL
、防火墙
、语音
、应用识别
、性能评估
等多种功能可能会完全的集中在一个物理接口上并加载数百份给不同的子接口。

思科路由器设计思路
思科设计路由器的思路一开始就是从用户最终的需求出发
的,因为这一多业务系列功能任意一个短板都会带来灾难性的影响,例如使用TCAM查路由表就会导致ACL的容量下降,使用基于端口的队列,可能就是使得真正广域网那一个接口的队列数不够用。所以在很多场景中,思科在企业网路由器系列宁愿使用集中式转发引擎配置多路专用处理器的方式,这是业务模式决定的,它不会像运营商那样可以很轻易的将客户从一个接口迁移到另一条线路上。有时候最远的距离是你看见旁边一个口有QoS队列或者TCAM做ACL,但是你就是没法用到。
路由器测试通常需要考虑大量的问题,我接下来会分多期给大家分享
基本的转发带宽、时延 路由器包调度算法影响 路由表容量和ACL对TCAM的影响 QoS架构 路由邻居、控制面算法 防火墙、NAT等有状态多业务的影响
T-rex测试软件
T-rex测试软件诞生原因
半开玩笑地说就是:地主家也没粮了
,过去路由器测试都是大量购买各种仪表ixia
spirent
厂商的设备,当然思科也有自己的流量测试工具Pagent
,但是ASR1000的那个年代,我们需要大量的去仿真用户的应用,这些行为仿真和防火墙安全测试的需求使得我们又要花费大量的财力去购买很多应用测试设备,例如Spirent avalanche
或IXIA收购的BreakingPoint
等专用应用层测试仪表。恰逢DPDK和通用X86处理器多核心性能越来越强,于是ASR1000的研发团队就开始使用DPDK构建专用的流量测试仪表。最终开源出来回馈给所有的客户https://trex-tgn.cisco.com
当然友商也可以拿去一起配合客户挂表验收
Trex服务器选择
我现在用的是一台自己买的双路工作站, 平时主要是用来写代码和分析数据的,大概整个机器也就两三万的花费,自己掏钱只能省一点花,具体配置清单如下:
| 组件 | 型号 | 备注 |
|---|---|---|
| CPU | Intel Xeon 8259CL*2 | 买的ES版本...穷 |
| 内存 | DDR4-2666 ECC 32GB*12 | |
| 主板 | ASRock EP2C621D12-WS | |
| 网卡 | Mellonax CX5 516A |
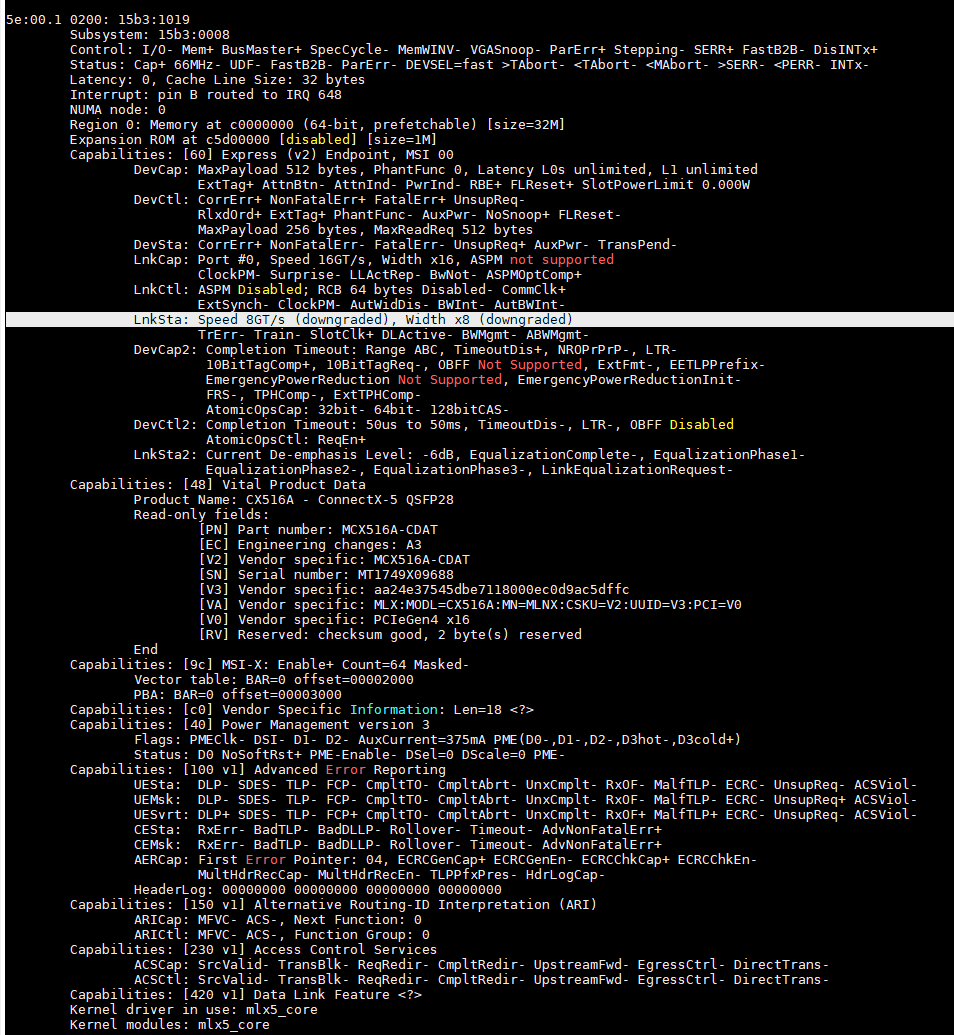
如果真的需要专用于Trex等仪表,建议使用AMD的Roma或者Milan处理器,因为PCIe的lane更多,而且支持PCIe4.0,配合Mellanox CX5或者CX6等PCIe4.0的网卡可以更容易获得单机400Gbps的流量, Intel的处理器通常还要看主板哪条Lane是16X的,因为PCIE3.0x16刚好能产生100Gbps的流量,当你使用了8x的插槽只能打出50Gbps的流量,这一点需要注意。查询的方式如下
[root@Trex ~]# lspci | grep Mell18:00.0 Ethernet controller: Mellanox Technologies MT28800 Family [ConnectX-5 Ex]18:00.1 Ethernet controller: Mellanox Technologies MT28800 Family [ConnectX-5 Ex][root@Trex ~]# lspci -n | grep 18:00.018:00.0 0200: 15b3:1019[root@Trex ~]# lspci -n -d 15b3:1019 -vvv
而内存我的配置能够测到60M并发连接,但是考虑到CPU多核和Hugepage的需求,32G*12的配置有些紧张,如果能上64GB单条的内存会更好,建议配置:
| 组件 | 型号 |
|---|---|
| CPU | AMD Roma Milan 核越多越好 |
| 内存 | 内存带宽和容量都非常重要 |
| 主板 | PCIe 4.0x16插槽越多越好 |
| 网卡 | Mellonax CX5 或者 CX6,建议选择双口的版本 |
Trex安装
操作系统
大多数100Gbps高性能的网卡都是Mellanox家的CX4~6的卡,装ofed驱动又是一件麻烦事,大多数网工也不太熟,而且配合DPDK经常有些小问题,当然最新的Trex 2.88已经很好的支持了ofed 5.2的驱动了,我以后测完了再给大家分享攻略。
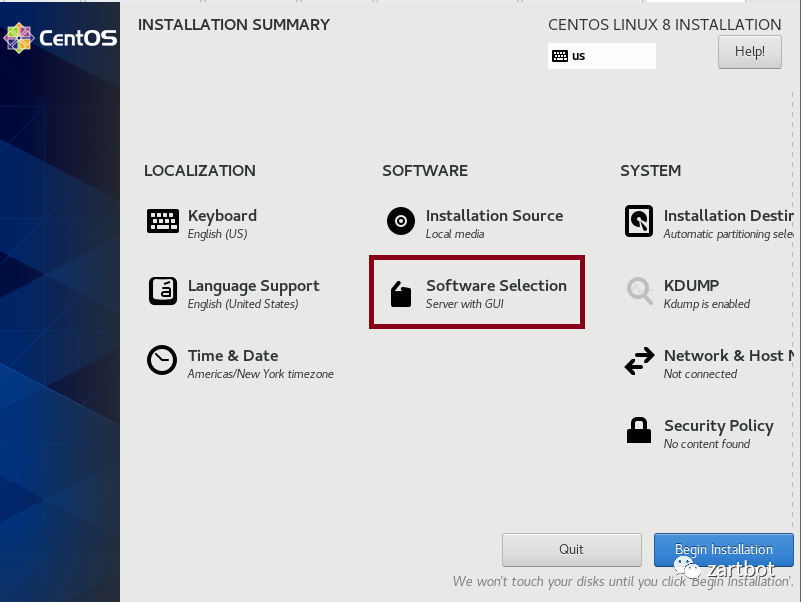
里用一个最简单的办法构建Trex环境,下载并安装CentOS 8
,记得使用那个8G的dvd1选择默认的Server with GUI
,不要最小安装
安装完成后,在国内可能还是切换到阿里的源安装软件会快一点
#备份原有的配置文件
mkdir /etc/yum.repos.d/bak
mv /etc/yum.repos.d/*.repo /etc/yum.repos.d/bak/
#使用阿里云的源覆盖
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-8.repo
yum install -y https://mirrors.aliyun.com/epel/epel-release-latest-8.noarch.rpm
sed -i 's|^#baseurl=https://download.fedoraproject.org/pub|baseurl=https://mirrors.aliyun.com|' /etc/yum.repos.d/epel*
sed -i 's|^metalink|#metalink|' /etc/yum.repos.d/epel*
sudo dnf config-manager --set-enabled PowerTools
yum makecache
yum update
安装Trex
用root登录,首先需要安装RDMA-Core,然后下载Trex解压
yum install rdma-core-devel
cd /opt
wget --no-check-certificate https://trex-tgn.cisco.com/trex/release/v2.86.tar.gz
tar -xzvf v2.86.tar.gz
配置接口
cd v2.86
./dpdk_setup_ports.py -i
下表中选择N,使用IP配置
By default, IP based configuration file will be created. Do you want to use MAC based config? (y/N)N
然后系统会显示已经插入的网卡,注意NUMA的影响,通常一对接口需要分配在相同的NUMA节点才能获得最高的性能。
+----+------+---------+-------------------+-----------------------------------------+-----------+-----------+----------+
| ID | NUMA | PCI | MAC | Name | Driver | Linux IF | Active |
+====+======+=========+===================+=========================================+===========+===========+==========+
| 0 | 0 | 18:00.0 | ec:0d:9a:c5:df:fc | MT28800 Family [ConnectX-5 Ex] | mlx5_core | ens21f0 | |
+----+------+---------+-------------------+-----------------------------------------+-----------+-----------+----------+
| 1 | 0 | 18:00.1 | ec:0d:9a:c5:df:fd | MT28800 Family [ConnectX-5 Ex] | mlx5_core | ens21f1 | |
+----+------+---------+-------------------+-----------------------------------------+-----------+-----------+----------+
| 2 | 0 | 60:00.0 | d0:50:99:f9:48:23 | Ethernet Connection X722 for 1GbE | i40e | enp96s0f0 | |
+----+------+---------+-------------------+-----------------------------------------+-----------+-----------+----------+
| 3 | 0 | 60:00.1 | d0:50:99:f9:48:24 | Ethernet Connection X722 for 1GbE | i40e | enp96s0f1 | *Active* |
+----+------+---------+-------------------+-----------------------------------------+-----------+-----------+----------+
| 4 | 0 | 60:00.2 | d0:50:99:f9:48:25 | Ethernet Connection X722 for 1GbE | i40e | enp96s0f2 | |
+----+------+---------+-------------------+-----------------------------------------+-----------+-----------+----------+
| 5 | 0 | 60:00.3 | d0:50:99:f9:48:26 | Ethernet Connection X722 for 1GbE | i40e | enp96s0f3 | |
+----+------+---------+-------------------+-----------------------------------------+-----------+-----------+----------+
| 6 | 1 | 86:00.0 | 3c:fd:fe:a9:a8:88 | Ethernet Controller X710 for 10GbE SFP+ | i40e | ens17f0 | |
+----+------+---------+-------------------+-----------------------------------------+-----------+-----------+----------+
| 7 | 1 | 86:00.1 | 3c:fd:fe:a9:a8:89 | Ethernet Controller X710 for 10GbE SFP+ | i40e | ens17f1 | |
+----+------+---------+-------------------+-----------------------------------------+-----------+-----------+----------+
| 8 | 1 | 86:00.2 | 3c:fd:fe:a9:a8:8a | Ethernet Controller X710 for 10GbE SFP+ | i40e | ens17f2 | |
+----+------+---------+-------------------+-----------------------------------------+-----------+-----------+----------+
| 9 | 1 | 86:00.3 | 3c:fd:fe:a9:a8:8b | Ethernet Controller X710 for 10GbE SFP+ | i40e | ens17f3 | |
+----+------+---------+-------------------+-----------------------------------------+-----------+-----------+----------+
Please choose even number of interfaces from the list above, either by ID , PCI or Linux IF
Stateful will use order of interfaces: Client1 Server1 Client2 Server2 etc. for flows.
Stateless can be in any order.
For performance, try to choose each pair of interfaces to be on the same NUMA.
Enter list of interfaces separated by space (for example: 1 3) :
Trex要求网卡按对配置, 例如第一对,我们选择了 0 1
这对卡,然后配置完后,会要求您修改IP地址,如下
or performance, try to choose each pair of interfaces to be on the same NUMA.
Enter list of interfaces separated by space (for example: 1 3) : 0 1 '<-input'
For interface 0, assuming loopback to its dual interface 1.
Putting IP 1.1.1.1, default gw 2.2.2.2 Change it?(y/N).y '<-input'
Please enter IP address for interface 0: 1.1.1.2
Please enter default gateway for interface 0: 1.1.1.1
For interface 1, assuming loopback to its dual interface 0.
Putting IP 2.2.2.2, default gw 1.1.1.1 Change it?(y/N). y '<-input'
Please enter IP address for interface 1: 2.2.2.2
Please enter default gateway for interface 1: 2.2.2.1
Print preview of generated config? (Y/n)Y
### Config file generated by dpdk_setup_ports.py ###
- version: 2
interfaces: ['18:00.0', '18:00.1']
port_info:
- ip: 1.1.1.2
default_gw: 1.1.1.1
- ip: 2.2.2.2
default_gw: 2.2.2.1
platform:
master_thread_id: 0
latency_thread_id: 24
dual_if:
- socket: 0
threads: [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63]
Save the config to file? (Y/n) Y '<-input'
Default filename is /etc/trex_cfg.yaml
Press ENTER to confirm or enter new file:
File /etc/trex_cfg.yaml already exist, overwrite? (y/N)y '<-input'
Saved to /etc/trex_cfg.yaml.
安装stateless GUI
安装JRE和GUI软件
#安装jre,注意选择Oracle的JRE,不要选择OpenJDK
#去Oracle下载jre-8u261-linux-x64.rpm
rpm -ivh jre-8u261-linux-x64.rpm
在github下载Stateless GUI
https://github.com/cisco-system-traffic-generator/trex-stateless-gui/releases
mkdir trexUI
cd trexUI/
tar vzxf ../trex-stateless-gui-v4.5.6.tgz
Trex技巧
和商用的测试仪表自然还是有一些差距的,主要是在一些延迟测量上和流量产生的稳定性上受到DPDK和X86平台本身的影响,可能在一些测试时延乱序或者QoS的场景下会出现一些偏差,通常我们的做法是用Trex的100G接口产生大量的背景流量,然后采用IXIA或者Spirent相对便宜的千兆或者万兆接口来做,当然如果条件有限,实在无法配置仪表,也可以建议厂商配置可以打精确时间戳的镜像交换机来测试,例如我们接下来的组播等测试场景会采用Cisco Nexus 93180FX,通过ERSPAN镜像流量的时候硬件打上时间戳来比对不同接口的延迟。这个例子我们下一期再详细叙述。
挂表验收:)
被测设备
本次测试的是一个ASR1000中端平台,ASR1009X ESP100 RP3,挂接了多个MIP100线卡。
ASR1009X#sh platform
Chassis type: ASR1009-X
Slot Type State Insert time (ago)
--------- ------------------- --------------------- -----------------
0 ASR1000-MIP100 ok 01:48:24
0/0 EPA-10X10GE ok 01:46:15
0/1 EPA-1X100GE ok 01:46:05
1 ASR1000-MIP100 ok 01:48:24
1/0 EPA-10X10GE ok 01:46:18
1/1 EPA-QSFP-1X100GE ok 01:46:08
2 ASR1000-MIP100 ok 01:48:24
2/0 EPA-10X10GE ok 01:46:18
2/1 EPA-QSFP-1X100GE ok 01:46:07
R0 ASR1000-RP3 ok, active 01:48:24
F1 ASR1000-ESP100 ok, active 01:48:24
P0 Unknown empty never
P1 Unknown empty never
P2 Unknown empty never
P3 Unknown empty never
P4 ASR1000X-AC-1100W ok 01:47:14
P5 ASR1000X-AC-1100W ok 01:47:11
P6 ASR1000X-FAN ok 01:46:56
P7 ASR1000X-FAN ok 01:46:55
P8 ASR1000X-FAN ok 01:46:58
吞吐量测试
作弊手段1:板内转发
通常有些厂商会有线卡内部的本地交换芯片,而背板带宽可能有限,因此测试的时候通常这些厂商会不老实把测试仪的线接在同一块线卡的不同端口上,企图用本地交换蒙混过关。或者利用三层交换板卡蒙骗路由性能。
客户验收一定要要求:
❝请厂商标注
❞交换型线卡
和路由型线卡
型号,并陈述转发架构,测试仪表必须使用跨卡转发
连接
正规配置
所以本次测试,我们按照需求配置1号MIP线卡的1/1/0 100G接口和2号MIP线卡的2/1/0 100G接口进行流量测试,以前就是直连地址打就行了,但是有一些厂商针对集采测试有本地直连网段不会查路由表
的优化,那么加上一条静态路由规避此类优化
当然我们也可以注入几百万路由来玩玩~ 具体留到后续的控制面测试文章中给大家介绍注入路由和快速收敛上各家的缺陷。
interface HundredGigE1/1/0
ip address 1.1.1.1 255.255.255.0
!
interface HundredGigE2/1/0
ip address 2.2.2.1 255.255.255.0
!
ip route 16.0.0.0 255.0.0.0 1.1.1.2
ip route 48.0.0.0 255.0.0.0 2.2.2.2
Trex打流
启用Trex后台进程, 注意-C参数跟您的CPU核心数有关,例如我的Intel Xeon 8259L单个CPU有24个Core,通常做法是采用比物理核心少一个的方式,例如-C 23
cd /opt/v2.86
./t-rex-64 --no-ofed-check -i -c 23
启动后Terminal会有一个TUI
-Per port stats table
ports | 0 | 1
-----------------------------------------------------------------------------------------
opackets | 0 | 0
obytes | 0 | 0
ipackets | 281 | 189
ibytes | 63127 | 13290
ierrors | 0 | 0
oerrors | 0 | 0
Tx Bw | 0.00 bps | 0.00 bps
-Global stats enabled
Cpu Utilization : 0.0 %
Platform_factor : 1.0
Total-Tx : 0.00 bps
Total-Rx : 1.20 Kbps
Total-PPS : 0.00 pps
Total-CPS : 0.00 cps
Expected-PPS : 0.00 pps
Expected-CPS : 0.00 cps
Expected-BPS : 0.00 bps
Active-flows : 0 Clients : 0 Socket-util : 0.0000 %
Open-flows : 0 Servers : 0 Socket : 0 Socket/Clients : -nan
drop-rate : 0.00 bps
current time : 370.2 sec
test duration : 0.0 sec
然后另开一个窗口,启用stateless gui, 我使用MobaXterm可以重定向到windows上,蛮有用的.
cd /opt/trexUI/
./trex-stateless-gui
点击File
->Connect
选择连接本机127.0.0.1
--pic---Trex-Connect.png
您可以看到如下的一些接口和CPU等信息:
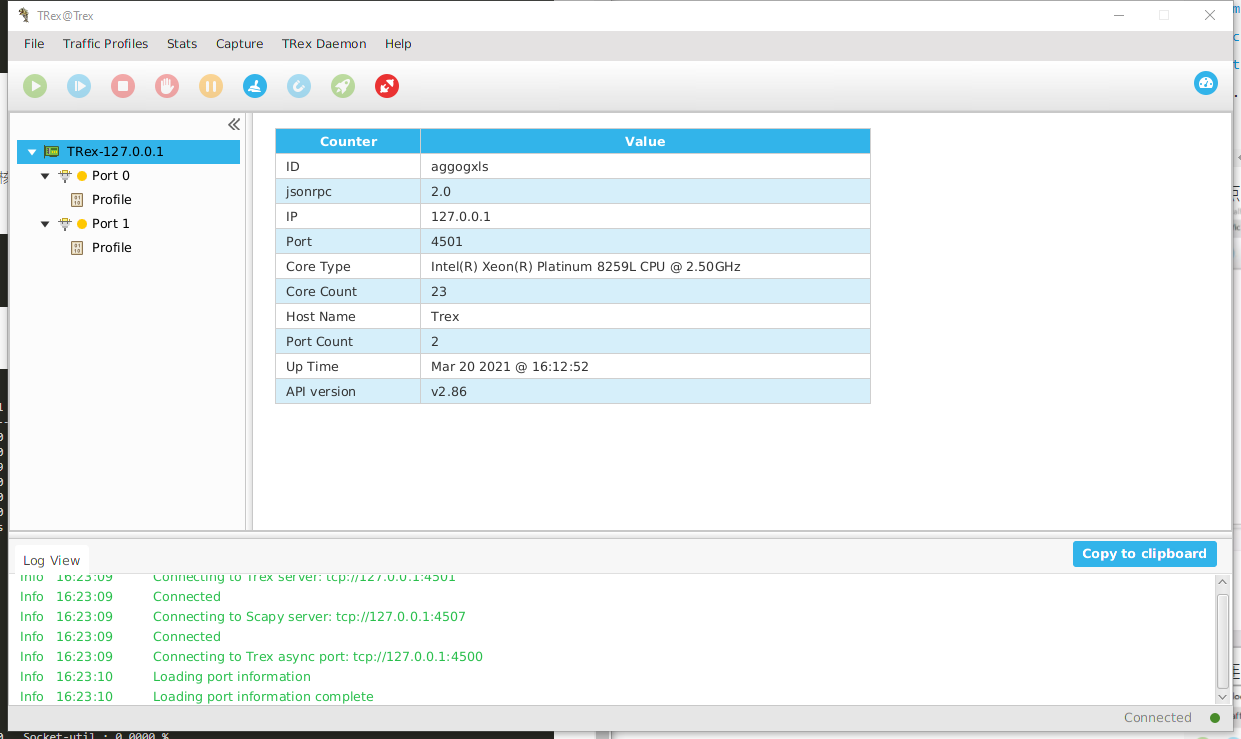
可以选择这些接口点击右键Acquire
使用该接口,

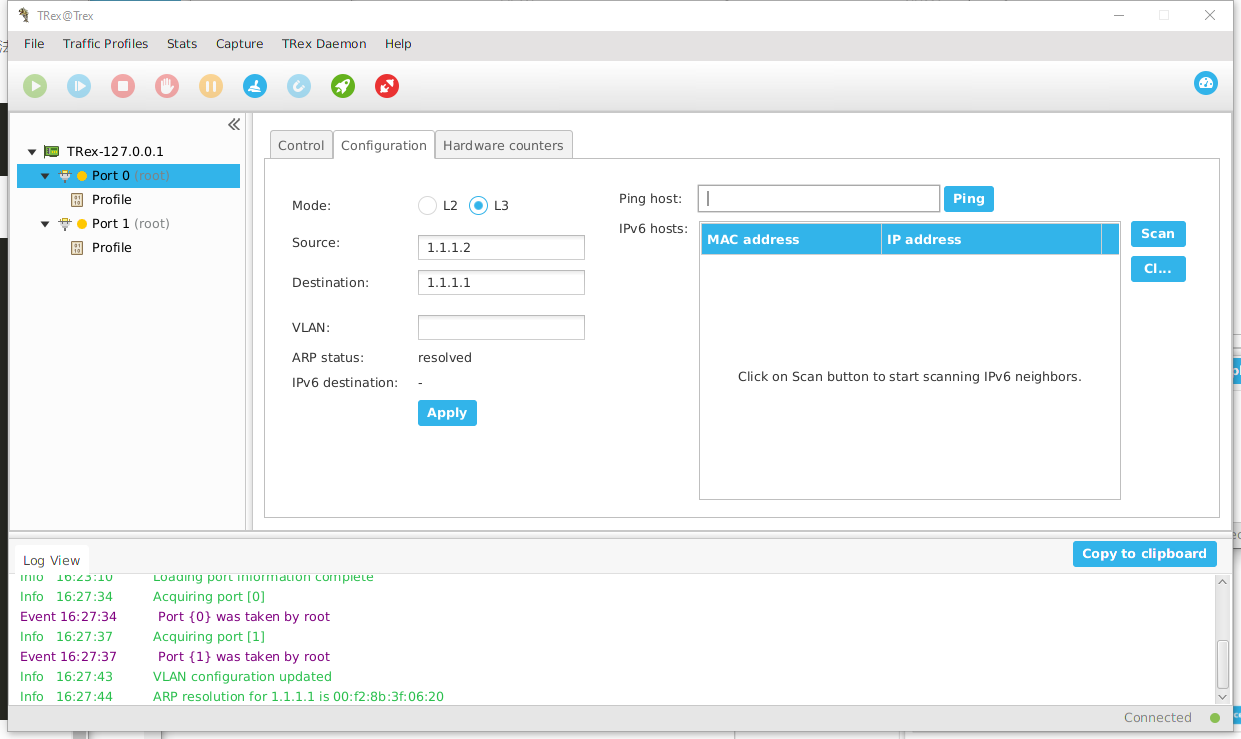
然后点击Configuration
子页,配置Source、Destination IP地址并点击Apply获取ASR1000网关的MAC地址。两个端口都要做。
点击Trex主界面中的Traffic Profiles
菜单,然后我们来创建流量模型

点击Create Profile
可以创建,我们需要为Port0
和Port1
创建各自的Profile

以Port0
为例,我们点击右侧Build Stream
,Stream Name随意就好,然后选择左下角Simple mode
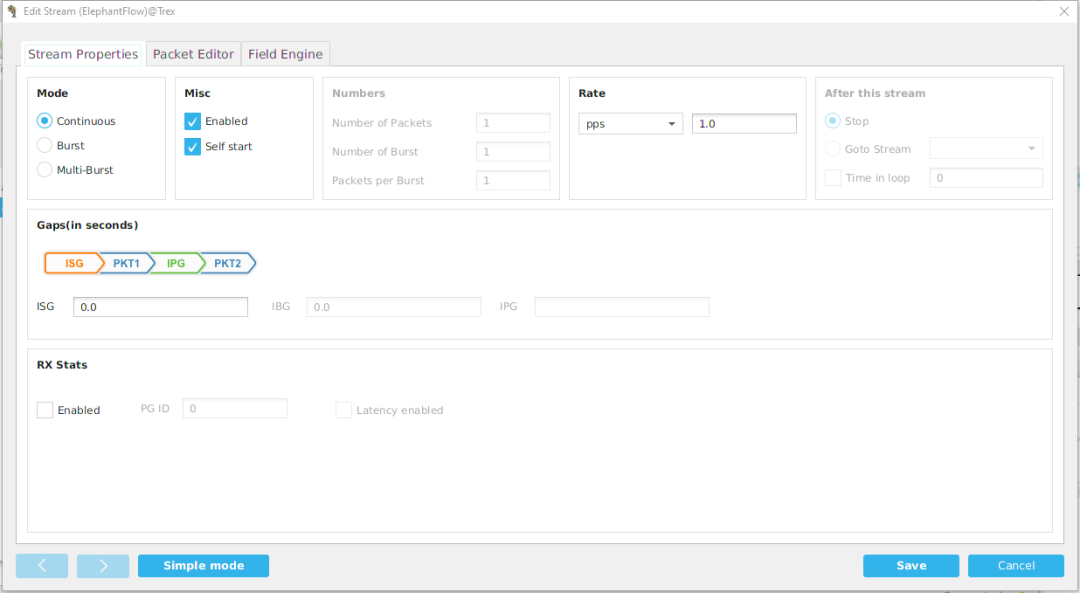
在Protocol Selection
页面选择包大小,因为我们第一个Case是测试最大pps,因此包大小采用Fixed
64
,L4协议选择UDP
,如下图所示:
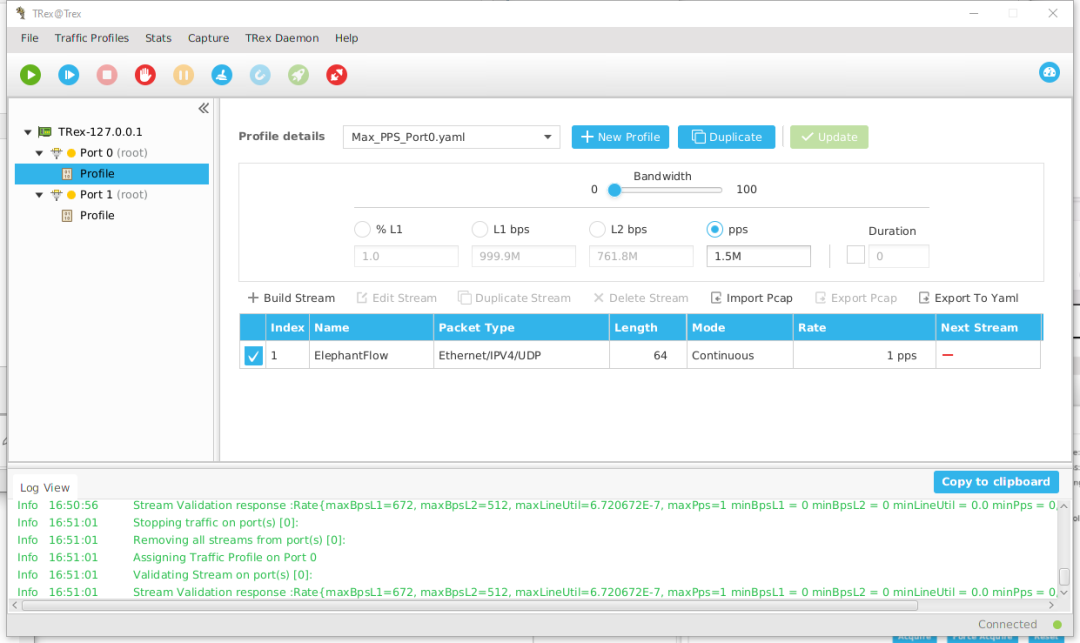
继续点击Protocol Data
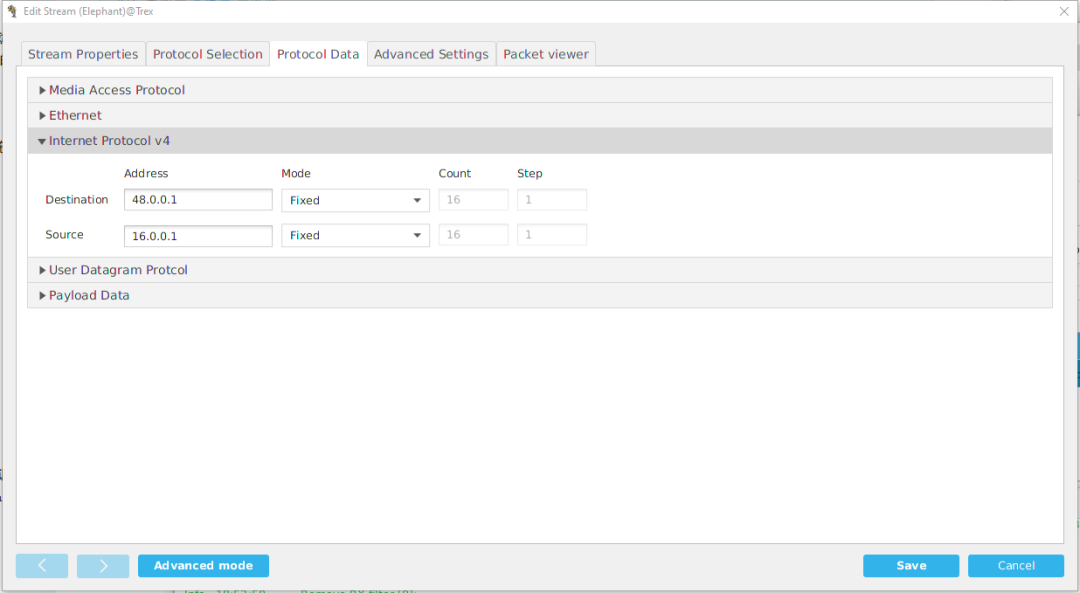
页, 选择Internet Protocol v4
选项,根据我们前面配的路由表选择源目的地址,Mode为Random
各16个,
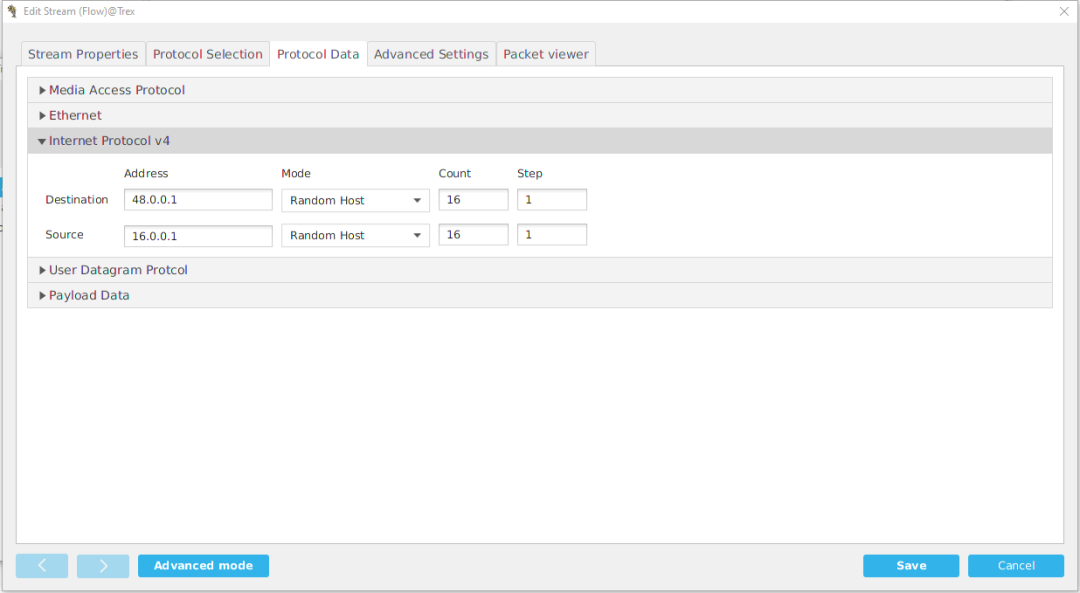
点击Save
, 同样Port1
的Profile再建立一个反向的流。
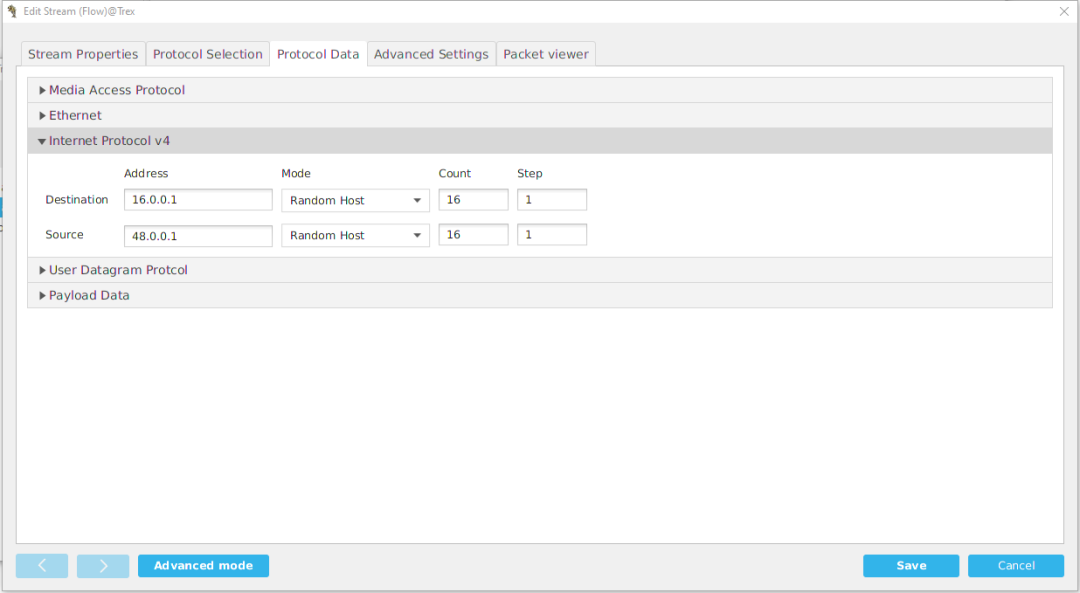 然后我们关闭
然后我们关闭Traffic Profiles
窗口,点击Port0和Port1下的Profile
页面,选择相应的Profile就好
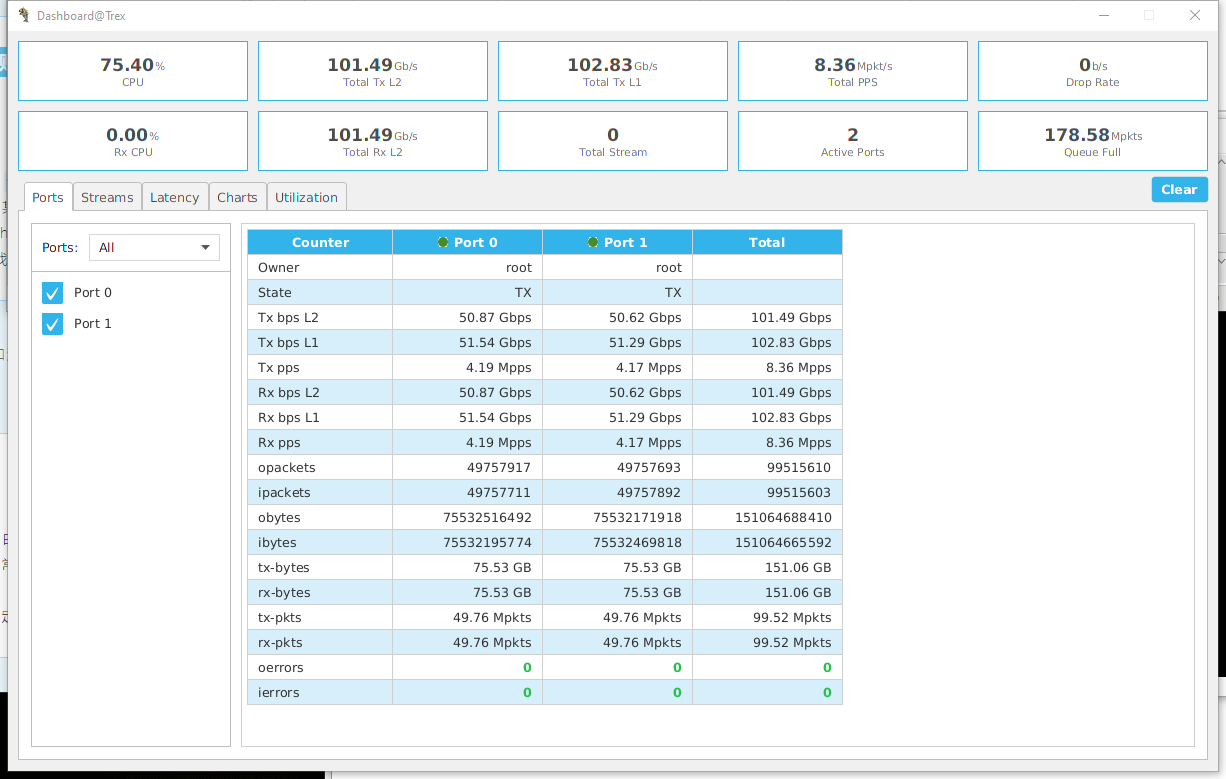
然后ASR1000 ESP100官方性能为78Mpps,最后我们极限测试发现可以到79Mpps,因此最后我们决定一个口增加到40Mpps,另一个口为39Mpps。
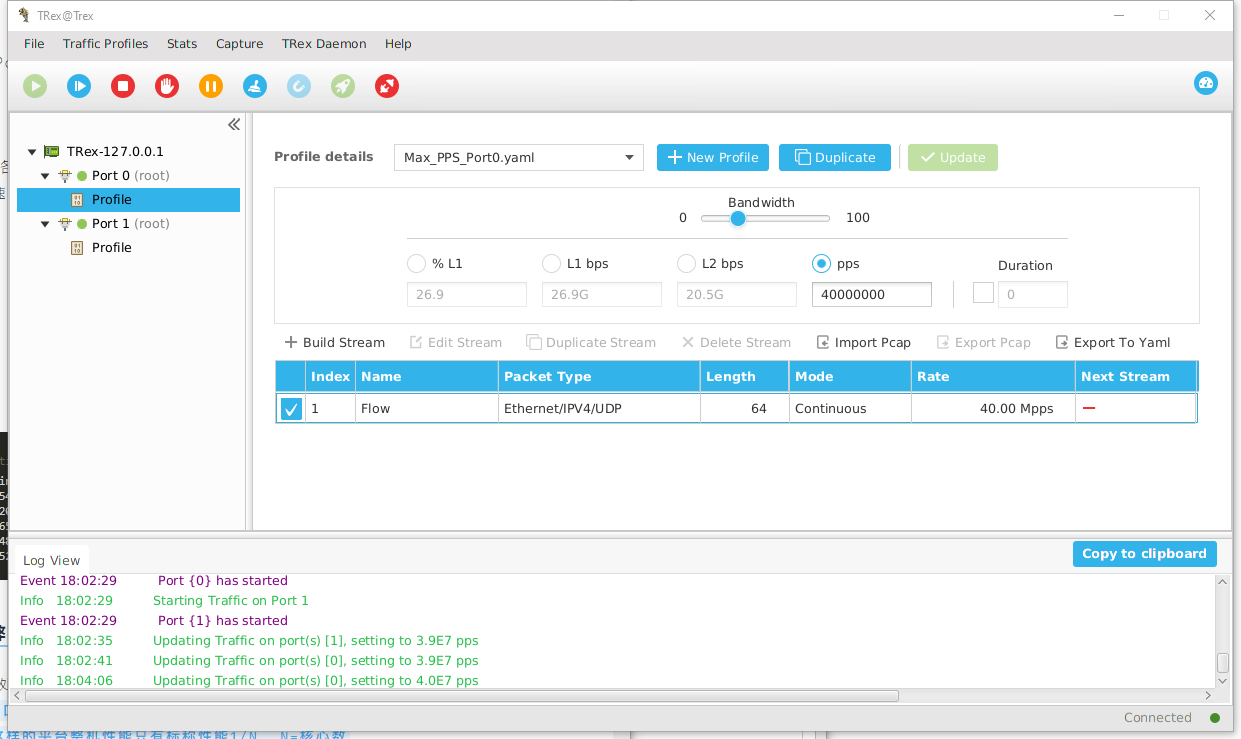
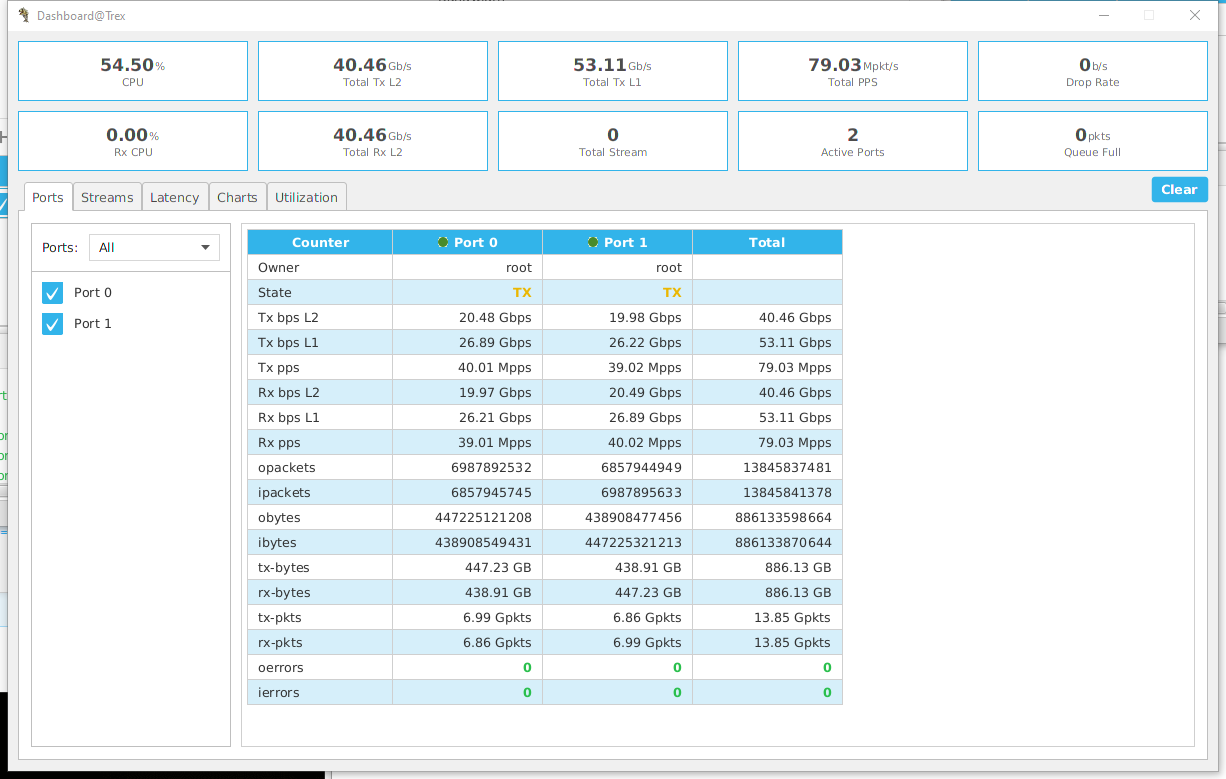
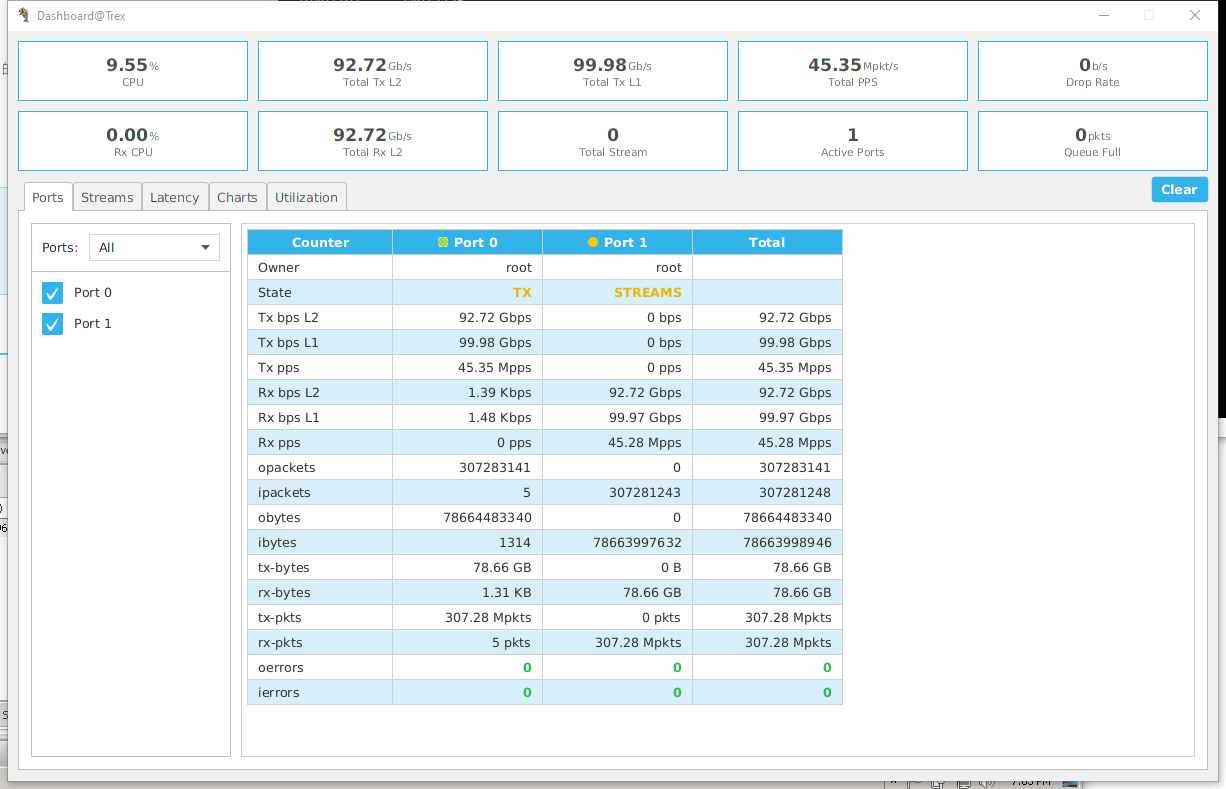
点击Stats
->Dashboard
就可以看见流量的统计了,居然比官方值还高了1Mpps,其实我们对外公布的值都会和峰值之间留一些余量的:
同时您也可以在ASR1000上使用如下命令确认,可以看到这个平台ESP100有两块处理器CPP 0:subdev 0
和CPP 0:subdev 1
流量很均匀的被调度到了两个处理器上,每块39.5Mpps左右。输出的pps为79003661,此时处理还有1%可以往上打:)
ASR1009X#show platform hardware qfp active datapath utilization
CPP 0: Subdev 0 5 secs 1 min 5 min 60 min
Input: Priority (pps) 0 0 0 0
(bps) 0 104 96 16
Non-Priority (pps) 39502943 39502601 38277679 5149335
(bps) 22121648768 22121457768 21435501416 2883627808
Total (pps) 39502943 39502601 38277679 5149335
(bps) 22121648768 22121457872 21435501512 2883627824
Output: Priority (pps) 0 0 0 0
(bps) 160 232 224 48
Non-Priority (pps) 7 8 8 2
(bps) 20968 15712 15520 3928
Total (pps) 7 8 8 2
(bps) 21128 15944 15744 3976
Processing: Load (pct) 94 94 91 49
CPP 0: Subdev 1 5 secs 1 min 5 min 60 min
Input: Priority (pps) 0 0 0 0
(bps) 160 104 104 24
Non-Priority (pps) 39500737 39499727 38275273 5149143
(bps) 22120414472 22119848056 21434153984 2883520624
Total (pps) 39500737 39499727 38275273 5149143
(bps) 22120414632 22119848160 21434154088 2883520648
Output: Priority (pps) 0 0 0 0
(bps) 0 0 0 0
Non-Priority (pps) 79003661 79002331 76552956 10262492
(bps) 48034225976 48033418408 46544198232 6239595664
Total (pps) 79003661 79002331 76552956 10262492
(bps) 48034225976 48033418408 46544198232 6239595664
Processing: Load (pct) 98 98 96 52
最大带宽
我们同样建立TrexProfile
,包长我们选择Fixed
1518
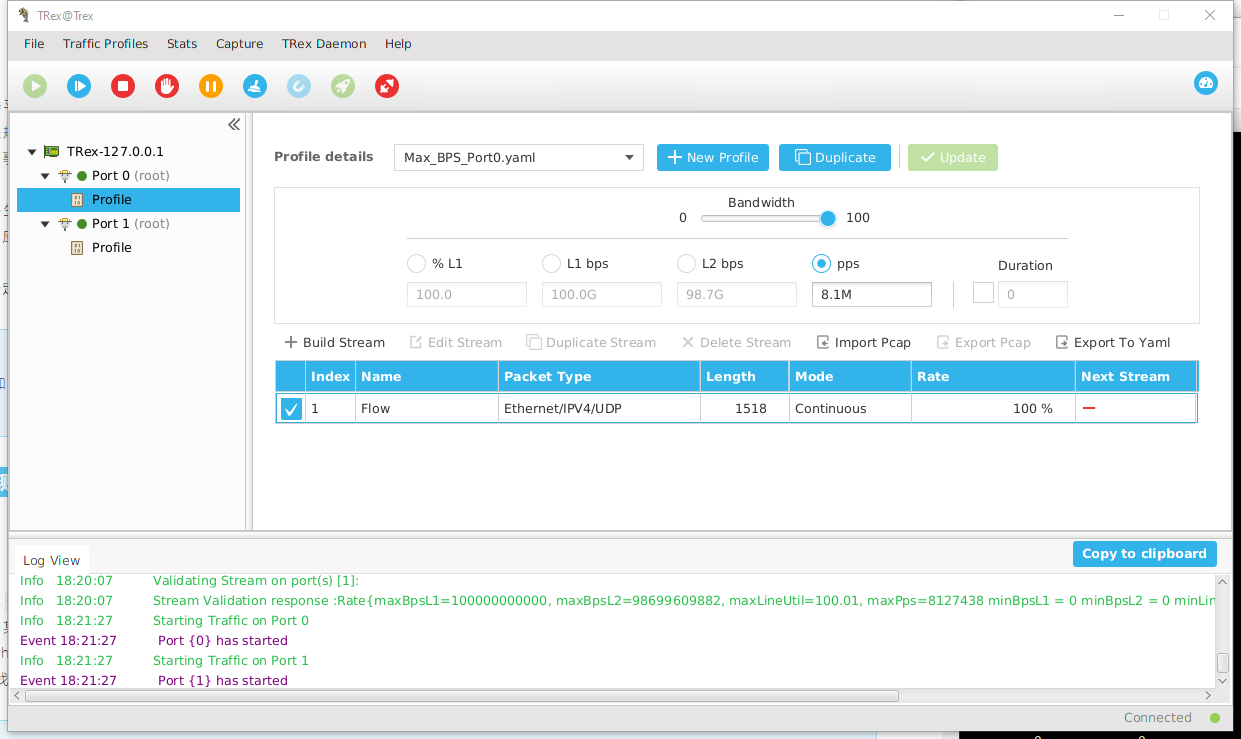
测试结果
既然pps某思都留有余量,这个100Gbps的ESP100是不是转发带宽上还有余量呢?我们干脆新增加两个万兆口打一下?牢记跨版~
interface TenGigabitEthernet0/0/0
ip address 3.3.3.1 255.255.255.0
!
interface TenGigabitEthernet1/0/0
ip address 4.4.4.1 255.255.255.0
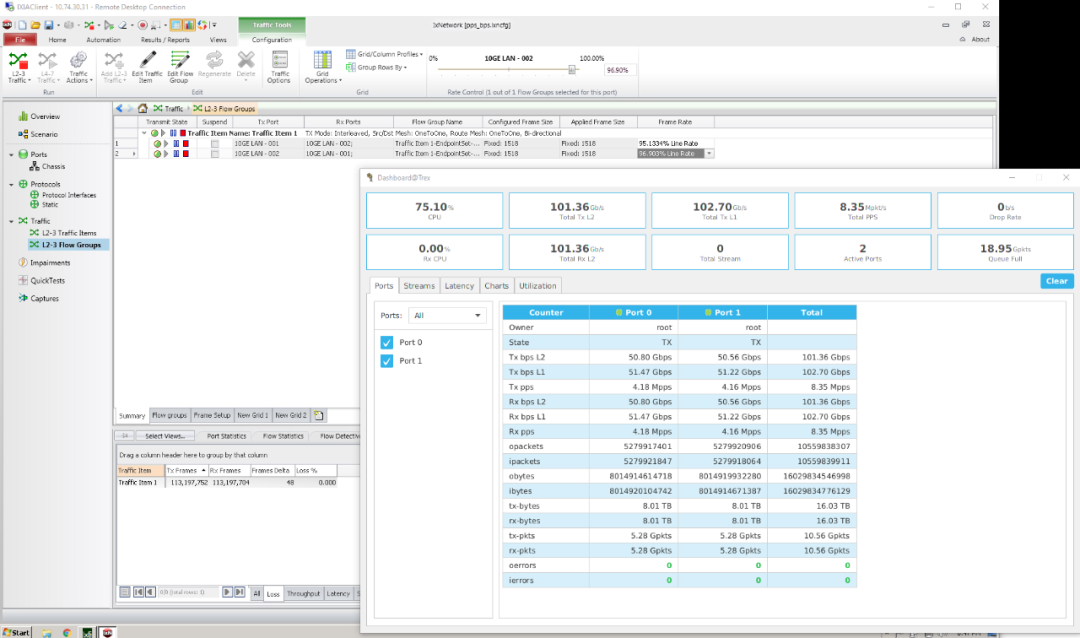
这次我们加了一对IXIA
万兆口, 可以看到最终转发带宽接近120Gbps,某思居然低标了20%!

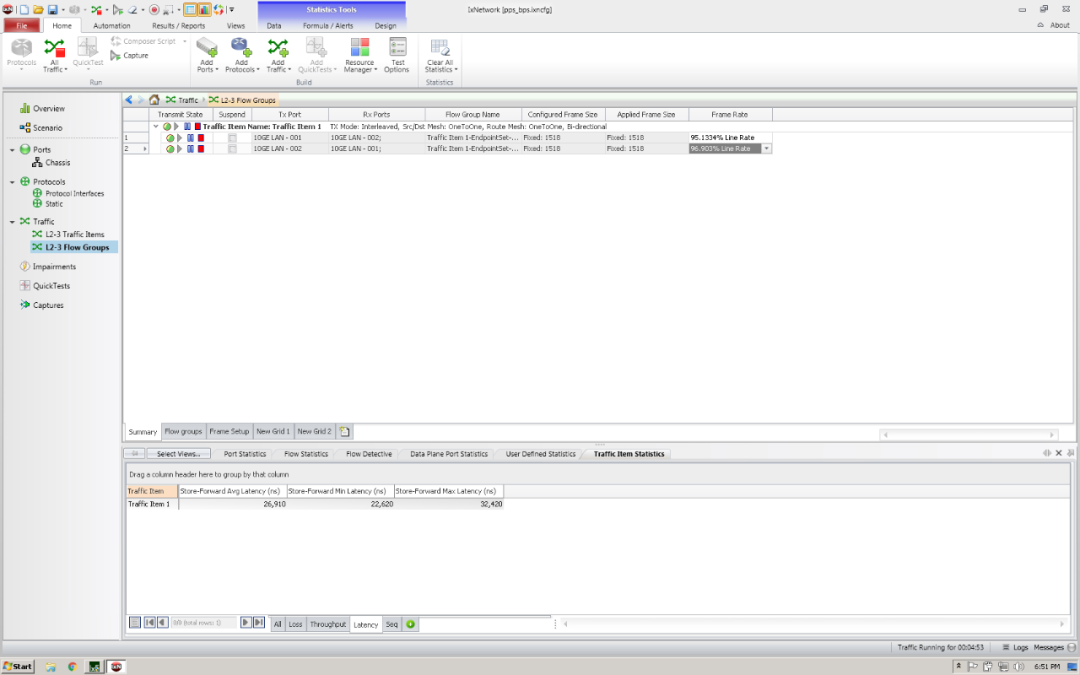
转发延迟在26us左右,而且是大包,小包会小一些,懒得测了就用这个值吧
吞吐测试场景缺陷规避手段
作弊手段2:规避大象流
很多路由器平台为了支持多业务转发,通常采用多核心的处理器,或者根据五元组hash到不同核心处理, 因此这样的平台要干的第一件事情就是规避大象流的测试,即以固定源IP
固定源端口
向固定目的IP
固定目的端口
发送流量,会导致一种情况就是某一个核在处理所有的事情,而其它核心空着啥事都干不了。通常这样的平台整机性能只有标称性能1/N, N=核心数
因此在很多生产网络中就会遇到非常严重的问题,例如主备中心之间的数据库备份等,通常就是一个大象流的业务场景,这样的平台会严重的拖慢应用。
客户验收一定要要求:
❝请厂商加测
❞大象流
测试项
大象流测试
在Trex中设置源目的IP地址为固定一个,UDP端口也固定,包大小为64B
然后打起来,ESP100在这种情况下处理器没有满(70%),但吞吐只能到55Mpps.

ASR1009X#cppload
CPP 0: Subdev 0 5 secs 1 min 5 min 60 min
Input: Priority (pps) 0 0 0 0
(bps) 0 136 104 104
Non-Priority (pps) 27502118 20110077 6338069 13307955
(bps) 15401187416 11261643880 26778580944 33680568928
Total (pps) 27502118 20110077 6338069 13307955
(bps) 15401187416 11261644016 26778581048 33680569032
Output: Priority (pps) 0 0 0 0
(bps) 160 232 224 248
Non-Priority (pps) 11 8 8 294138
(bps) 25872 15176 15448 1067908664
Total (pps) 11 8 8 294138
(bps) 26032 15408 15672 1067908912
Processing: Load (pct) 64 48 15 31
CPP 0: Subdev 1 5 secs 1 min 5 min 60 min
Input: Priority (pps) 0 0 0 0
(bps) 160 80 96 104
Non-Priority (pps) 27502385 20110219 6338097 13307486
(bps) 15401338112 11261723848 26778596920 33680335368
Total (pps) 27502385 20110219 6338097 13307486
(bps) 15401338272 11261723928 26778597016 33680335472
Output: Priority (pps) 0 0 0 0
(bps) 0 0 0 0
Non-Priority (pps) 55004540 38595854 12252973 26286038
(bps) 33442760296 23466280040 53908321432 67549100848
Total (pps) 55004540 38595854 12252973 26286038
(bps) 33442760296 23466280040 53908321432 67549100848
Processing: Load (pct) 70 51 16 33
问题原因在于包的Buffer系统在实际生产情况下如果是大象流也不可能全是64B的报文,所在256B左右就可以做到单个大象流
线速转发了
ASR1009X#cppload
CPP 0: Subdev 0 5 secs 1 min 5 min 60 min
Input: Priority (pps) 0 0 0 0
(bps) 160 104 104 104
Non-Priority (pps) 22644398 18100323 19497197 14012735
(bps) 47462658256 33608040864 18267433240 34687662760
Total (pps) 22644398 18100323 19497197 14012735
(bps) 47462658416 33608040968 18267433344 34687662864
Output: Priority (pps) 0 0 0 0
(bps) 248 208 216 248
Non-Priority (pps) 6 8 8 294138
(bps) 8680 24136 17592 1067908824
Total (pps) 6 8 8 294138
(bps) 8928 24344 17808 1067909072
Processing: Load (pct) 51 45 47 33
CPP 0: Subdev 1 5 secs 1 min 5 min 60 min
Input: Priority (pps) 0 0 0 0
(bps) 80 88 96 104
Non-Priority (pps) 22644400 18100322 19497196 14012262
(bps) 47462657688 33608040016 18267432944 34687426928
Total (pps) 22644400 18100322 19497196 14012262
(bps) 47462657768 33608040104 18267433040 34687427032
Output: Priority (pps) 0 0 0 0
(bps) 0 0 0 0
Non-Priority (pps) 45288750 34425526 37920799 27633204
(bps) 97099081600 65943126256 36939273568 69525129680
Total (pps) 45288750 34425526 37920799 27633204
(bps) 97099081600 65943126256 36939273568 69525129680
Processing: Load (pct) 54 46 50 35
作弊手段3:固定Hash调度
如果确定有作弊手段2
的缺陷,但是有些厂商搞定客户说没有大象流的场景,那么此处可以加测一个场景,有些路由器采用固定的Hash函数调度到某个核心,这样就有一个很好玩的hash冲突的攻击方法,也就是说当你正常的一个高优先级
的流量在传输时, 我可以构造相应的Hash冲突使得我大量的攻击流调度到你高优先级的流量所在的核心。构造方法特别简单,固定源目的IP地址和目的端口,然后二分法
寻找源端口
范围很容易找到可以影响高优先级
流量的,然后就可以批量构造流量发流。客户验收一定要要求:
❝请厂商加测
❞Hash冲突
测试项,构建旁路的攻击流量,并将主流量放置进入QoS优先级队列,检测Hash冲突攻击流量可以使得主流量丢包。
作弊手段4:流表Cache加速
还有一种路由器,查表引擎做不快,因为成本的考虑没有使用TCAM或者专用的查表器件,采用FastPath
和SlowPath
的设计模式,这种模式通常首包放到控制面,然后查好路由表以后在转发引擎上构建一个快速转发表。美其名曰Openflow的SDN实现方式。
客户验收一定要要求:
❝请厂商加测
❞固定源目的IP
,随机源目的端口
测试项,构建大量流表,检验该类型路由器流表保护机制,同时对这类路由器加测快速收敛
测试项,检测其高并发流表存在时的路由收敛流表更新时间。
3、4验证
很抱歉,思科没有这样的路由器出现过,因为这是典型的以追求PPS、BPS牺牲其它的错误架构,给你们验证一次也就是看到一样的结果和冗余的篇幅,拿某家的路由器来测呢,大家都知道是哪家了,攻击友商的事情我是干不出来的.
作弊手段5:乱序
还有很多路由器直接将大象流
分配到不同核心处理,最后出去的时候也不在意顺序,很有可能一些小包出去的快,大包出去的慢
客户验收一定要要求:
❝请厂商加测
❞随机包长
保序测试项。
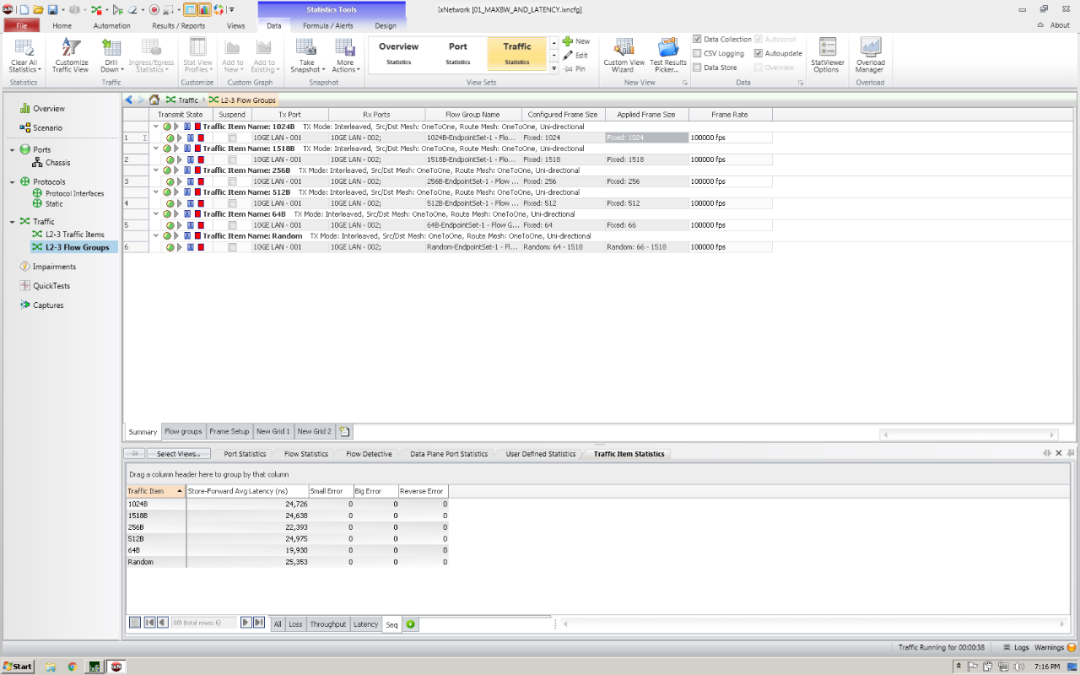
验证乱序
IXIA在IxNetwork中配置Configuration
->Traffic Options
勾选Sequence Checking
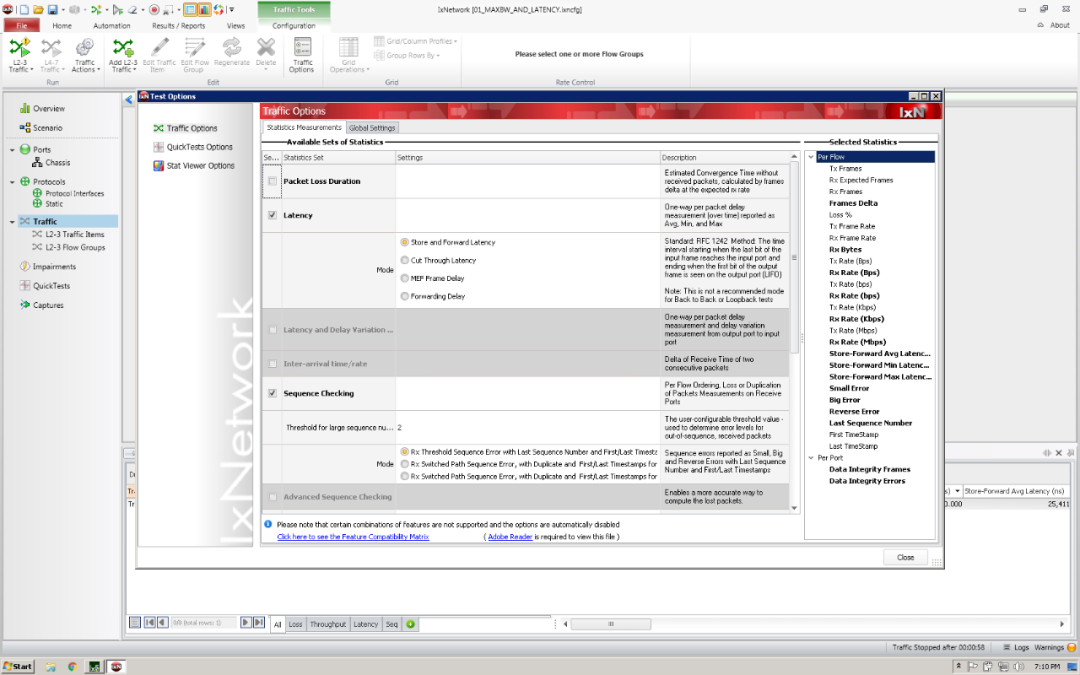
最终测试结果