面向专业文献知识实体的类型抽取系统及方法与流程
本发明涉及文本挖掘及信息抽取领域,具体涉及一种面向专业文献知识实体的类型抽取系统和抽取方法。
背景技术:
随着互联网的快速普及和硬件存储技术的发展,人们可以轻松的在不同的设备上浏览、获取到各类的数字资源,也可以通过众多的学术数据库或学术搜索引擎获取到所需的专业文献,如Google Scholar、百度学术、Cnki、万方数据等等.。由此看来,从互联网上获取海量的电子资源的确成为了一件轻松简单的事情,但是随之出现的问题是,现有的知识服务已经无法满足人们对信息“快速、简单、准确”的需求。面对这样的知识服务需求,我们需要针对这类专业文献文本进行实体识别并抽取出实体的类型信息,建立结构化的专业知识体系,以辅助用户进行文献检索。现在大部分的类型信息抽取系统和技术都是针对一些日常社交文本,如微博、Facebook、Twitter等,而针对这类有着众多专业术语的学术文献的研究却较少。
目前,虽然针对专业文献领域的信息抽取研究并不多,但其可观的应用前景和知识服务的需要也引发了国内外的研究热潮,并取得了一定的研究成果。例如国外的Google knowledge graph和Google Trends,国内的哈尔滨工业大学的同义词词林,万方数据的知识脉络检索等。其中,Google knowledge graph是把用户的检索对象当作一个实体,而不是单纯的关键词匹配检索,可以有效的得到实体相关的一些属性和具体资料;Google Trends是对用户的搜索记录进行分析,得到一些关键词的热点趋势;国内的“同义词词林”则是利用互联网的数据进行实体上下位关系的挖掘从而得到大部分实体的上下位关系,但是却缺少对专业文献知识实体这类特殊的专业术语进行分析;而万方数据的知识脉络检索是根据相关文献和参考文献的关系对文献的关键词进行关联,然后按时序排列展示出某段时间与用户检索词最相关的词汇。
现有的类型抽取技术主要存在以下几个方面的不足:A)类型需要人工预先定义,带有局限性;B)需要大量的人工标注,耗时耗力;C)针对专业领域的类型抽取还少,大部分应用于常用实体信息抽取方法在专业领域并不适用;D)缺少直观、形象的树图可视化演示,大部分系统仍然是以文字、数据演示为主。
技术实现要素:
本发明的目的在于克服现有专业领域实体类型抽取技术存在的上述不足,提出一种面向专业文献知识实体的类型抽取方法及系统。
为实现上述目的,本发明的技术方案为:
本发明公开了面向专业文献知识实体的类型抽取系统,包括以下7个模块:
(a)查询及反馈接口,用于用户的输入处理和查询处理,将数据可视化结果反馈给用户;
(b)在线爬虫及管理模块,用于后台自动化地爬取管理员指定或默认的专业文献页面及进行页面数据的预处理;
(c)知识实体识别模块,用于对预处理后的文献标题及摘要数据进行知识实体识别;
(d)类型标签抽取模块,用于实现对模块(c)中得到的知识实体进行类型标签抽取及部分实体类型标注,得到类型标签集合和部分已标注实体;
(e)类型标签传播及索引库建立模块,以模块(c)中的未标知识实体集合、模块(d)的类型标签集合和部分已标注实体为输入,进行基于多标签加权的标签传播及建立知识实体及其类型关系索引库;
(f)知识实体类型关系图模型构建模块,根据用户输入的关键词对索引库进行检索,并构建出不同的知识实体类型关系图模型;
(g)数据可视化模块,对模块(f)中的模型进行Web可视化实现。
本发明还公开了面向专业文献知识实体的类型抽取方法,采用上述抽取系统,进行以下步骤:
S1.数据爬取及预处理:管理员设置文献爬取地址和范围,在线爬虫及管理模块在后台根据指定的范围对文献页面进行爬取,同时对爬取的页面数据进行预处理;
S2.知识实体识别提取:知识实体识别模块对预处理后的文献信息进行实体识别并提取出来;
S3.类型抽取和标注:知识实体类型抽取模块对提取的知识实体进行类型抽取和标注,得到类型标签集合和部分已标注实体;
S4.建立索引库:将得到的知识实体及其类型标签集合和部分已标注实体进行数据库存储,进行基于多标签加权的标签传播,得到类型标签矩阵并建立知识实体及其类型的索引库;
S5.获取关键字:通过用户查询及反馈接口获取用户查询的知识实体关键字;
S6.建立类型列表:根据关键字在步骤S4中创建的索引库进行知识实体索引项进行匹配,从而得到与关键字相关的知识实体列表,按照相似性排序后得到最终的知识实体及其类型列表;
S7.根据需求建模:根据用户需求利用知识实体类型关系图模型构建模块对获得的知识实体及其类型列表进行建模;
S8.数据可视化:数据可视化模块将步骤S7得到的模型进行Web可视化数据处理,返回JSON数据到前端并实现Web前端可视化演示。
使用本发明的面向专业文献知识实体的类型抽取系统及方法,具有以下几个方面的优点:
1)本发明在类型预定义方面解决了类型人工定义的局限性问题,使用无监督的启发式规则方法对全部实体进行类型标签抽取,获得最有可能的类型标签集;由于提出的类型抽取方法是无监督与半监督方法的结合,因此抽取的过程无需大量的人工标注,而且灵活性和通用性也比一般的有监督或半监督方法要强。另外,这种方法是通过分析专业领域知识实体的特性进行改进的,适用于不同的专业领域知识实体的类型抽取,有助于专业知识网络的结构化实现。
2)可以指定爬取文献页面。管理员可以指定爬取页面的地址和范围,因此本系统可以轻松扩展到其他领域专业文献的数据采集,检索量并不局限在本地数据库。例如:当在线的论文数据库有更新时,管理员也可以更新爬取范围,系统的爬虫就会自动爬取新数据并更新本地数据库。
3)检索到的知识实体类型开放、多样。本系统并非人工预定义实体类型,而是利用结合摘要的基于启发式规则的方法来进行类型标签集合抽取,再进行不可靠类型标签筛选,得到最终的类型标签集合。这样得到的标签集合解决了人工预定义的局限性和主观性的问题,可以开放、全面、客观的得到比较合理的类型集合,覆盖了大部分的知识实体。
4)用户可以通过可视化界面得到类型相关的知识脉络图。本系统利用知识实体类型关系图模型构建模块对获得的知识实体及其类型列表进行建模,分别得到基于同一类型的实体层次关系树模型、基于类型分组的知识关系图模型和基于时序的知识热点跟踪图模型,最后使用可视化模型将其反馈给用户。
5)系统性能高,使用简便。系统采用MVC架构的思想,前台的用户检索及可视化模块和后台的爬取分析模块是分隔开的,因此,后台的数据爬取、预处理、抽取和标注等流程并不会拖慢前端的可视化显示。另外,由于建立了索引库,所以前端检索和获取数据时速度很快,性能较高。基于Web的可视化也使得用户使用十分简单方便,不需要安装任何客户端即可使用。
附图说明
图1为本发明的面向专业文献知识实体的类型抽取系统架构图。
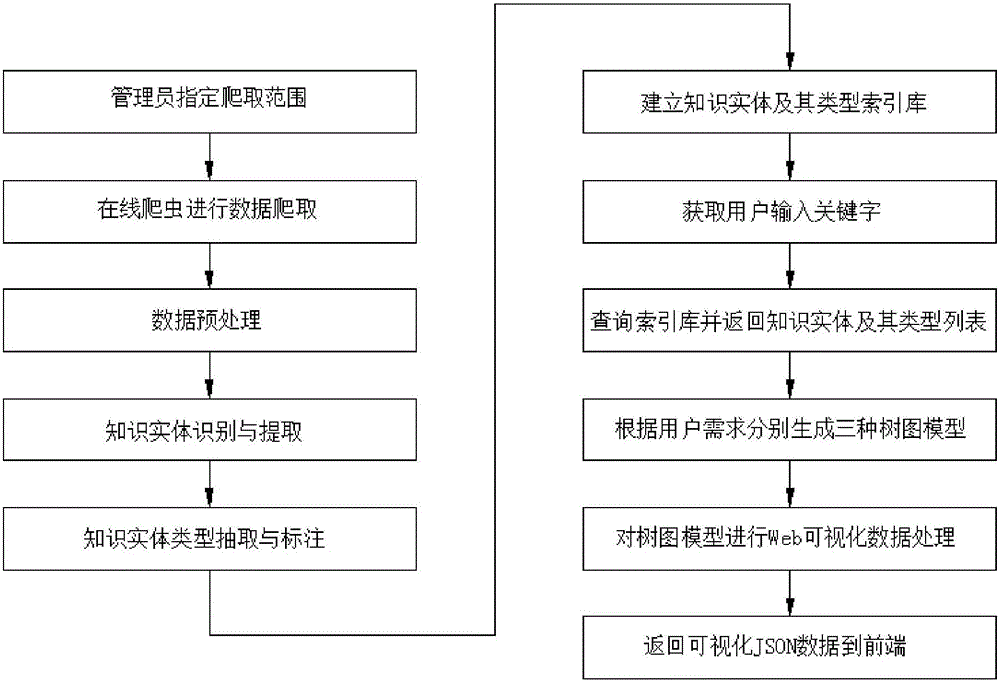
图2为本发明的面向专业文献知识实体的类型抽取方法的流程图。
图3为本发明的基于条件随机场的知识实体识别步骤的流程图。
图4为本发明的实体类型抽取与标注步骤的实现原理图。
图5为本发明的基于多标签加权的标签传播算法的实现原理图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。
图1示出了本发明的面向专业文献知识实体的类型抽取系统架构图。
参照图1,本发明的实体类型抽取系统包括用户查询及反馈接口、在线爬虫及管理模块、知识实体识别模块、知识实体的类型抽取模块、类型标签传播及索引库建立模块、知识实体类型关系图模型构建模块、数据可视化模块,共7个模块。
查询及反馈接口,用于用户的输入处理和查询处理,将数据可视化结果反馈给用户;
在线爬虫及管理模块,用于后台自动化地爬取管理员指定或默认的专业文献页面及进行页面数据的预处理;
知识实体识别模块,用于对预处理后的文献标题及摘要数据进行知识实体识别,得到知识实体集合;
知识实体的类型抽取模块,用于实现对得到的知识实体集合进行类型标签抽取及部分实体类型标注,得到类型标签集合和部分已标注实体;
类型标签传播及索引库建立模块,以未标知识实体集合和类型标签集合和部分已标注实体为输入,进行基于多标签加权的标签传播,然后建立知识实体及其类型关系索引库,进行本地存储;
知识实体类型关系图模型构建模块,根据用户输入的关键词对索引库进行检索,并构建出不同的知识实体类型关系图模型;
数据可视化模块,对构建好树图模型进行Web可视化实现。
本发明还公开了上述实体类型抽取系统的抽取方法,图2为本发明的面向专业文献的知识实体类型抽取方法的流程图。以下详述知识实体类型抽取方法步骤。
S1.数据爬取及预处理
管理员通过管理模块设置爬取地址和范围;在线爬虫模块在后台根据指定的范围对文献页面进行爬取;对爬取的页面数据进行数据预处理,例如中文分词、去停用词,特征筛选等。
S2.知识实体识别提取
利用知识实体识别模块对清理后的文献标题、摘要、关键词等文献信息进行实体识别并提取出来。
S3.类型抽取和标注
利用知识实体类型抽取模块对步骤S2中得到的知识实体进行类型抽取和标注,得到类型标签集合和部分已标注实体,具体过程如下:
(S3-1)结合文献摘要信息中知识实体的相关上下文以辅助类型标签抽取,以抽取到的知识实体为基础,对文献的摘要进行知识实体匹配,把在摘要中匹配到的知识实体及其后相邻的名词抽取出来,添加到知识实体集合中;
(S3-2)利用基于启发式规则的方法对步骤(S3-1)中得到知识实体集合进行类型标签抽取,得到候选类型标签集合,类型抽取的同时获得部分已标注实体;
(S3-3)筛选掉不可靠的类型标签,通过统计类型标签与其所属知识实体共现的频次,然后根据频次特征筛选掉共现频次低且对应知识实体出现频次少的类型标签,输出筛选后的类型标签集合。
S4.建立索引库
将得到的知识实体及其类型标签集合和标注实体进行数据库存储,进行基于多标签加权的标签传播,得到类型标签矩阵并建立知识实体及其类型的索引库。基于多标签加权的标签传播包括以下步骤:
(S4-1)构建并初始化转换概率矩阵T,用于表示知识实体之间的转换概率。
转换概率矩阵T按公式1计算。
其中,Tij表示从节点Xj转移到节点Xi的概率,也就是知识实体ej转移到知识实体ei的概率,转移概率Wij由下面公式2计算得到。
其中,sij是知识实体ei和ej的相似度,参数用于调整sij的比例,参数为sij的平均值。知识实体间的相似度S使用编辑距离进行度量:编辑距离越大,相似度越小,假设源字符串与目标字符串长度的最大值为Lmax,编辑距离为LD,相似度S利用以下公式3计算。
S=1-LD/Lmax (公式3)
(S4-2)构建并初始化类型标签矩阵Y,用于表示每个知识实体包含的类型标签及其类型标签权重。设第一层抽取中成功抽出类型词的知识实体个数为l,未能抽出类型词的知识实体个数为u,则定义类型标签矩阵Y是一个(l+u)×R的矩阵(R为已抽取类型词去重词典个数)。因此,设YL为已标类型矩阵,YU为未标类型矩阵,YN为每次传播迭代后的新增标注矩阵。类型标签权重及类型标签矩阵Y由公式4、5计算得到。
其中,设知识实体ei在第一层类型标注后有K个类型标签,Cik是第i个实体的k标签的出现频次,Wik是知识实体ei拥有类型标签k的权重,Wik以标签k在ei中出现的频率来度量,当知识实体ei拥有类型标签k时,则Yij=Wik,否则Yij=0。
(S4-3)对于每一个已标实体,循环对所有未标实体进行转换概率计算,如果知识实体之间的转换概率大于阈值(阈值ζ按公式6计算),则进行标签传播。一轮传播结束后,将新标知识实体集合替换原来的已标知识实体集合,得到第t代的新增标注矩阵。
其中,N为的行数,为第t次迭代时的新增标注矩阵。
(S4-4)循环迭代进行步骤(S4-3)的标签传播过程,直到新标知识实体集合为空或未标类型矩阵不再改变,迭代结束,输出最新的已标类型矩阵(第t+1代标签传播迭代完成)。
S5.获得关键字
通过用户查询及反馈接口获取到用户查询的知识实体关键字。
S6.建立类型形表:
根据用户输入的关键字在索引库进行知识实体索引项进行匹配,从而得到与关键字相关的知识实体列表,按照相似性排序后得到最终的知识实体及其类型列表;
S7.根据需求建模
根据用户需求,利用知识实体类型关系图模型构建模块对获得的知识实体及其类型列表进行建模,分别得到基于同一类型的实体层次关系树模型、基于类型分组的知识关系图模型和基于时序的知识热点跟踪图模型。具体建模过程如下详述:
(S7-1)根据用户输入的关键词从知识实体索引库中提取出与该关键词相关的知识实体集合,相关关系包括标题中和摘要中的共现关系、包含关系以及扩展关系。
(S7-2)构建基于同一类型的实体层次关系树模型,验证知识实体集合中两两个实体之间的扩展或包含关系,如果实体ei包含实体ej,则建立树图模型中父子关系R(ei,ej),表示ei是ej的父节点,依次类推,建立层次关系模型。
(S7-3)构建基于类型分组的知识关系图模型,对知识实体集合中的知识实体按类型进行分组,统计每个类型分组的权值,分组内的知识实体也按照实体权重降序排序;筛选出权值最高的N个分组,每个分组筛选出排在前M个的知识实体,按照关键词、类型分组、实体的次序构造三层的图模型。
(S7-4)构建基于时序的知识热点跟踪图模型,根据知识实体的时间进行排序,构建按照半年为周期的时间段分组,分别统计每个时间段出现的相关的知识实体数量,各个时间段分组内的知识实体按照实体权重进行排序,最后以时间分组和对应实体列表构建热点跟踪图模型。
(S7-5)把步骤(S7-2)、(S7-3)、(S7-4)所述的模型转换成JSON形式的数据并输出到数据可视化模块。
S8.数据可视化
利用数据可视化模块步骤S7中的三个模型进行Web可视化数据处理,返回JSON数据到前端并实现Web前端可视化演示。
如图3为本发明的基于条件随机场的知识实体识别步骤的流程图。首先,对预处理后的文献数据集进行特征抽取,包括词性特征、前后导词特征、前后缀特征等。下一步把部分标注数据集及抽取到的特征都放进CRF模型进行训练,得到训练后的CRF模型。然后使用训练后的CRF模型对未标数据进行实体标注,得到标注好的数据集后计算其F1值。如果F1值提升幅度大于前一代的F1值,则进行半监督迭代过程。半监督迭代过程首先把标注数据集分割成10份,分别计算各自的F1值,选择最好的那一份数据集组合到人工标注数据集中,重新对CRF模型进行训练。重复上述训练、标注过程,直到F1值不在提升,迭代过程结束,输出实体标注集。
图4为本发明的实体类型抽取与标注步骤的实现原理图。流程的第一步是进行实体识别,然后使用结合摘要的基于启发式规则的类型抽取方法进行类型的抽取,得到是全体类型标签集合和部分已标注的数据(类型词出现在实体内部)。接着,利用基于多标签加权的标签传播算法进行类型标签传播及标注,最后得到类型标注结果。
图5为本发明的基于多标签加权的标签传播算法的实现原理图。该图主要说明试题类型标注步骤中的基于多标签加权的标签传播算法的实现原理。其中,图左侧的是已标签的l个实体及其k个标签数据作为输入数据,每一个标签有自身对应的权值Wik,而图右侧的是将进行标签传播的n-l-1个未标实体,在标签传播之前,最右侧的输出标签是不存在的。如图5所示的例子,已标实体e1和e2同时满足对实体el+1的标签传播条件时,实体e1把标签1-3传播到实体el+1,而最右侧新标签1-3对应的新权值为Wik*Tij。然后,实体e2把标签2、4、5传播到实体el+1,其中标签4和标签5的新权值也是Wik*Tij,而标签2中已经有权值,所以进行权值的累加,因此标签2中权值为W12*T1,l+1+W22*T2,l+1。
综上,本发明的面向专业文献知识实体的类型抽取系统及方法,以在线爬虫爬取的专业文献数据为基础,进行知识实体的识别、实体类型标签的抽取、类型标注及标签传播,得到知识实体的类型及其基于类型的关系,建立索引库进行本地存储。然后,根据用户输入的关键词从知识实体索引库中提取出与该关键词相关的知识实体集合,构建基于同一类型的实体层次关系树模型、基于类型分组的知识关系图模型、基于时序的知识热点跟踪图模型,最后使用数据可视化技术进行前端绘图并呈现给用户,本发明实施简单,抽取准确率高,具有很强的实际价值和现实意义。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 图片显示方法及装置与流程
- 基于随机多视角哈希的大规模近...
- 基于数据温度和节点性能的异构...
- 内存数据的同步方法和装置与流...
- 基于Hash‑Cube空间层...
- 基于GIS地图的订单分拣方法...
- 基于经纬度及文本比对的地址相...
- 一种数据库数据读写方法和装置...
- 用于第三方的数据共享更新方法...
- 基于Pitman‑Yor过程...
- 还没有人留言评论。精彩留言会获得点赞!
- 一种基于模式自学习的中文开放式关系抽取方法
- 能够抽取硬盘的盒体的制作方法
- 一种利用依存分析的开放式中文实体关系抽取方法
- 一种中文微博评价对象的抽取方法
- 藏语实体关系抽取方法
- 模型更新装置及方法、数据处理装置及方法、程序的制作方法
- 一种面向开放网页的实体属性抽取方法和系统的制作方法
- 安全算法选择处理方法与装置、网络实体及通信系统的制作方法
- 具防误动作的硬碟抽取盒的制作方法
- 确定音乐实体关系的方法和装置及查询处理方法和装置制造方法
- 一种面向开放网页的实体属性抽取方法和系统的制作方法
- 基于mip技术的通信方法、网络功能实体和终端的制作方法
- Web视频页面的复杂命名实体的抽取方法及其系统的制作方法
- 基于树到树翻译模型的翻译规则抽取方法和翻译方法
- 一种中文命名实体识别歧义消解方法
- 藏语实体知识信息抽取方法
- 一种面向在线百科的实体属性抽取方法及系统的制作方法
- 一种基于在线百科链接实体的知识抽取方法
- 一种借助图随机游走的开放类别命名实体抽取方法及装置制造方法
- 中文机器阅读系统的制作方法
- 藏语实体知识信息抽取方法
- 一种面向在线百科的实体属性抽取方法及系统的制作方法
- 一种基于在线百科链接实体的知识抽取方法
- 一种借助图随机游走的开放类别命名实体抽取方法及装置制造方法
- 基于无监督的实体关系抽取的主题元搜索系统及方法
- 一种人物关系抽取方法和装置制造方法
- 藏语实体知识信息抽取方法
- 一种面向在线百科的实体属性抽取方法及系统的制作方法
- 一种基于在线百科链接实体的知识抽取方法
- 基于无监督的实体关系抽取的主题元搜索系统及方法
- 一种基于依存树的中文实体关系挖掘的控制装置的制作方法
- 一种中文实体间语义关系抽取方法
- 舆情事件的实体关系抽取方法和装置的制作方法
- 抽取关系型表格的方法和装置的制作方法
- 用于动力工具的碎屑抽取器的制作方法