
【汉语音韵学笔记】上古音·从古声十九纽到四分法

序言
与之前那两篇分别讲主元音与韵尾的文章不一样, 这篇讲声母的文章大概实在没有多少趣味性。
因为原始材料太单一了——基本上只有谐声分析一个 [注0]。
所以照着谐声统计数据一通分析就行了。
呃你问我啥叫「谐声关系」?
我觉得吧,「虯」和「叫」啊,「皆」和「諧」啊…之间的这种关系就叫谐声关系。
古声十九纽
在之前的两篇文章里,我们看到谐声分析对重建古典汉语主元音与韵尾起到了相当重要的作用——这一点从清儒开始就注意到了。那么,谐声分析对重建古典汉语声母是否也该有很大的作用呢?首先注意到这个问题的学者依旧是一位清儒:钱大昕(1728—1804)。
按照当时通行的理解,「古代」的声母格局大概一直都是所谓「宋人三十六字母」的样子,即:


而钱大昕则根据谐声关系(以及一些中古时期的证据)为这些声母分了一下类。他发现从谐声关系上来看呢,以下这些声母总是搞在一起,经常你谐我,我谐你:
0. 明微
1. 幫滂並非敷奉
2. 泥孃
3. 端透定知徹澄
于是他就想啊,在很久很久以前,「明」和「微」这两个宋人声母是不是完全同音呢?「泥」和「孃」这两个宋人声母是不是也完全同音呢?
于是焉他就提出了「古无轻唇音」和「古无舌上音」两条说法,认为「很久以前」「非敷奉微」这几个声母读如「幫滂并明」这几个声母,「知徹澄娘」这几个声母读如「端透定泥」这几个声母。
你以为我现在会就这两条说法是否正确展开讨论?
非也。他提出的这个说法具体对不对并不重要,重要的是他所发现的谐声现象——「明」经常与「微」谐声云云。在前两篇文章里我们已经看到了,不要指望清儒提出什么靠谱的模型(虽说他们总是热衷于此),能把现象整理清楚就不错了。
钱大昕之后是邹汉勋(1806—1854)。相比于钱大昕,邹汉勋认识到了一点:宋人三十六字母是可以拆的!
为什么要拆它呢?
邹汉勋发现「照穿牀審禪」这五个声母所辖的字明显分为两类,其中一类——在韵图中排布在「三等」格子里的「照穿船審禪」——经常与「端透定知徹澄」这一堆相互谐声;而另一类——在韵图中排布在「二等」格子里的「菑初崇山」——经常与「精清从心」这一堆相互谐声;并且这两类之间几乎完全不谐。
这个现象在后世被概括为「照三归端」与「照二归精」。
顺便,邹汉勋还发现「日」与「泥孃」之间同样有密切的谐声关系——这与「照三归端」本质上是平行的,不过后世还是为其专门起了个名字,曰「孃日归泥」。
邹汉勋之后则是曾运乾(1884—1945)。
曾运乾发现「喻」这个声母也可以按照韵图等位拆成两类,其中在韵图中排布在「三等」格子里的那部分经常与「匣」等声母相互谐声,而在韵图中排布在「四等」格子里的那部分经常与「定」等声母相互谐声;并且这两类之间也很少互谐。
于是他就提出了「喻三归匣」与「喻四归定」。
总而言之呢,在这群学者的各种归并之后,上古声母的数量被大大降低啦,低得甚至都有学者喊出「古声十九纽」的说法啦。
当然,具体是哪十九纽并不重要,反正现在我们都知道这个模型不怎么样——它一点都没讲这所谓「古声十九纽」是怎么分化成后世这个样子的。
嗯,好像接下来我们要讲分化条件了?
哦那是不可能的,谐声现象还没整理好呢。
七个大系
看起来没有什么好办法,我们只能自己重新整理一遍现象了。
清儒所使用的底本是宋人三十六字母——现在我们都知道「三十六字母」所分析的音系有点晚,差不多都到了中唐了。我们手里其实有更早的原材料:切韵音系本尊。清儒在分析切韵音系本尊的时候,其实已经使用系联法整理出描摹切韵音系本身的 51 个声母来了。结合梵汉对音、日语对音等诸多材料,不难为这 51 个声母给出大致的拟音来 [注1]:
反切武类 /m-/,反切符类 /b-/,反切方类 /p-/,反切芳(匹)类 /pʰ-/;
反切莫类 /m⁽ʶ⁾-/,反切蒲类 /b⁽ʶ⁾-/,反切博类 /p⁽ʶ⁾-/,反切普类 /p⁽ʶ⁾ʰ-/;
反切於类 /ʔ-/;
反切烏类 /ʔ⁽ʶ⁾-/;
反切于类 /w-/(偶尔为 /ɰ-/),反切以类 /j-/,反切許类 /h-/~/x-/,反切魚类 /ŋ-/,反切渠类 /ɡ-/,反切居类 /k-/,反切去类 /kʰ-/;
反切胡类 /ʁ-/,反切呼类 /χ-/,反切五类 /ɴ-/,反切古类 /q-/,反切苦类 /qʰ-/;
反切徐类 /z-/,反切息类 /s-/,反切疾类 /dz-/,反切子类 /ts-/,反切七类 /tsʰ-/;
反切蘇类 /s⁽ʶ⁾-/,反切昨类 /dz⁽ʶ⁾-/,反切作类 /ts⁽ʶ⁾-/,反切倉类 /ts⁽ʶ⁾ʰ-/;
反切所类 /ʂ-/,反切士类 /dʐ-/,反切側类 /tʂ-/,反切初类 /tʂ-ʰ/;
反切食类 /ʝ-/~/ʒ-/,反切式类 /ç-/~/ʃ-/,反切而类 /ɲ-/,反切時类 /dʝ-/~/dʒ-/,反切之类 /tç-/~/tʃ-/,反切昌类 /tçʰ-/~/tʃʰ-/;
反切力类 /ɭ-/~/l-/,反切女类 /ɳ-/,反切直类 /ɖ-/,反切陟类 /ʈ-/,反切丑类 /ʈʰ-/;
反切盧类 /l⁽ʶ⁾-/,反切奴类 /n⁽ʶ⁾-/,反切徒类 /d⁽ʶ⁾-/,反切都类 /t⁽ʶ⁾-/,反切他类 /t⁽ʶ⁾ʰ-/。
然后我们面对着成千上万条谐声关系,用目测法给这 51 个声母大致分成了如下七组:
0. 武莫,辖字合计 1110;
1. 符方芳蒲博普,辖字合计 2616;
2. 於烏于許魚渠居去胡呼五古苦,辖字合计 8709;
3. 以徐食式時之昌直陟丑徒都他,辖字合计 6139;
4. 息疾子七蘇昨作倉所士側初,辖字合计 3983;
5. 而女奴,辖字合计 920;
6. 力盧,辖字合计 1735。
这成千上万条谐声关系几乎全都是每组内部谐声,跨组谐声的情况虽然存在但数量很少。
是个人就能看出来这七组声母下辖的字数极度不平衡。
那怎么办呢?我们来量化分析一下。
怎么个量化法呢?
see here: 《谐声时代章组不独立说》,我懒得抄了。
以 @poem 所发布的带有传世字形谐声分析的广韵全字表为样本,给这 51 个声母计算一下任意两个声母之间的谐声次数以及「互谐指数」,结果长这样:
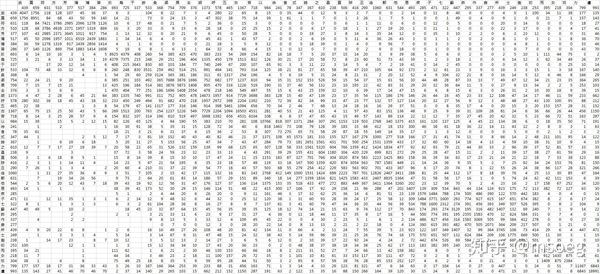



表3一出来,情况就很明显了:
「武莫」为一簇。后文称之「武系」。
「符方芳蒲博普」为一簇。后文称之「方系」。
「於烏」为一簇,其中「烏」时常谐「胡古苦」。后文称之「於系」。
「于許」为比较松散的一簇,其中「許」与其他很多声母相互谐声的情况相当多,「于」与其他声母相互谐声的情况比较少,主要谐「胡」。由于「于」与其他声母相互谐声的情况较少,后文称之「于系」。
「魚五」为一簇,其中「五」时常谐「胡古苦」。由于「魚」与其他声母相互谐声的情况较少,后文称之「魚系」。
「渠居去」为一簇,有时也与其他声母相互谐声。后文称之「居系」。
「胡呼古苦」为一簇,有时也与其他声母相互谐声。后文称之「古系」。
「以徐食式」为松散的一簇,且似乎时常与「直丑徒他」相互谐声。看起来「以」这个声母似乎比较有代表性(字数也是最多的),后文称之「以系」。
「時之昌直陟丑徒都他」为一簇,有时也与其他声母相互谐声。鉴于「之」看起来比较干净,不常与「以系」诸声母谐声,后文称之「之系」。
「息蘇所」为一簇,但也时常与「七倉初」相互谐声。后文称之「息系」。
「疾子七昨作倉士側初」为一簇。后文称之「子系」。
「而女奴」为一簇。后文称之「而系」。
「力盧」为一簇。后文称之「力系」。
不过这个分析其实有一点需要修正。经过目测,于类字绝大多数都是合口字,与于类字相互谐声的其他声母字同样绝大多数都是合口字。有鉴于此,把声母为「許」的开口字划进「于系」似乎不大合适。考虑到声母为「許」的开口字并不经常与其他声母字相互谐声,此处姑且将这部分字独立称作「許开」。
一四等 vs 二等
到了这一步,关于声母之间谐声关系,能挖的现象似乎已经不多了。我们只好看看韵母。
怎么看呢?
切韵音系里声母与韵母的搭配关系是有很多限制的。首先,如先前的文章 《从二十一部到六元音》所言:
南北朝时期汉语音节明显分为两大类:一类为「(反切)三等音节」,通常由「三等声类」「三等韵类」拼合得出,另一类为「(反切)非三等音节」,通常由「非三等声类」「非三等韵类」拼合得出。
在这 51 个声类中,除去在梵汉对音里兼译卷舌音与非卷舌音的「力盧」两类之外,「武符方芳於于以許魚渠居去徐息疾子七食式而時之昌」这 23 个声类明显属于「三等声类」,通常只接三等韵类;而「莫蒲博普烏胡呼五古苦蘇昨作倉奴徒都他」这 18 个声类明显属于「非三等声类」,几乎完全只接非三等韵类;只有「所士側初女直陟丑」这 8 个声类比较特殊,既能接三等韵类,又能接非三等韵类。
而这 8 个声母的共同点有两个。首先,它们似乎都是卷舌的。事实上,在魏晋南北朝时期的梵汉对音之中,用以对译梵语卷舌辅音的汉字几乎全部都以「力盧所初女直陟丑」为声母,以「所初直陟丑」为声母的汉字也几乎仅用于对译梵语卷舌辅音。由此观之,切韵音系里「所初直陟丑」这五个声类极有可能就是卷舌的 [注2]。而根据后世演化的相似性,「士側女」也应该与前者一致,都是卷舌的。
其次,它们都不能与(反切)一等韵母及(反切)四等韵母组合 [注3]——相对地,「莫蒲博普烏胡呼五古苦蘇昨作倉奴徒都他」这 18 个声母全都能够与(反切)一等韵类及(反切)四等韵类组合。换句话说,它们是仅有满足下述条件的 8 个声母:当后接非三等韵母时,该韵母必为(反切)二等韵类。(反切非三等包含且仅包含反切一等、反切四等与反切二等这三类。)
这一点强烈暗示(反切)二等韵母同样都是卷舌的 [注4],而(反切)一四等韵母都不是卷舌的。
那么好了,我们现在发现有些声母不能接一四等韵母但能接二等韵母。那么有没有不能接反切二等韵母但能接一四等韵母的声母呢?还真有:「蘇昨作倉奴徒都他」这 8 个。
这下就有趣了:
谐声「武系」里,根据图3粗略分析,能接一四等韵母的是「莫」,能接二等韵母的也是「莫」;
谐声「方系」里,根据图3粗略分析,能接一四等韵母的是「蒲博普」,能接二等韵母的也是「蒲博普」;
谐声「於系」里,根据图3粗略分析,能接一四等韵母的是「烏」,能接二等韵母的也是「烏」;
谐声「于系」里,根据图3粗略分析,没有能接非三等韵母的;
谐声「許开」里,根据图3粗略分析,没有能接非三等韵母的;
谐声「魚系」里,根据图3粗略分析,能接一四等韵母的是「五」,能接二等韵母的也是「五」;
谐声「居系」里,根据图3粗略分析,没有能接非三等韵母的;
谐声「古系」里,根据图3粗略分析,能接一四等韵母的是「胡呼古苦」,能接二等韵母的也是「胡呼古苦」;
谐声「以系」里,根据图3粗略分析,没有能接非三等韵母的;
谐声「之系」里,根据图3粗略分析,能接一四等韵母的是「徒都他」,能接二等韵母的也是「直陟丑」;
谐声「息系」里,根据图3粗略分析,能接一四等韵母的是「蘇」,能接二等韵母的也是「所」;
谐声「子系」里,根据图3粗略分析,能接一四等韵母的是「昨作倉」,能接二等韵母的也是「士側初」;
谐声「而系」里,根据图3粗略分析,能接一四等韵母的是「奴」,能接二等韵母的也是「女」;
谐声「力系」…呃都说了「力盧」情况特殊。
总之,在除了「力系」之外的任何一个经粗略分析得出的谐声声母系里,都有数量相同的「能接一四等韵母的声母」与「能接二等韵母的声母」。
而另一方面,在研究上古韵母时,我们发现了这样一条规律:对于几乎每一个上古韵母,其在非三等条件下均会分化进入一个切韵一四等韵母(以一等 vs 四等的形式保持前后元音对立),以及一个切韵二等韵母(通常伴随前后对立中和)。结合前文「切韵二等韵母卷舌说」以及「蘇昨作倉奴徒都他」vs「所士側初女直陟丑」的情况,我们显然有理由提出如下模型:
0. 声母的卷舌 vs 非卷舌对立是原生的——至少自传世谐声以来一贯如此。
1. 韵母的卷舌 vs 非卷舌对立是在声母的影响下次生的,i.e.,二等韵母的产生机制是声母的卷舌色彩把主元音同化了,并且前后对立也通常中和了。
用公式写的话大概长这样(「古典」表示根据传世字形的谐声关系所分析出来的古典汉语,C 表示任意辅音,ʶ 表示非三等性,ʵ 表示卷舌性,V₋ 表示任意非前元音,V₊ 表示任意前元音,Vʵ 表示卷舌元音,后文同理):
古典 *CʶV₋- → 切韵 CʶV₋-;
古典 *CʶV₊- → 切韵 CʶV₊-;
古典 *CʶʵV₋- → 切韵 CʶʵVʵ-;
古典 *CʶʵV₊- → 切韵 CʶʵVʵ-。
这意味着什么呢?
这意味着除了「力盧」这个特殊情况之外,古典时期的非三等不卷舌声母与古典时期的非三等卷舌声母一一对应。
走向四分法
好了,古典非三等声母分为「不卷舌」与「卷舌」两类,那么古典三等声母呢?
同样可以分。
为什么?
因为我们在三等这边观察到了不少与非三等类似的现象。
首先,前文已述,「之系」「息系」「子系」与「而系」在非三等有「蘇昨作倉奴徒都他」vs「所士側初女直陟丑」这个严整的对应。而三等也有同样严整的对应:「息疾子七而時之昌」vs「所士側初女直陟丑」。
其次,每个古典韵母在非三等条件下几乎总会分化为「一四等」与「二等」两类;三等的情况虽然复杂得多但同样有类似的事情:分化为「非重纽反切三等或重纽韵图四等」与「重纽韵图三等」两类 [注5]。
最后,对于非三等的情况,古典前后元音对立在「一四等」这一类中往往以「一等」vs「四等」的形式保留下来。对于三等的情况,若声母为钝音,上古前后元音对立在「非重纽反切三等或重纽韵图四等」这一组之中通常能够以「非重纽反切三等」vs「重纽韵图四等」的形式保留下来,而在「重纽韵图三等」这一组重则通常悉数合流了。这句话有点绕,举个例子吧:「亡」「明」是上古陽部字,「名」「鳴」是上古耕部字;「亡」进入切韵「陽」韵,属于非重纽反切三等;「名」进入切韵清韵韵图四等,属于「重纽韵图四等」,而「明」「鳴」均进入庚韵韵图三等且互为同音字,属于「重纽韵图三等」。
(请注意重纽概念仅适用于切韵音系之中的钝音三等声母,即「武符方芳於于許魚渠居去」。对锐音声母讨论重纽是没有良定义的。)


于是我们很愉快地提出以下模型:切韵里的三等声母在古典时期也有「卷舌的」与「不卷舌的」两类来源,「所士側初女直陟丑」和「重纽韵图三等」来源于其中「卷舌的」那一类。
对于「所士側初女直陟丑」,我们并没有遇到什么问题。然而,对于「重纽韵图三等」那一边,我们遇到了一点小麻烦——有那么几个古典韵母(在特定条件下)只能进入「重纽韵图三等」,不能进入「非重纽反切三等」或「重纽韵图四等」:
反切三等、声母为钝音时的古典 *-au → 切韵宵韵韵图三等 [注6];
反切三等、声母为钝音时的古典 *-ai、*-ɔi → 切韵支韵韵图三等;
反切三等、声母为非唇音钝音时的古典 *-əm → 切韵侵韵韵图三等。
难道我们只有 *kʵau、*kʵai、*kʵəm,没有 *kau、*kai、*kəm?这显然是不合理的。
考虑到我们手中同样有一大群「只能进入非重纽反切三等」的上古韵母——比如最基本的:
反切三等、声母为非唇音钝音时的上古 *-ə → 切韵之韵;
反切三等、声母为钝音时的上古 *-a → 开口部分进入切韵魚韵、合口部分进入切韵虞韵。
于是我们最好修改一下我们对切韵音系的理解,把「宵支侵」这些韵目的重纽韵图三等也算作「非重纽反切三等」,这样看起来就与 *-ə、*-a 之流一致了。除此之外其实还有些小细节需要调整,不过限于篇幅,此处就不展开讨论了。
「非重纽反切三等」「重纽韵图四等」「重纽韵图三等」名字太长,而且我们其实也手动调整了定义…为了省事,后文将三者分别称作「反切 3c」「反切 3a」与「反切 3b」。


接下来就是对诸多谐声声母系的逐一分析了。
方系:简单模式
我们首先分析的是情况最简明的谐声声母系:方系。
Step0:筛选出「貌似属于方系」的谐声系。筛选结果如下:
卑甫非分 包比咅番皮辟并扁弗方犮必賁旁畐尃菐孚付賓巿反孛暴弁巴敝不复畢夫半般平朋白丕夆 凡麃發乏丰罷坒 丙卜庳辡伏八復逢否便奉父貝別風封薄豐肥㡀伐保屏本費頻盆彭並匕鼻癹缶樊猋北僕服 步布釆邊氾畀馮飛符崩彬䋣繁潘兵糞阜負部富筆拔搏覆甹煩剽波㔾菲府奮編頗箄背坌駮霸攴溥卞敷扮仌邦羆陂毗鳧 脯浦 芬㞣奔旛漂 彪匪剖 放奰閉沛配吠片表稫匹㪍 匐法皀百琵捕肶渒陪豳棥婆叵芳滂苹洴冰浮排斐釜普䨾倍畚版匾 炰珤紡婦范沸拜備廢叛攀抱 秉罰勃癶鼈泊博帛柏伯蒪雹珀㽬膚 啚 肑驫皅䛣 皕斌
这些字本身以及以这些字为直接声符的字即算作「属于方系」。
Step1:针对所有「貌似属于方系」的字,统计其切韵声母、等位的分布情况。结果如下:
主要声母+等位组合(「符c」表示「声母为『符』,等位为 3c」,「蒲1」表示「声母为『蒲』,等位为一等」,以此类推,后文同理):
符c:393 字,符b:88 字,符a:146 字(符类合计 627 字);
蒲1:275 字,蒲2:152 字,蒲4:76 字(蒲类合计 503 字);
方c:265 字,方b:85 字,方a:145 字(方类合计 495 字);
博1:189 字,博2:118 字,博4:65 字(博类合计 372 字);
芳c:224 字,芳b:42 字,芳a:91 字(芳类合计 357 字);
普1:150 字,普2:77 字,普4:41 字(普类合计 268 字)。
主要声母+等位组合字数合计为 2622 字。
字数至少为 10 的其他声母+等位组合:
莫2:21 字,莫4:4 字(莫类合计 25 字)。考虑到前元音比较罕见,塞音与鼻音偶尔相互借用声符可以理解。
各个声母+等位组合之间的谐声指数如下:
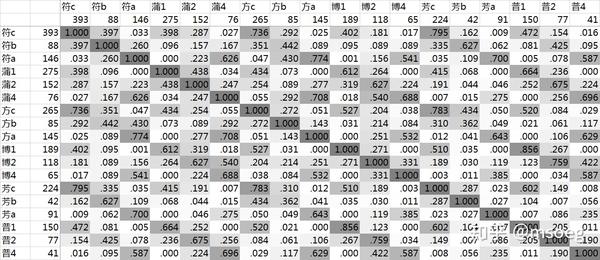

Step2:这张表格里似乎没有什么特别奇怪的现象,直接给出模 型吧(注意有些「理应」进入 3b 甚至 3a 的实际上却进入了 3c [注5],不过为了视觉上的简洁,我们忽略这一点,后文同理):
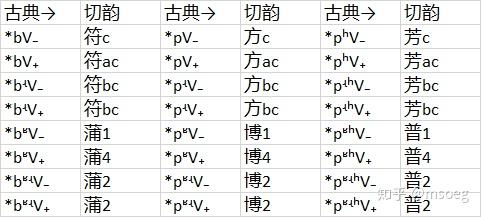

当然表6里还是有一些值得一提的现象的:
0. 首选的谐声关系是同等位条件下的清浊交替,如 *b-、*p-、*pʰ- 相互谐声,*bʵ-、*pʵ-、*pʵʰ- 相互谐声,等等。
1. 次之,则是三等/非三等交替,如 *b-、*bʶ- 相互谐声;以及不卷舌/卷舌交替,如 *b-、*bʵ- 相互谐声。
2. 卷舌三等不常与卷舌非三等谐声,例如 *bʵ- 与 *bʶʵ- 就不怎么谐,谐声指数只有区区 0.157,显著低于 *b-、*bʶ- 之间的 0.398。
武系:走近清响音
接下来是武系。
Step0:筛选出「貌似属于武系」的谐声系。筛选结果如下:
曼莫敄冥麻蔑末免無文蒙㒼每冒民亡毛尨馬米勿微面母眉未昏苗門丏莽矛靡尾某買名罔彌臱少芒舞宓密閔冡 眇貌孟皃覓黑巫弭甍瞢敏墨 武 舋夢瞀麋杗滿務冃茻 娩 亹旄吂盟明悶美吻麼皿蔓眄望楙木 烕䀄縻瓕 綿槾茅忘蝱朙羋姥眯敃愍网岩媚味迷勉戊沐鼏沒脈冪默蠻貿問巟 釁 冖 荒毀㫚薨忽毇火湏牟目牧
这些字本身以及以这些字为直接声符的字即算作「属于武系」。
Step1:针对所有「貌似属于武系」的字,统计其切韵声母、等位的分布情况。结果如下:
主要声母+等位组合:
武c:219 字,武b:96 字,武a:97 字(武类合计 412 字);
莫1:366 字,莫2:124 字,莫4:100 字(莫类合计 590 字);
許c:20 字,許b:6 字(許类合计 26 字);
呼1:71 字,呼2:2 字(呼类合计 73 字)。
主要声母+等位组合字数合计为 1101 字。
字数至少为 10 的其他声母+等位组合:
初2:11 字(初类合计 11 字),全部由「少」谐声系贡献,应当视为偶然的异常数据点。
各个声母+等位组合之间的谐声指数如下:
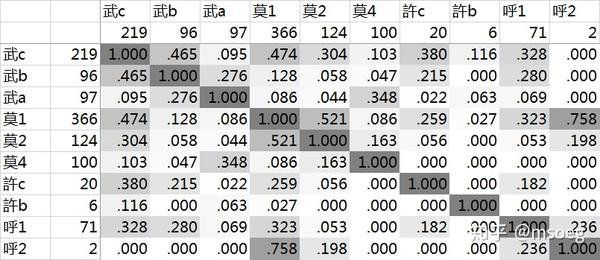

Step2:毫无疑问,这些切韵武、莫声母字的上古声母应该以 *m 为基干。至于这 99 个切韵許、呼声母字,这么个数量的话我们也不好意思无视它们,那就假设它们的上古声母以清鼻音 *m̥ 为基干吧——当然,写成 *hm 也没什么不可以的,反正死无对证。
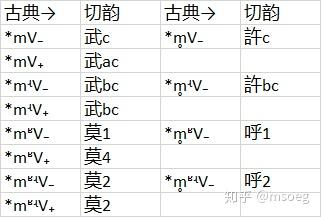
与方系类似,我们同样发现 *mʵ- 与 *mʶʵ- 不怎么谐。不过这里我们多了一项:*m̥- 与 *m̥ʶ- 也不怎么谐,0.182 的指数远低于 *m- 与 *mʶ- 之间的 0.474。
我们没有发现以 *m̥ 为基干的古典声母后接前元音的明确的例子。这可能是因为古典汉语里 *m̥ 本身是一个相当罕见的音素(请注意 *m 有 1002 字,而 *m̥ 只有 99 字,数量上不及前者的十分之一),而主元音为前元音的情况也同样比较罕见,在两个因素的共同作用下,我们可以预期 *m̥ 后接前元音的情况应该只有个位数,再加上一点偶然因素于是一个都不剩也是可以理解的。
当然我们其实也能找出一点疑似属于「*m̥ 后接前元音」的情况。比如,切韵式类声母字「少」可能是个 *m̥ɛuʔ;又比如,切韵息类声母字「戌」可能是个 *m̥ik——但这些个例似乎不足以让我们得出确切的结论。
於系:声符借用
从这里开始就有点难度了。
根据目测,涉及切韵「於」「烏」声母字的谐声系大致分为两类:
0. 几乎仅包含「於」「烏」声母字的谐声系。
1. 包含很多各种各样的声母的谐声系,其中的「於」「烏」声母字的占比通常远小于一半。
结合古典韵母,我们不难发现这两类几乎完全呈互补分布:古典韵母为 *-ai、*-at、*-ap 或者直接与「于」类谐声的「於」「烏」声母字大多属于后一种谐声系,如「阿」「謁」「押」等;相对地,上古韵母不为 *-ai、*-at、*-ap 并且不直接与「于」类字谐声的「於」「烏」声母字大多属于前一种谐声系,如韵母为 *-a 的「於」,*-ak 的「惡」,韵母为 *-an 的「安」,韵母为 *-am 的「奄」等。
显然,合理的结论是:这两类谐声系之中的「於」「烏」声母字的上古声母并没有音位意义上的差异 [注7]。至于音值上的差异…很显然我们也没发现 *-ai、*-at、*-ap 相比 *-a、*-ak、*-an、*-am 有什么语音上的共性,所以音值上的差异大概也是没有的。
那么为什么「阿」「謁」「押」这些字选用了「可」「曷」「甲」这些非「於」「烏」声母字作为声符了呢?
大概是因为…造字者偷懒吧,反正发音部位离得不太远,凑合用也不是不行。
好了,既然结论是『两类谐声系之中的「於」「烏」声母字没区别』,我们不妨直接使用前一类来给它拟音。
Step0:筛选出「貌似属于於系」的谐声系。筛选结果如下:
奄央宛 幼區亞委音奧因烏匽畏雍意厭夭翁於夗安㥯嬰殹要壹垔屋邑燕英尉憂戹弇焉衣愛乙邕 賏酓威冤㫐縕隱阿䧹猒約殷惡晏旖㐆溫幽麀汪盎 翳謁彧鬱 蓲猗伊依彎應妟芺闇医宴窊陰窅洼 瑩禋淵恩煙罃侌哀 㰳枉恚㤅印幺沃一 挹烓苑葯抉娃 薉
这些字本身以及以这些字为直接声符的字即算作「属于於系」。
Step1:针对所有「貌似属于於系」的字,统计其切韵声母、等位的分布情况。结果如下:
主要声母+等位组合:
於c:397 字,於b:66 字,於a:112 字(於类合计 575 字);
烏1:292 字,烏2:124 字,烏4:100 字(烏类合计 516 字)。
主要声母+等位组合字数合计为 1101 字。
字数至少为 10 的其他声母+等位组合:
去c:13 字(去类合计 13 字),其中 11 个由「區」谐声系贡献,应当视为偶然的异常数据点。
各个声母+等位组合之间的谐声指数如下:
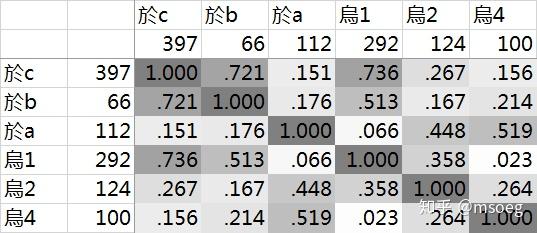

Step2:没啥可讲的,上模型了事:

表11:於系模型。
魚系:前元音的锋芒
魚系的情况与於系差不多:大部分「魚」「五」声母字自谐,小部分与大量其他声母字通谐,两部分呈互补分布。
所以我们依旧只看自谐的那部分。
Step0:筛选出「貌似属于魚系」的谐声系。筛选结果如下:
敖吾兒禺元疑我咢卬業義兀言原吳月獻彥堯嚴豙臬乂厓辥化鬳埶虞宜广艾玉魏五御甗噩魚寓㹞研吟禦嵬瓦毅沂岸獄岳齧猌顡 蓺虐䰻銀昂嵒巖 耦湡藝雁鴈逆鷊蛾虤 牛薛囂鬩羲曉設
Step1:针对所有「貌似属于魚系」的字,统计其切韵声母、等位的分布情况。结果如下:
主要声母+等位组合:
魚c:219 字,魚b:47 字,魚a:10 字(魚类合计 276 字);
五1:197 字,五2:51 字,五4:51 字(五类合计 299 字);
許c:14 字,許b:1 字(許类合计 15 字);
呼1:7 字,呼2:8 字,呼4:12 字(呼类合计 27 字);
而3:14 字(而类合计 14 字)。
主要声母+等位组合字数合计为 631 字。
字数至少为 10 的其他声母+等位组合:
女3:2 字,女2:10 字(女类合计 12 字)。
各个声母+等位组合之间的谐声指数如下:
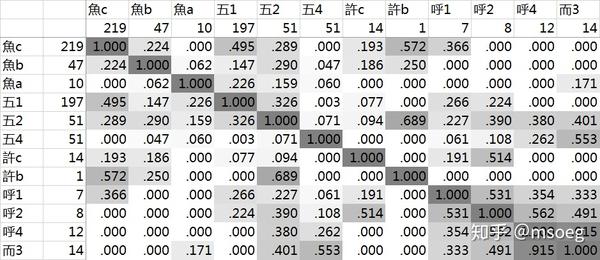

这里面「魚」「五」很好解释,就是软腭/小舌鼻音嘛,和切韵音系一样;「許」「呼」也不难:和武系类似,清鼻音而已。
新现象是冒出来的这 14 个「而」怎么办。
从表12中我们可以发现,「而3」与四等字的谐声指数显著高于「而3」与一等字的谐声指数。在先前的文章中我们已经得出结论:四等意味着主元音为前元音。因此这个现象可以被阐述为魚系之中的「而3」与前元音显著正相关。
当然,仅凭这 14 个字就下这种结论其实很不可靠。后文我们会看到其他软腭音也有类似的现象,而且数量更多,这才能让我们相信这条结论确实「很有可能」是正确的。
Step2:建模。
考虑到魚系之中的「魚a」数量明显偏少(请对比前文「方系」「武系」「於系」之中的 3a 占比),我们有理由相信一些「本应」进入「魚a」的字进入了「而3」。
另外,「許b」的出现次数只有 1 个——这个数量太低了,结合后文「許开」的情况,我们无法确定它是否为规则演化的结果。为了谨慎起见,我们在模型中不体现它。
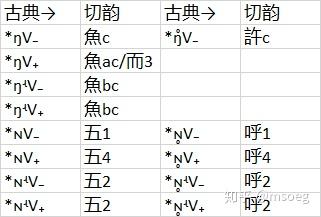
与武系类似,我们没有发现以 *ŋ̊ 为基干的古典声母后接前元音的明确的例子,但有几个疑似情况。比如,切韵式类声母字「燒」可能是个 *ŋ̊ɛu,「勢」可能是个 *ŋ̊ɛs;又比如,切韵息类声母字「褻」可能是个 *ŋ̊ɛt——但这些个例似乎不足以让我们得出确切的结论。
許开、居系与古系:按部就班
为了建模表格视觉上的整齐,我们将「許开」「居系」与「古系」合在一起讨论。
Step0:筛选出「貌似属于这三类」的谐声系。筛选的大原则是声母为「許渠居去胡呼古苦」的字占比超过一半,并且不包含于类声母字以及看起来以胡类合口为主的谐声系。(这一听就很有主观任意性…不过反正不影响结论。)
筛选结果如下(声符真富余…):
句喬奇干其圭吉合卷今交古九亢曷支空去工敫堇巠果幾龹官癸豦匊亥咼屈求厥可夾兼㱿皆告共貴臤危高 既加居雚鬼介廣幵冓 丩巨夸及瞿建盍昆豈君契叚巩畺斤瓜咎贛更敬咸乞骨艮光匡康金甘禁卻己國冋㓞困囷敢過蹇岡氏解固規几歸勘害甲皋狊䀠貫奚見耆戒寒角渠虔堅口局間 劫久 旨隺恆具肩強忌遣鞠尻革亟揭絭葛后倝閒气丂殸欠奎桀㕟臼辜科輕款 欮竟旱虛絜感戈郭客貢匧穹邛 鰥哥家羌竘圈繭賈罽圣 暨 棘完爻井宮骹自乖寇躬蛩綦基芹蘄遽稽冎侃寬乾毌牽 巧庚煢兢丘龜恐 簋耿 楬戟犬 戶臣虍甄㕢蒿㰹苦幹酤匃活旡弓弜頍欺孤笄勤舉腱 翹枷假彊勁扃琴禽庋軌近 簡絹搴覺杲考槀臦厱匱季穀竭窟 䅥缺格虢克梟㕂廾冀夔氣弦歇示江虹 褢亙欽蓋觚匯鯀減雇繫聒決窮 䫏胊鷄佳睽姦褰權痂䶗疆鈞剄仇鉤晷矩鼓啓窘緊袞貇哿㦿凵芰臮㡭魝卦凷恢麇巾郡旰架慶舊曲闕䒷括銽 薊孑屐劇丮馘隔剋急怯蛬帬冠㝁拑戛㾜渴筴侯函善只虎孝圂刑頡萈箴夏黠閑收夰顥後頢欦巷眗嫴䓙苛卿羹芡髸系挈榾 稞竆 䩭罡㝔匛 䂆 究㭝闋希含行喜胡戲休鄉熏翕虖互喙憲奐肴凶幸號脅号匈賢舝歊興十韰赫虫患乎䖒欣何扈下閜斛翯頁亨兮很韓豪汞呴昫顯滈卉恝翰賀枝歆兇紅洪脂軒雈殽河遐衡喉項焊昊禍杏勳學效香縠㕡䦝 睆欻襾皛汵耂銜拾拐
Step1:针对上述谐声系之中的所有字,统计其切韵声母、等位的分布情况。结果如下:
主要声母+等位组合:
許c:256 字,許b:3 字,許a:11 字(許类合计 270 字);
渠c:441 字,渠b:178 字,渠a:67 字(渠类合计 686 字);
居c:439 字,居b:138 字,居a:34 字(居类合计 611 字);
去c:210 字,去b:58 字,去a:54 字(去类合计 322 字);
胡1:499 字,胡2:286 字,胡4:143 字(胡类合计 928 字);
呼1:161 字,呼2:108 字,呼4:32 字(呼类合计 301 字);
古1:590 字,古2:370 字,古4:187 字(古类合计 1147 字);
苦1:334 字,苦2:184 字,苦4:128 字(呼类合计 646 字);
式3:16 字(式类合计 16 字);
時3:35 字(時类合计 35 字);
之3:76 字(之类合计 76 字);
昌3:10 字(昌类合计 10 字)。
主要声母+等位组合字数合计为 5048 字。
字数至少为 10 的其他声母+等位组合:
於c:24 字,於b:11 字,於a:4 字(於类合计 39 字);
烏1:57 字,烏2:50 字,烏4:11 字(烏类合计 118 字);
魚c:46 字,魚b:16 字(於类合计 62 字);
五1:47 字,五2:36 字,五4:24 字(五类合计 107 字)。
如前所述,这些散字与「於系字」和「魚系字」呈互补分布,应为「声符借用」的结果。
以3:12 字,分布比较零散,疑似 *KL 型复辅音的产物,详见后文对「以系」的讨论(那里数据量会大很多)。
蘇1:8 字,蘇4:4 字(蘇类合计 12 字),其中「蘇1」的 8 字全部都来自「及」谐声系的贡献,应当视为孤例。
所3-:7 字,所2:5 字(所类合计 12 字),分布比较零散,疑似 *KR 型复辅音的产物,详见后文对「力系」的讨论(那里数据量会大很多)。
力3:12 字,力2:1 字(力类合计 13 字),其中「力3」有 7 字来源于「兼」谐声系的贡献,似乎可以视为孤例;但同时也有 *KR 型复辅音的嫌疑。
盧1:18 字,盧4:9 字(盧类合计 27 字),分布比较零散,同样疑似 *KR 型复辅音的产物。
都1:12 字,都4:1 字(都类合计 13 字),分布比较零散,难以解释。
他1:14 字,他4:3 字(他类合计 17 字),分布比较零散,疑似 *KL 型复辅音的产物。
各个主要声母+等位组合之间的谐声指数如下:
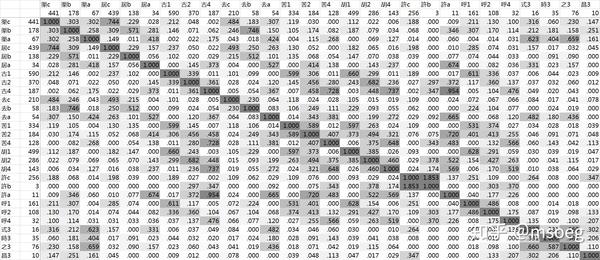

Step2:建模。
表14与表3的情况差不多:「許」自成一簇且与「式昌」关系密切;「胡呼古苦」为一簇;「渠居去」为一簇且与「式時之」关系密切。根据上述聚簇现象,我们不妨把「許」拟成通音 *h-,把「渠居去」拟成软腭音,把「胡呼古苦」拟成二者之外的某种东西——南北朝及更早的梵汉对音里,梵语软腭音一向通常以「渠居去」而非「胡呼古苦」来对,在缺少其他偏向性证据的情况下,最合理的做法必然是把从梵汉对音中得到的「(仅有)渠居去=软腭音」这条结论照抄到上古音里。
与「魚系」之中的「而3」类似,这里的「式3」「時3」「之3」同样显现与前元音之间的显著相关性(这里主要是 3a),但「昌3」则没有。与此同时,我们也观察到「許a」「渠a」「居a」数量明显偏少的现象,但「去a」则没有。
结合后文对「以系」的分析,我们认为这些「昌3」之中有相当一部分并非来源于腭化,而是疑似 *KL 型复辅音的产物。
还有一个很明显的现象是「許b」缺字——相对地,「呼2」就不缺字。考虑到「許开」自称一套,不与「渠居去」相谐声的倾向,我们有理由相信「許」在谐声时期发音部位不同于软腭音,是个 *h-。这样一来「許b」就「应该」是个 *hʵ-。我们将在后文尝试给出针对「为什么几乎不存在 *hʵ-」这个现象的一个可能的解释。
具体模型如下:


如果仔细审视这些谐声系之中「許a」「渠a」「居a」vs「式3」「時3」「之3」所能后接的韵母,我们可以发现从 CV₊ 到这两类字的分化并不是完全随机的,实际上与韵尾显著相关:韵尾越靠前,演化进入「式3」「時3」「之3」的概率就越大。不过限于篇幅,这里就不再展开讨论了。
至于我们为什么把「胡」拟成了塞音而非擦音…一方面是参考了非常早期的外语对音(用胡类字对译外语浊塞音),另一方面也是因为其他几个塞音/塞擦音谐声系里都没有看起来像是来自于浊擦音的部分,与此相对地,它们都有浊塞音/浊塞擦音。把「胡」也拟成浊塞音的话,整个体系看起来会比较整齐。
至于我们为什么认为此时的「胡呼古苦」已经是小舌音了…其实我们并不能确定这些字必定是小舌音,我们所能确定的只有「它们和『渠居去』之间有着可观的语音距离」。
为什么这么讲呢?
在方系那里,我们发现三等/非三等交替(如 *b-、*bʶ- 相互谐声)与不卷舌/卷舌交替(如 *b-、*bʵ- 相互谐声)的谐声指数差不多。相对地,在居系与古系这里,三等/非三等交替的谐声指数显著低于与不卷舌/卷舌交替的。
按照常理,「不卷舌 vs 卷舌」这个特性对于唇音与软腭音来说,拉开的语音距离似乎应该差不多。唇音那里三等/非三等交替与不卷舌/卷舌交替的谐声指数相近,意味着「三等 vs 非三等」这个特性对于唇音来说,拉开的语音距离应该与「不卷舌 vs 卷舌」相近;软腭音这里三等/非三等交替的谐声指数显著低于不卷舌/卷舌交替的,意味着「三等 vs 非三等」这个特性对于软腭音来说,拉开的语音距离显著大于「不卷舌 vs 卷舌」的。进而,关于「三等 vs 非三等」这个特性,对于软腭音来说所拉开的语音距离应当显著大于对于唇音来说的。
为了体现出这个差异来,我们姑且将传世谐声音系里的「居 vs 古」这个对立仍旧记作 *k- vs *q-,使二者之间的距离看起来好像大于「符 vs 蒲」的 *b- vs *bʶ-。
另外我们也可以发现「呼」与「古」之间经常相互谐声,而「許」与「居」之间就很不经常相互谐声。把「胡呼古苦」记作小舌音也有利于解释这一点:*h- 与 *k- 离得比较远,但 *hʶ- 几乎就等于 *χ-,自然与 *q- 比较接近。
于系:触类旁通
这一团乱麻之中最后讨论的是于系。
Step0:筛选出「貌似属于于系」的谐声系。筛选的大原则是该谐声系中包含于类声母字,或者看起来好像以胡类合口为主。(真·突破天际的主观任意性…当然确实不影响结论,「以胡类合口为主」并且完全不包含于类声母字的谐声系真心不多。)
筛选结果如下:
韋員于有胃或云爰爲戉軍尤袁禹羽衛圍右 彗雲永又曅亘㞷王矍盂往榮蔿遠囿均穴雩 越宇芸籰睘皇厷維汙昱吁運狂蒦巂旬玄肙黃歲宣旋役矞會畫華血惠隹禾丸褱回弘訇睢霍夬敻兄勻縣睿砉唯黊晃慧叡虺橫紆䰟還和瓠頃翬壺 荀䜭靴宏滎筍迥熒洫淮檈荂壞繯栒囧潁惑桂灰
Step1:针对所有「貌似属于于系」的字,统计其切韵声母、等位的分布情况。结果如下:
主要声母+等位组合:
于c:240 字,于b:73 字(于类合计 313 字);
許c:89 字,許b:17 字,許a:32 字(許类合计 138 字);
於c:40 字,於b:3 字,於a:11 字(於类合计 54 字);
渠c:18 字,渠b:1 字,渠a:12 字(渠类合计 31 字);
居c:28 字,居b:6 字,居a:17 字(居类合计 51 字);
去c:6 字,去b:2 字,去a:9 字(去类合计 17 字);
胡1:156 字,胡2:108 字,胡4:90 字(胡类合计 354 字);
呼1:30 字,呼2:40 字,呼4:32 字(呼类合计 102 字);
烏1:27 字,烏2:15 字,烏4:16 字(烏类合计 58 字);
古1:40 字,古2:23 字,古4:49 字(古类合计 112 字);
苦1:10 字,苦2:9 字,苦4:3 字(苦类合计 22 字);
以3:75 字(以类合计 75 字);
徐3:51 字(徐类合计 51 字);
息3:54 字(息类合计 54 字)。
主要声母+等位组合字数合计为 1432 字。
字数至少为 10 的其他声母+等位组合:
之3:11 字(之类合计 11 字),其中有 9 字由「隹」谐声系所贡献,应当视为孤例。
一部分主要声母+等位组合之间的谐声指数如下:
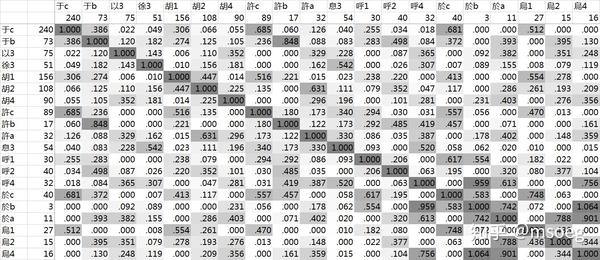

Step2:建模。
与「魚系」之中的「而3」类似,这里「以徐息」均与前元音有显著的相关性。
但是有一点与「魚系」很不一样:魚系之中只有「而」与前元音显著相关,正好可以填补「魚a」的空位。但在于系这里,我们「以徐息」是三个声母,却只有「于a」一处空位。
怎么办呢?
我们盯了一会儿表格,发现了这样一个现象:「以3」与「徐3」之间的谐声指数出奇地低:只有 0.143——这也就意味着大多数相关的谐声系里要么只有「以3」,要么只有「徐3」,二者共存的情况不多。
于是焉我们扫了一眼谐声系,嗯,侧重「以3」的谐声系有「 維昱巂役矞睿唯頃」,侧重「徐3」的谐声系有「彗睘旬旋叡還」。
这画风好像有点眼熟…
前面我们不是刚说过这么一句嘛:『韵尾越靠前,演化进入「式3」「時3」「之3」的概率就越大。』
于类这个情况怎么看都有点类似:韵尾越靠前,演化进入「徐3」的概率就越大。
那么好了,我们不妨照葫芦画瓢,认为于系之中的「以3」与「徐3」都来源于同一个 CV₊,二者之别是 CV₊ 半随机半条件分化的结果。
解决了「以3」vs「徐3」,我们再来看「息3」。
根据直觉,「許a」与「息3」之间的关系应该比较类似于「以3」与「徐3」之间的关系。
于是我们瞥了一眼「許a」与「息3」之间的谐声指数。嗯,0.330。
……真是个微妙的数值。
不过其实也还好,「許a」确实与「以3」更相近(0.329),「息3」也确实与「徐3」更相近(0.542);进入「息3」的字的韵尾也同样往往比进入「許a」的更靠前。这样看来「CV₊ 半随机半条件分化」这个模型姑且还是能凑合用的。
至于其他模型,比如不知为何在学术界到处流窜的 *sw- 说——
——嗯只要他们能解释清楚 *swV₋ 都哪里去了,我保证不打死他们。
不管他们了,我们的模型具体如下表(仅列出主要部分):
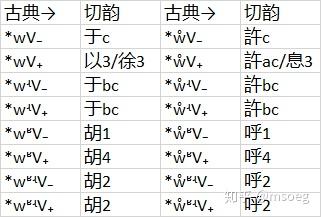
其他主要声母均可拟为相应的 KW 型复声母,例如于系之中的於类 3c 字可以拟为 *ʔw-,古类一等字可以拟为 qw- 等等(胡类就比较尴尬:对于一个谐声上属于「于系」并且切韵时期声母为「胡」的字,我们很难判断其具体来自 *wʶ- 还是 *ɢw-),现于篇幅这里就不展开来罗列了。
不过有一点还是值得一提:「于系」之中几乎没有切韵「魚」「五」声母字。这也就意味着谐声时期存在大量 *k-、*q-,存在大量 *ŋ-、*ɴ-, 存在大量 *kw-、*qw-,但唯独几乎不存在 *ŋw-、*ɴw-——而根据上一篇文章,韵尾出的情况也明显类似:存在大量 *-k,存在大量 *-ŋ,存在大量 *-uk,但唯独不存在 *-uŋ。
于系之中的清音声母字占比远大于前文武系、魚系,以及后文而系、力系。这可能是因为其中有相当一部分「本应」为 *hw- 吧——语音学上 *hw- 与 *ẘ- 之间的距离太小,难以形成稳定的对立,因此全都被算入 *ẘ- 了。
息系、子系:短暂的宁静
这两系就合在一起讲吧…反正也没什么人关心,分开来讲反而一堆麻烦事。
Step0:筛选出「貌似属于息系或子系」的谐声系。这个筛选委实容易得很,也就「息」「所」来源比较杂,需要注意一下。
筛选结果如下(不得不承认咝音的声符也很富余):
此且差齊戔卒青朁乍昔責贊取焦曾從芻參夋斬毚㚇秋坐喿 尊爭悤曹巢全倉即虘前叟巽戚次足疌截崔韱宗將臿祭甾酋束欶才兹最 咠朿雋妻則肅沙先爿算蚤左親星散壯采爵集叉孱肖妾秦存族就桼資子盡聚 疾節屑戢 千毳思爪切 生畟西晉楚苴薦素奏爽產刪析宰作 孫 造漸耤尐帀䪞七斯索牆从沮罪錢翠蔡賊粲脊 遷冊 崇蔥哉進寸 愁湔桑絕 札雜助兓宋鬵岑孨尗朔衰囟浸槧藂囪㭰咨在租查喪臧茈棧草侵事倩鼀措卩昨燮 辛心俊泉 慈鉏穌麤齎柴栽殘座瀸賤酒佐娑篸三辠纂洗操㕚 積刺字蔖窄藉匠靚速燋 仄戕塞察夨歺卂疋殺悉舄小 歰㦰嫂篡策叢窻貲麁犀齏豺榛飧酸爨歬牋箋津蕭樵蕉 莝挱桫柤旍蠶摠士雀祖再剪潐澡皁葬竄軐峭 遬㲺刹 羴胥嗇省鮮彡削夙箑厀禼慼豩 汊 簽徙須息山相宿雙師戌疏霜選寫粟厶簁新莘 捎稍 私絲仙陖膝溲
Step1:针对所有「貌似属于息系或子系」的字,统计其切韵声母、等位的分布情况。由于切韵之前刚刚发生了通称「莊三化二」的过程(参见 「庄三化二」是什么?),相当一部分原生反切三等音节与原生反切二等音节合流了,在切韵之中基本上一律统一处理为反切二等。对于这种合流的情况,很多时候我们都无从推测某一个字究竟是原生反切三等,还是原生反切二等,我们不作区分,统一记作「所2」等等。而另一部分原生反切三等音节并没有与任何反切二等音节相合流,因而在切韵之中通常仍然沿用其他反切三等字充当该音节的反切下字——但实际上「莊三化二」也已经发生了,只是下字实在没得选而已。对于这类音节,我们为了方便起见,一律记作「所3-」等等。
统计结果如下:
主要声母+等位组合:
息3:284 字(息类合计 284 字);
疾3:262 字(疾类合计 262 字);
子3:436 字(子类合计 436 字);
七3:291(七类合计 291 字);
蘇1:266 字,蘇4:116 字(蘇类合计 382 字);
昨1:229 字,昨4:50 字(昨类合计 279 字);
作1:257 字,作4:70 字(作类合计 327 字);
倉1:199 字,倉4:74 字(倉类合计 273 字);
所3-:151 字,所2:189 字(所类合计 340 字);
士3-:78 字,士2:148 字(士类合计 226 字);
側3-:127 字,側2:99 字(側类合计 226 字);
初3-:92 字,初2:127 字(初类合计 219 字)。
主要声母+等位组合字数合计为 3545 字。
字数至少为 10 的其他声母+等位组合:
以3:12 字(以类合计 12 字),其中有 9 字由「酋」谐声系所贡献,应当视为孤例。
式3:11 字(式类合计 11 字),分布很是零散,不好解释。
之3:10 字(之类合计 10 字),与式类情况一样,分布很是零散,不好解释。
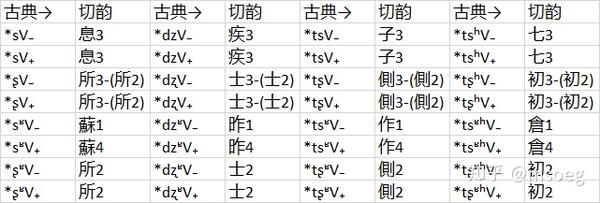
各个主要声母+等位组合之间的谐声指数如下:
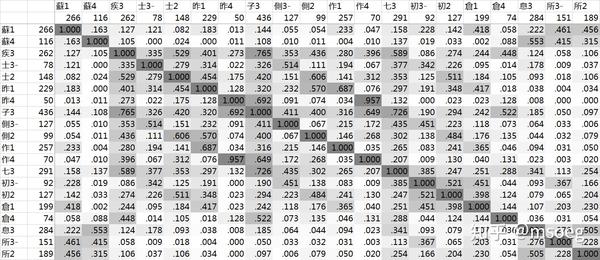

与最初「粗略观察」的结论类似,「疾子七昨作倉士側初」为一簇,「息蘇所」为另一簇,并且后者时常与「七倉初」相互谐声。
我们是否能够把「七倉初」分为两类,其中一类与「疾子昨作士側」谐声,另一类与「息蘇所」谐声呢?
我们确实能够勉强做到这一点,但代价就是多出来一大堆例外——不管怎么说,「息蘇所」与「疾子昨作士側」之间的谐声指数也并不很低。
更麻烦的事情在于分出来的这两类「七倉初」几乎完全呈互补分布,相互之间基本没有最小对立对——这明显暗示分出来的这两类「七倉初」属于同一个音位。
那我们还是老老实实地把这种互补分布的东西理解为同一个音位比较好,就像我们先前对「自谐」vs「借用居系或古系声符」的「於烏」以及「魚五」所做的那样。
Step2:建模。

之系:多出来的尾巴
然后是之系。
Step0:筛选出「貌似属于之系」的谐声系。至于筛选标准嘛…没有严格的标准,之系与以系长得太像了(汉藏传统艺能)。实际操作中大概就是看这个谐声系里是「時之陟都」比较多呢,还是「以徐食式」,如果比较多的那一方是「時之陟都」就算作「之系」。
筛选结果如下:
叕氐占丁旦東者勺啇冘登至乇單周當真豖耴耑朱帶出朵亶是詹壽長 主豆 卓執帝致刀䙷鳥蜀重垂追貞舟窒甚冬尚中宁著對荅知弔疐竹展答屯折敦叔屬黨定斗奓鼎到召專直 典殳段沾豬顛徵啻張石質宅斷智肘託奼筑箸涷夂都端䆸兜董轉窡寺㐱舂臺毒奠適殿侈 朝 坫惪鼅凋冢島釣斲督篤得馽耷刁罬童辰正度土亭廛制屠蚩叀㡯棠涉橐磴柱壴誰丹陟 䈞 庶章戠春堂昌成充止丞諸州敞之時尌 眾商升丈志筮受泜踶帚牚烝爯雔 慸孰鄭推終巵圌儲廚純旃佋賞滯奢紂憧署振盛織識沼水動隼霅忡鍾魋芚甞常氶讎 㣫杜陮肫闡邵 政黈寘馵稕昭焯宕塾殄斫淑帖㞢晨䒱注祝龸䓯灼欼席
Step1:针对所有「貌似属于之系」的字,统计其切韵声母、等位的分布情况。结果如下:
主要声母+等位组合:
式3:57 字(式类合计 57 字);
時3:297 字(時类合计 297 字);
之3:473 字(之类合计 473 字);
昌3:154 字(昌类合计 154 字);
徒1:266 字,徒4:132 字(徒类合计 398 字);
都1:378 字,都4:218 字(都类合计 596 字);
他1:114 字,他4:58 字(他类合计 172 字);
直3:215 字,直2:63 字(直类合计 278 字);
陟3:275 字,陟2:107 字(陟类合计 382 字);
丑3:84 字,丑2:29 字(丑类合计 113 字)。
主要声母+等位组合字数合计为 2920 字。
字数至少为 10 的其他声母+等位组合:
以3:19 字(以类合计 19 字),分布相当零散,不好解释。(好吧实际上就是汉藏传统艺能——*T *L 一家亲而已。)
胡1:8 字,胡2:1 字,胡4:1 字(胡类合计 10 字),分布相当零散,不好解释。
居c:4 字,居b:7 字,居a:1 字(居类合计 12 字),其中有 6 字由「叕」谐声系贡献,有孤例的嫌疑。
女3:9 字,女2:6 字(女类合计 15 字),所涉及的谐声系往往有一个比较罕见的韵母。与「方系」之中用的武、莫类字类似,在选择空间受限的情况下,塞音与鼻音偶尔相互借用声符可以理解,毕竟鼻音字少,经常缺乏可用的声符。
各个主要声母+等位组合之间的谐声指数如下:
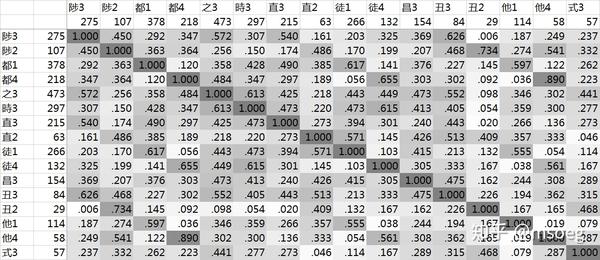

Step2:建模。
「時之昌直陟丑徒都他」的情况好办:齿音塞音清浊三分,三等不卷舌进「時之昌」,非三等不卷舌进「徒都他」,卷舌的一律进「直陟丑」。这没什么难度。
但是,表20之中还有一个「式3」…57 个字呢,算是相当可观的数目了。
依照前文的经验,我们特别希望它是一个常规的上古声母的「半随机半条件分化」产物——然而表20击碎了我们的幻想,
首先,「時之昌直陟丑徒都他」都不缺字 [注8]。
其次,式3并没有与某个声母特别不谐声或者特别谐声的倾向——它与「時之昌直陟丑徒都他」这九个声母谐声指数都差不多。
顺带地,它与一四等的谐声指数也差不多——这意味着它与「前元音 vs 非前元音」这个维度也没有什么相关性。
一点头绪都没有。放弃治疗暂记为 *θ- 算了——至于其具体音值,嗯,天知道。

而系:疑似真·随机分化
至于而系的情况嘛…并没有比之系更好。
Step0:筛选出「貌似属于而系」的谐声系。这个倒是好容易得很,原则上来讲,凡是涉及「而奴女」并且看起来不像魚系的,就都算而系。
筛选结果如下:
農內奴寧尼耎丑念難南 襄圼辱聶爾能匿需冉妥如弱熯而柔若然女挐那薾褭囊奈泥柰㘝耳任尒夒乳狃刃乃日年寍恧抐納袲絮㞋釀 苶苨甯䏔涅帇戎忍芮貳肉入茸壬甤閏宂染惢二獮 璽身人肰仍叒歎羞聃退手替夊㼱橤媷
Step1:针对所有「貌似属于而系」的字,统计其切韵声母、等位的分布情况。结果如下:
主要声母+等位组合:
息3:37 字(息类合计 37 字);
式3:21 字(式类合计 21 字);
而3:365 字(而类合计 365 字);
奴1:180 字,奴4:90 字(奴类合计 270 字);
女3:110 字,女2:65 字(女类合计 175 字);
他1:27 字,他4:3 字(他类合计 30 字);
丑3:12 字(丑类合计 12 字)。
主要声母+等位组合字数合计为 910 字。
字数至少为 10 的其他声母+等位组合:
呼1:13 字(呼类合计 13 字),其中有 7 个由「熯」谐声系所贡献,有孤例的嫌疑。
各个主要声母+等位组合之间的谐声指数如下:
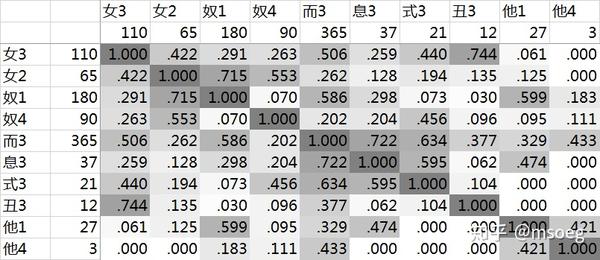

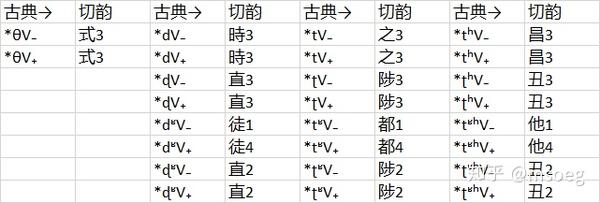
Step2:建模。
「而奴女他丑」这几个都好办,「而奴女」拟成鼻音,「他丑」拟成清鼻音就行。
麻烦的是「息」「式」这两个——看起来二者都理应来自「三等不卷舌」的古典声母。
于是我们又瞥了一眼表20,发现这么一个现象:「式3」似乎不怎么与一等字谐声,而「息3」就来者不拒,与一等四等都谐。
这似乎意味着 *n̥V₋ 必定进入息3,而 *n̥V₊ 会随机进入息3或式3 [注9]。由于字数太少,我们难以判断其中是否有更细致的分化条件。

力系:不平衡的清音
终于讲到力系了。
Step0:筛选出「貌似属于力系」的谐声系。这个难度不大。
筛选结果如下:
婁令尞龍翏粦良來畾盧彔巤列各麗侖留䜌累樂夌寽監利連勞厲京离闌霝力鹿戾栗卯僉林羅歷里柬剌廉慮賴劉立 離蠡黎坴羸靈 兩旅耒呂稟隆虜牢零㐬弄路厤斂鹵聮閭郎隷豊雷吝蓼磊覽類屚 劦鬲梨聊 領臨厽魯閵 率萬量霤卵橑老 荔蘭料閬淥祿律㗉仂頪位了壘詈欒遼戀狼聆淩陵流 櫐縷絫礼輦婪屢輅露藺倫㪝莨陸錄犖略洛笿秝勒阞拉 品䰘㐭 亂刅濫漻 吏帥 㔷浝㤻苙降貍膠夅畜瑟敕數史刷所㕞㨨埋嬐剝景
Step1:针对所有「貌似属于力系」的字,统计其切韵声母、等位的分布情况。结果如下:
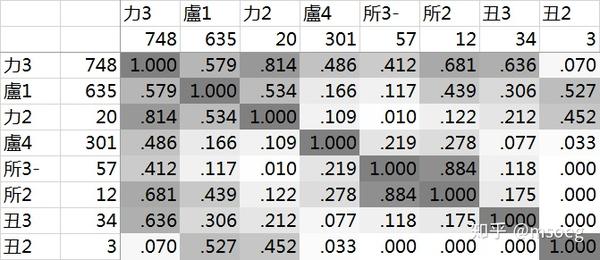
主要声母+等位组合:
所3-:57 字,所2:12 字(所类合计 69 字);
盧1:635 字,盧4:301 字(盧类合计 936 字);
力3:748 字,力2:20 字(力类合计 768 字);
丑3:34 字,丑2:3 字(丑类合计 37 字)。
主要声母+等位组合字数合计为 1810 字。
字数至少为 10 的其他声母+等位组合:
莫1:2 字,莫2:19 字,莫4:1 字(莫类合计 22 字);
普1:3 字,普2:8 字(普类合计 11 字);
以3:10 字(以类 10 字);
許c:17 字,許b:7 字,許a:1 字(許类合计 25 字);
胡1:11 字,胡2:29 字(胡类合计 40 字);
呼1:8 字,呼2:5 字,呼4:1 字(呼类合计 14 字);
古1:11 字,古2:57 字,古4:2 字(古类合计 70 字);
魚c:1 字,魚b:9 字(魚类合计 10 字);
渠c:8 字,渠b:7 字,渠c:4 字(渠类合计 19 字);
居c:8 字,居b:10 字,居a:1 字(居类合计 19 字);
直3:7 字,直2:3 字(直类合计 10 字)。
各个主要声母+等位组合之间的谐声指数如下(「莊三化二」这事参见前文息系、子系):

Step2:建模。
这个谐声声母系颇有一点意思。
与「武系」「魚系」「而系」这三个谐声声母系类似,从字数上来看,几个切韵浊音声母占据了绝大部分比重,而每个除此之外的其他切韵声母的占比基本上都要小上一个数量级。
但是,与「武系」「魚系」「而系」的「三等/非三等」×「不卷舌/卷舌」这种四分均备的格局截然不同,力系这里严重偏科:我们几乎只有「理应为三等×卷舌」的「力3」,以及「理应为非三等×不卷舌」的「盧1」与「盧4」——几乎只有这两种组合。
问题出在哪里了呢?
我们发现这样一个现象:在这个谐声声母系中,除了「力3」「盧1」「盧4」之外的绝大部分字都有卷舌性——我们有 69 个「所」,37 个「丑」,57 个「古2」,29 个「胡2」,19 个「莫2」,等等。
这些字——特别是其中的反切二等字——强烈暗示「盧1」与「盧4」「本应也是反切二等字」。
为什么这么说呢?
我们发现力系的情况和于系有点像,都有一大堆「非三等的杂牌声母字」。
于系之中数量最大的非三等声母是「胡」,于是我们把「胡」都拟成 *wʶ-;力系这里数量最大的非三等声母是「盧」,我们显然得把它们拟成个什么,姑且假设为 *Xʶ- 吧。
在「于系」里我们为这些非三等杂牌声母字构拟了 *Cwʶ- 这种形式的复辅音,那么在这里我们自然也应该把「力系」里的这些非三等杂牌声母字也拟成 *CXʶ- 的样子。根据前文所总结的现象,这些 *CXʶ- 大部分是卷舌的,或许写成 *CXʶʵ- 更合适一点。
假如这个 *Xʶ- 没有卷舌性——比如 *lʶ- 吧,我们就会遇到一个非常麻烦的问题:我们明明有不少的 *Cɭʶ-,为什么几乎没有单独的 *ɭʶ- 呢?
我们不想为这个麻烦的问题找借口,于是直接认定「*Xʶ 本身就有卷舌性」了事。
卷舌这个地界上最常见的持续音(力系怎么看都应该是个持续音)有两个:闪音 *ɽ- 和近音 *ɻ-。现有证据在二者之间并没有偏好。
那么好吧,为了形式上的整齐,我们选择了以近音符号 *ɻ- 来表示它——因为 w 也是近音符号嘛。
于是焉,三等的 *ɻ- 进「力」,非三等 *ɻʶ- 进「盧」,问题解决。
然后清音那边后院起火了——具体地说,清音三等的 *ɻ̊- 似乎既可以进「所」也可以进「丑」。清音非三等倒是问题不大,因为几乎没字——那 12 个「所2」几乎都是很明显的「莊三化二」产物,大部分字都有「所3-」的异读。
单从表 24 来看,似乎有「前元音更容易进所类,非前元音更容易进丑类」的倾向,但规律性比较弱,至少后元音那边还是直接写「随机分化」比较稳妥。
另外,这个模型顺便还解决了前文所提出的「为什么几乎不存在許开b」这个问题:許开b「理论上应该是」个 *hʵ-,与 *ɻ̊- 过于接近,难以形成有效对立,于是焉全都被当成 *ɻ̊- 来处理,使用力系声符来表音了。

其他声母就比较麻烦了。理论上来说,反切二等字、反切3b 以及相当一部分反切3c 均可拟为 *Cɻʶ- 与 *Cɻ-,例如「莒」*kɻaʔ。剩下的那些我们确实没什么好办法。考虑到这些谐声系里同样出现了 10 个以类字,我们不妨把「剩下的那些」连同这 10 个以类字一概扔进「以系」里去——虽然这怎么看都像是在甩锅。
至于这些 *Cɻ- 与「普通的」*Cʵ- 有没有区别,我只能说,有区别的概率不高,但姑且还是有的。(所以,说实话,按照我自己的原则,我应该把它们一概记作 *Cʵ-。)
以系:最终 BOSS
最后剩下的是以系。
Step0:筛选出「貌似属于以系」的谐声系——总之就是「最后剩下」的都算在内了。(好吧其实如前文「之系」那里所述,实际操作中大概就是看这个谐声系里是「時之陟都」比较多呢,还是「以徐食式」,如果比较多的那一方是「以徐食式」就算作「以系」,不过也有一些杂七杂八其他来源的,嗯。)
筛选结果如下(这个声符也相当富余):
俞與昜羊也䍃余睪延寅予龠夷弋庸申容臾由台兌引象施異枼多甬習世 炎易遂繇覃曳尋以朕育允巳谷黽隋攸司式閻遺舍射兆它失盾扇公川翼羨酉乘兗夜翟彖秀移養尸㕣嬴衍 朮矢盈耶鹽燅亦聿虒臽㒸㸒貰尹㳄斜斿 深食囚向益牙呈舀隨隊首㬎歈舜審脣歋旟欲庾 緣邪楊夤梄㚒閃預籥裔葉羕恙勝守儵夕猶隶松荼 銚赤䦲㣇侻飤巸融用彝舒渝鳶汓淫涌与黍鼠敘㼌异羑宷陝戍胤筄豔毓倏室閱蘥藥弈赦奭翌芽焱粥 䏌羔匋湯蟲淡沈灷雉窬撢剡㶣聖迪潭剔車浧榆涗隓舌龖煔 嘼述野孴矣同廷弟唐沓大田屖突斥除達條逐隤代戜狄四騰兔 忝 曡治涂怠炭禿脩眔遝恬祟陳 䍧滕 道逮闒天 霆聽修䑣豚惰賜 太䊮碭濯擇貣貪炊彘屰通彤厗稊㔸頹甸庣他抽曇蕁待枲舛陀醜窞䏙闖甜簟肆笑畼鬯擢 㲋澤尺 牒臭午 途仝卸胄 許串俟
Step1:针对所有「貌似属于以系」的字,统计其切韵声母、等位的分布情况。结果如下:
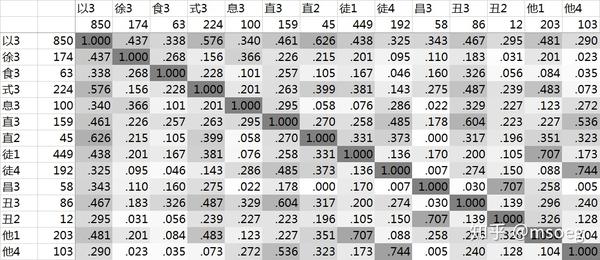
主要声母+等位组合:
以3:850 字(以类合计 850 字);
徐3:174 字(徐类合计 174 字);
息3:100 字(息类合计 100 字);
食3:63 字(食类合计 63 字);
式3:224 字(式类合计 224 字);
昌3:58 字(昌类合计 58 字);
徒1:449 字,徒4:192 字(徒类合计 641 字);
他1:203 字,他4:103 字(他类合计 306 字);
直3:159 字,直2:45 字(直类合计 204 字);
丑3:86 字,丑2:12 字(丑类合计 98 字)。
主要声母+等位组合字数合计为 2718 字。
字数至少为 10 的其他声母+等位组合:
於c:1 字,於a:13 字(於类合计 14 字);
烏1:8 字,烏2:12 字,烏4:2 字(烏类合计 22 字);
許c:20 字,許b:4 字,許a:11 字(許类合计 35 字);
胡1:10 字,胡2:7 字,胡4:3 字(胡类合计 20 字);
呼1:6 字,呼2:10 字,呼4:13 字(呼类合计 29 字);
五1:14 字,五2:17 字,五4:2 字(五类合计 33 字);
古1:12 字,古2:2 字,古4:2 字(古类合计 16 字);
苦1:8 字,苦2:6 字,苦4:2 字(苦类合计 16 字);
蘇1:11 字,蘇4:16 字(蘇类合计 27 字);
七3:10 字(七类合计 10 字);
時3:25 字(時类合计 25 字);
之3:29 字(之类合计 29 字);
盧1:12 字,盧4:3 字(盧类合计 15 字);
陟3:7 字,陟2:4 字(陟类合计 11 字)。
各个主要声母+等位组合之间的谐声指数如下:

Step2:建模。
这模简直没法建。跟其他谐声系一比,以系的语音分布太诡异了:「三等不卷舌」的声母一大串:「以徐息食式昌」,无论哪个字都很不少。
要说仔细看看的话,我们发现「息」这个声母有个特点:倾向于与四等字谐声。相对地,其他几个全都更倾向于与一等字谐声。不过这个现象是否有效很是存疑:它基本上完全是由「虒」这一个谐声系所贡献的,怎么看都像是孤例。
那只好再仔细看看了——于是焉我们又发现「昌」这个声母好像也有点特点:相对不与卷舌声母相互谐声,并且经常牵涉到前文所述的「其他声母」。不过考虑到「昌」这个声母辖字有点太少了,这两条谐声现象在统计上也不太显著,「昌」是否特殊仍然是存疑的。
至于浊音那边(也就是「以徐食」这三个),横竖看了半天,真是什么都看不出来。这三个声母相互之间的谐声可谓相当的密切,而且在与哪些其他声母更容易相互谐声的量化表现上也相差仿佛,除了「徐」爱与「息」相互谐声这一点以外,没有多少统计上足够可靠的区别现象。
那怎么办呢?没什么好办法。我们大概只能付诸目治之别了。
与「于系」和「力系」类似,以系之中也包含一大堆「杂牌声母字」,我们似乎也应该给它拟一个近音作为基干。从「以系」之中辖字最多的两个声母是「以」和「徒」二者来看,这个近音最好是个 *l-。
这个拟音对解释另一个现象比较有利:该谐声声母系之中清音的占比显著高于除「于系」之外的所有其他响音谐声声母系。具体地,武系、魚系、而系、力系之中的清响音占比都在 10% 以下,但以系之中的清音占比差不多在 30% 左右。以系的基干拟成 *l- 的话,这些清声母可以拟作相对常见的 ɬ——不过为了形式上的整齐,我们仍旧将其记作 *l̥-。
至于其他声母字,拟成 *Cl- 就行了。虽说在传世谐声时期估计已经开始大批量地挂进 *C- 了。(什么,你说許类字写 *hl- 不合适?那就写成 *l̥₄- 嘛。)
谐声分析的局限性
做完上文这一大段漫长的分析,我们不得不承认它从方法上就有着诸多明显的局限性。由于对照材料的匮乏,很难讲这段分析所给出的模型能够在多大程度上贴合所谓「古典汉语」的实际情况。
首先,谐声分析在原则上只能达到「谐声系」的分辨率,至于谐声系内部的结构如何,谐声分析基本上是无能为力的——也就是说,实际上存在着多种各样的可能性。
譬如,假如古典时期有 *b- 和 *mb- 的对立,以二者为声母的字也都使用「方系」声符。二者的对立后世中和了,一齐进入切韵「符类」。因此,无论从谐声行为上还是从切韵归派上来看,我们都察觉不出这个对立的痕迹来,只会将二者一概拟作 *b-。
譬如,假如古典时期有 *b- 和 *bʱ- 的对立,以二者为声母的字也都使用「方系」声符。二者的对立后世中和了,一齐进入切韵「符类」。因此,无论从谐声行为上还是从切韵归派上来看,我们都察觉不出这个对立的痕迹来,只会将二者一概拟作 *b-。
譬如,假如古典时期有 *b- 和 *ɓ- 的对立,以二者为声母的字也都使用「方系」声符。二者的对立后世中和了,一齐进入切韵「符类」。因此,无论从谐声行为上还是从切韵归派上来看,我们都察觉不出这个对立的痕迹来,只会将二者一概拟作 *b-。
譬如,假如古典时期有 *p- 和 *sp- 的对立,以二者为声母的字也都使用「方系」声符。二者的对立后世中和了,一齐进入切韵「方类」。因此,无论从谐声行为上还是从切韵归派上来看,我们都察觉不出这个对立的痕迹来,只会将二者一概拟作 *p-。
譬如,假如古典时期有 *pʰ- 和 *sp- 的对立,以二者为声母的字也都使用「方系」声符。二者的对立后世中和了,一齐进入切韵「芳类」。因此,无论从谐声行为上还是从切韵归派上来看,我们都察觉不出这个对立的痕迹来,只会将二者一概拟作 *pʰ-。
譬如,假如古典时期有 *pʵ- 和 *pʲ- 的对立,以二者为声母的字也都使用「方系」声符。二者的对立后世中和了,一齐进入切韵「方类 3b」。因此,无论从谐声行为上还是从切韵归派上来看,我们都察觉不出这个对立的痕迹来,只会将二者一概拟作 *pʵ-。
又譬如,假如古典时期有 *l- 和 *ɰ-(或 *ʟ-)的对立,又或者 *l- 和 *j-(或 *ʎ-)的对立,二者之间可以频繁地相互谐声。二者之间的对立后世中和了,一起进入切韵「以类」。因此,无论从谐声行为上还是从切韵归派上来看,我们都察觉不出这个对立的痕迹来,只会将二者一概拟作 *l-。
至于具体的音值,那不确定度就更大了。
我们不知道上文所谓的「非三等标记」是否真的是「+小舌性」——它总归可以别的东西,比如 *C- vs *əC- 也是有可能的。
我们不知道上文所谓的「卷舌标记」是否真的是「+卷舌」——它总归可以是别的东西,比如 *C- vs *rC- 也是有可能的。
我们不知道上文所谓的清响音是否真的是「+清」——它总归可以是别的东西,比如 *N- vs *sN- 也是有可能的。
我们甚至也都不知道上文所谓的「送气音」是否真的是「+送气」——它总归可以是别的东西,比如 *C- vs *sC- 也是有可能的。
这些都是从方法论上就注定得不到回答的问题。
有学者——比如 W. H. Baxter 与 L. Sagart——试图通过域外早期借词、内部构词等手段给上述问题一点答案。但是从结果来看,他们的努力基本上悉数失败了 [注10]。
首先,从现象上来看,几乎每种借入语所分析出的对立都各不相同,难以排除它们是在借过去的路上独立发生的可能(层次堆叠也是可能的)——要知道汉语在音译、借入梵语词汇的时候也一向不甚严谨,同一个梵语音节被译成不同汉语音节的情况屡见不鲜。周边语言在借入汉语词汇的时候,情况也完全有可能是类似的(然后这些借词连通该语言本身一起被后世的汉语洗成「底层」了也说不定) [注11]。W. H. Baxter 与 L. Sagart 试图拟合所有借词的结果就是堆砌出了种类极其繁多的 pre-initial,其中几乎每一种 pre-initial 所导致的对立都仅能体现在一种借入语之中,几乎没有任何交叉验证的空间,看起来就非常的不可信。
其次,W. H. Baxter 与 L. Sagart 也构拟了一些 pre-initial,用于解释构词现象。但与借词的情况类似,几乎没有任何交叉验证的空间。特别地,W. H. Baxter 与 L. Sagart 所构拟的一些 pre-initial 看起来既有语法功能又有导致借词对立的功能,但从现象上来说,二者之间的统计相关性约等于零,谈它们同出一源于理无据。
但这并不意味着他们的研究方向是错误的。搜集各方各面的、尽可能多的、可能与古典汉语(乃至更早期的上古汉语)相关的材料,分析出蕴含于这些材料之中的现象,观察这些现象之间是否有相关性,然后以此为基础进行综合性的构拟——这本来就是我们关于上古音所能做的全部事情。W. H. Baxter 与 L. Sagart 的问题只是在于其中「观察相关性」这一步做得不够好而已,整体思路依然是正确的。
琐碎的结语
本文就是「上古音」部分的最后一篇了。抱歉让各位久等了。
由于各种各样的原因,本文可以说是这三个星期之内赶工的产物,跟前两篇相比质量确实有很大的下滑,结构比较乱,论述比较难懂,行文比较苍白,风格也不怎么统一。假如我还像前两篇那样,总是等到 feel like writing 的时候才展开写上一两段,可能效果会好很多吧。但我确实已经等不起了。
本文的结论大概与一年半以前所写的 《总论及其他》有不少不同之处,现在一律以本文为准。
本文的原始数据见此:
链接: https://pan.baidu.com/s/1sjeifPQTS4Owpy6-OEmL-g
提取码:xq1c
该文档中还有针对每个谐声系的简要分析,各位读者可以随意使用,例如修改后重新发布也是可以的,不必申明原作者为本人。
本文提到了不少我没能解释的统计现象(以及我貌似作出了解释实则约等于没解释的现象),当然还有本文没提到的统计现象(有些可以通过上面这个文档看到,有些则不能——比如那些与韵尾相关的现象),这些现象各位也都可以尝试做出点解释。当然我个人觉得大概很难,研究个一年可能也不会有什么「还算有点确定性」的结果出来。
至于传世谐声之外的事情(包括更早期的上古音)…我觉得同样很难,当然各位也不妨一试吧。总之声母这边悬而未决甚至没能发现的问题还是很多的,不像韵母那边稳妥。
大概就是这些吧。各位如果有问题的话,在 2020 年 6 月 30 日(暂定)之前可以随便问,我尽量回答。问得好的话我可能会摘出来做个 Q&A,说不定也会挺有趣的呢。
注0:原则上来讲,通假分析与谐声分析并没有什么区别(假借谐声不分家嘛),而且麻烦事更多(比如材料杂散啊方音乱入啊经常撞字形啊什么的),结论也几乎完全一致,于是我懒得特地统计了。
注1:参见本人的回答: 古汉语发音可否通过其它语言考证?
注2:严格来讲,历代汉语的舌尖后缩程度可能一直不像梵语/印地语那么高,比如国际语音学会就因为普通话 r sh zh ch 舌尖后缩程度太低而不把它们当作卷舌音,并且拒绝用卷舌音符号来描述它们。但本文不考虑如此细节的问题,仍旧遵照大多数人的做法,称这个特征为「卷舌」。
注3:忽略极少数个例,后文同理不再注明。
注4:郑张-潘出来挨打,尤其是潘。是个人就能看出来没啥动程的 tʂa˞ 啊 tʂɛ˞ 啊远比有动程的 tʂɯa 啊 tʂɯɛ 啊省力得多(请注意这个 a 公认较前,潘悟云自己也认),结果这两位宝宝在两套模型对外解释力没什么区别的情况下选择了发音费力、音变链复杂的后者,真是搞不懂他们怎么想的。
注5:参见本人的回答: 上古汉语中的后元音三等韵为什么没能形成重纽?特别是其中的图1与图1下方的现象描述。
注6:宵韵其实有例外,但我们现在不去管它。
注7:如果像 Baxter 那样,给前者拟 *ʔ-,给后者拟 *q-,我们就得解释为什么一大堆 *qai,几乎没有 *ʔai,一大堆 *ʔam,几乎没有 *qam,等等。在增益十分有限的情况下,代价又如此之大,这个模型可真不怎么样,跟郑张-潘那套相比都好得有限。
注8:因此 *st- 模型也不大行——按照这个模型,我们有 57 个 *st-,但为什么我们没有数量级相当的 *stʶ-、*sʈ-?为什么我们没有数量级相当的 *sp-、*sk-?如果你说它们后世的演化与 *tʶʰ-、*ʈʰ-、*pʰ-、*kʰ-,我们理应观察到「之系」之中「昌」在「昌他丑」之中的占比显著低于「之」在「之都陟」之中的占比。然而实际上两个比例差不多,如果强行把这 57 个「式」也塞进去的话,「式昌」的占比就明显太高了。这很不合适。
注9:为了这十几二十个字单独加一整套清鼻音显然不经济。
注10:郑张-潘并不在此处的批评之列,因为他们搞的那套东西实际上就是仅靠传世谐声搭起来的。至于其他材料,他们的态度基本上是「顺我者拿来装点门面,逆我者直接无视」。至于他们搞出来的东西为何与本文有若干处不同,那只能怪潘悟云拍脑袋瞎想把郑张拐跑了。
注11:讲到这里我想起一件事。诸闽语白读主体层反正是有不能通过切韵那种清浊三分格局推导得出的其他对立——然而,从白读主体层的韵母来看,这个层次又特别地两晋南北朝,i.e. 像是两晋南北朝共通语的后裔。而另一方面,根据梵汉对音来看,两晋南北朝的塞音声母已经铁定是清浊三分格局了。假如诸闽语白读主体层所借入的确实是南北朝共通语(这个命题大概率为真,否则韵母真不好解释),那么其塞音声母格局理应可以由清浊三分导出,然而实际上并不能。如果这个对立是「方言混合」或曰「随机分化」产出的,规模又未免太大了些。进也不是,退也不是,这事很令人抓狂。