自然语言处理中的注意力机制是怎么回事?

王小新 编译自Quora
量子位 出品 | 公众号 QbitAI
谈神经网络中注意力机制的论文和博客都不少,但很多人还是不知道从哪看起。于是,在国外问答网站Quora上就有了这个问题:如何在自然语言处理中引入注意力机制?
Quora自家负责NLP和ML的技术主管Nikhil Dandekar做出了一个简要的回答:
概括地说,在神经网络实现预测任务时,引入注意力机制能使训练重点集中在输入数据的相关部分,而不是无关部分。
注意力是指人的心理活动指向和集中于某种事物的能力。比如说,你将很长的一句话人工从一种语言翻译到另一种语言,在任何时候,你最关注的都是当时正在翻译的词或短语,与它在句子中的位置无关。在神经网络中引入注意力机制,就让它也学会了人类这种做法。
注意力机制最经常被用于序列转换(Seq-to-Seq)模型中。如果不引入注意力机制,模型只能以单个隐藏状态单元,如下图中的S,去捕获整个输入序列的本质信息。这种方法在实际应用中效果很差,而且输入序列越长,这个问题就越糟糕。
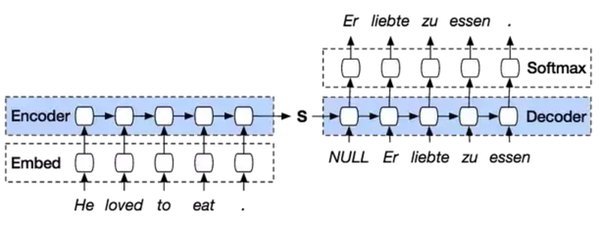

图1:仅用单个S单元连接的序列转换模型
注意力机制在解码器(Decoder)运行的每个阶段中,通过回顾输入序列,来增强该模型效果。解码器的输出不仅取决于解码器最终的状态单元,还取决于所有输入状态的加权组合。
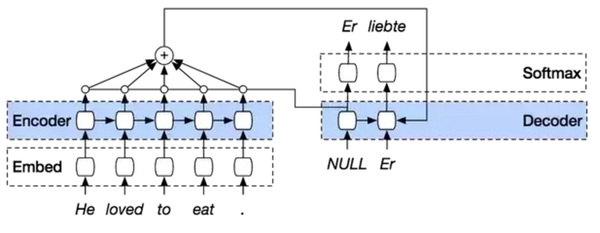

注意力机制的引入增加了网络结构的复杂性,其作为标准训练模型时的一部分,通过反向传播进行学习。这在网络中添加模块就能实现,不需要定义函数等操作。
下图的例子,是将英语翻译成法语。在输出翻译的过程中,你可以看到该网络“注意”到输入序列的不同部分。


由于英语和法语语序比较一致,从网络示意图可以看出,除了在把短语“European Economic Zone(欧洲经济区)”翻译成法语“zone économique européenne”时,网络线有部分交叉,在大多数时,解码器都是按照顺序来“注意”单词的。
文中配图来自Distill
推荐阅读:
Attention and Augmented Recurrent Neural Networks Attention and Augmented Recurrent Neural Networks
Attention and Memory in Deep Learning and NLP Attention and Memory in Deep Learning and NLP
Peeking into the neural network architecture used for Google's Neural Machine Translation Peeking into the neural network architecture used for Google's Neural Machine Translation
【完】
文章被以下专栏收录
