
语音转换综述

通读转换的综述论文后,做一个中文版综述总结。
语音转换概述及其挑战: 从统计建模到深度学习(下)
基于深度学习的语音转换
语音转换是一个训练数据稀缺的典型研究问题。深度学习技术通常是数据驱动的,依赖于大数据。然而,这实际上是深度学习在语音转换中的优势。深度学习为从大量可用的训练数据中获益开辟了许多可能性,这样语音转换任务就可以更多地专注于学习说话人特征的映射。例如,在语音重建过程中推断低层次的细节不应该是语音转换任务的工作,神经声码器可以从大型数据库中学习来完成这一工作。学习如何表示一种口语的整个语音系统不应该是一项语音转换的任务,ASR或TTS系统的通用声学模型可以从一个大型数据库中学习来完成这一任务。通过利用大型数据库,我们解放了转换网络,不再使用它的能力来表示低级细节和一般信息,而是将重点放在说话人身份转换所需的高级语义上。
深度学习技术也改变了我们实现分析-映射-重建管道的方式。为了有效映射,我们需要推导出足够的语音中间表示,这在之前已经讨论过了。深度学习中的嵌入概念为推导中间表示提供了一种新的方法,例如,语言内容的隐码和说话人身份的嵌入。这也使得演讲者从演讲内容中解脱出来更加容易。在本节中,我们将总结深度学习如何帮助解决现有的研究问题,如并行和非并行数据的语音转换。我们还将回顾深度学习如何在语音转换研究中开辟新领域。
A.帧对齐的平行语料的深度学习语音转换
DNN映射函数:早期基于DNN的语音转换方法的研究主要集中在频谱变换上。DNN映射函数y = F(x)与其他统计模型如GMM和DKPLS相比有一些明显的优势。例如,它允许源特征和目标特征之间的非线性映射,并且对要建模的特征维度几乎没有限制。我们注意到,对其他声学特征的转换,如基频和能量轮廓,也可以进行类似的操作。
Desai等人提出了一种DNN来映射从源到目标说话者的低维谱表示,如梅尔倒谱系数(MCEP)。Nakashika等提出使用深度信念网(DBNs)从源和目标倒谱系数中提取潜在特征,并使用一层隐含的神经网络在潜在特征之间进行转换。Mohammadi等人通过研究来自多个说话人的深度自编码器,进一步发展了这一想法,从而得到语音频谱特征的紧凑表示。频谱的高维表示也在最近的研究中被用于频谱映射,以及动态特征和参数生成算法。一般来说,用于频谱和/或韵律转换的DNN需要大量来自成对说话者的并行训练数据,这并不总是可行的。但它为我们利用源和目标之外的多个说话者的语音数据,更好地建模源和目标说话者,并发现更好的特征表示来进行特征映射提供了机会。
LSTM映射函数:为了在语音转换中对语音帧之间的时间相关性进行建模,Nakashika等探讨了循环时间受限玻尔兹曼机器(RTRBM)的使用,这是一种循环神经网络。LSTM (Long-Short Term Memory, LSTM)在序列到序列建模中的成功,启发了LSTM在语音转换中的研究,提高了语音输出的自然性和连续性。LSTM可以学习用于语音转换的最佳上下文信息量。双向LSTM (BLSTM)网络有望从正向序列和反向序列中捕获序列信息并维护远程上下文特征。
语音转换的研究问题主要围绕对齐和映射,这两者在训练和运行时推理时都是相互关联的,如图1所示。在训练过程中,更精确的对齐有助于建立更好的映射函数,这就解释了为什么我们更喜欢平行的训练数据。在运行时推理时,框架级映射范式在转换期间不会改变语音的持续时间。虽然可以对语音转换输出的持续时间进行建模和预测,但系统地将持续时间模型和映射模型结合起来并不容易。深度学习为这一研究问题提供了新的解决方案。
B.编码器-解码器结构神经网络
编码器-解码器结构神经网络中的注意机制带来范式变化。注意力的概念首次成功地应用于机器翻译、语音识别和序列对序列语音合成,这导致了许多关于语音转换的平行研究。通过注意机制,神经网络在训练过程中同时学习特征映射和对齐。在运行推断时,网络根据它所学的内容自动决定输出时间。换句话说,不再需要帧对齐器。
有几种基于递归神经网络的变化,如序列到序列转换网络(SCENT)和AttS2S-VC。他们关注的是广泛使用的编解码器架构。假设我们有一个源语音x = {x1, x2x、…Ts }。编码器网络首先将输入特征序列转换为隐藏表示,h = {h1, h2, h…Th }以较低的帧率与Th < Ts ,适合解码器来处理。在每个解码器时间步长,注意模块根据注意概率聚合编码器输出并产生上下文向量。然后,解码器预测输出的声学特征。此外,设计了一个后滤波网络来提高转换后的声学特征的准确性,以生成转换后的语音y = {y1, y2y, …,Ty }。在训练过程中,注意机制学习源序列和目标序列之间的映射动态。在运行推断时,解码器和注意力机制相互作用,同时执行映射和对齐。整体架构如图1所示。
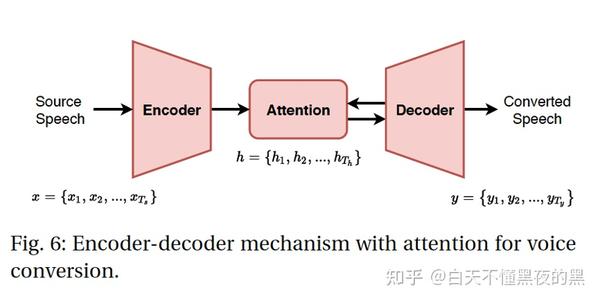

虽然递归神经网络是序列到序列转换的有效实现,但最近的研究表明,卷积神经网络也能很好地学习长期依赖关系。它采用了一种注意机制,有效地使编码和解码的并行计算成为可能。在解码过程中,因果卷积设计允许模型以自回归的方式产生输出序列。Kameoka等人提出了一种用于语音转换的卷积神经网络实现,称为ConvS2S-VC。最近的研究表明,convs2 - VC在成对和多对多语音转换方面都优于循环神经网络。带有注意力的编码器-解码器结构标志着与框架级映射范式的背离。注意不执行逐帧映射,而是允许解码器处理多个语音帧,并在解码过程中使用软组合来预测输出帧。在注意机制下,转换后的语音的持续时间与源语音的持续时间有明显的不同,反映源语和目的语说话风格的差异。这代表了一种同时处理频谱和韵律转换的方法。研究将语音质量的提高归因于有效的注意机制。注意机制也代表了放松语音转换中并行数据的严格要求的第一步。
C. 非平行语料
最近的研究表明,深度学习可以在不需要并行数据的情况下实现许多语音转换场景。在本节中,我们将研究总结为四种场景,
1)成对说话人的非并行数据,
2)利用TTS系统,
3)利用ASR系统
4)将说话人从语言内容中解耦出来。
1)成对说话人的非并行数据:具有非并行训练数据的语音转换是一项类似于图像到图像转换的任务[,即在不需要并行训练数据的情况下,寻找从源域到目标域的映射。让我们来比较一下图像到图像转换和语音转换之间的相似之处。在图像翻译,我们想翻译一匹斑马,我们保护马的结构和改变马的外套的斑马。在语音转换,我们想改变另一个声音,同时保留语言、韵律的内容。CycleGAN是基于对立的概念学习,这是训练生成模型之间找到一个解决方案在min-max游戏两个神经网络,称为生成器(G)和鉴频器(D)。
由于语音数据是非并行的,很难实现对齐。Kaneko和Kameoka首先研究了CycleGAN,其中包含三个损失函数:对抗损失、周期一致性损失和身份映射损失,以学习源和目标speaker之间的正向和反向映射。CycleGAN代表了一个成功的深度学习实现,从成对说话者的非并行数据中找到最优伪对。它不需要任何帧对齐机制,如动态时间扭曲或注意。实验结果表明,在非并行训练数据下,CycleGAN的训练性能与基于gmm的系统在两倍并行数据上的训练性能相当。此外,通过对抗性训练,有效地克服了过平滑问题,这是导致语音质量下降的主要因素之一。我们注意到,最近研究了CycleGAN- vc2 (CycleGAN- vc的改进版本),它通过合并三种新技术进一步改进了CycleGAN:改进的目标(两步对抗损失)、改进的生成器(2-1-2D CNN)和改进的鉴别器(PatchGAN)。CycleGAN已成功应用于单语、跨语语音转换、情感语音转换和灵活节奏语音转换。
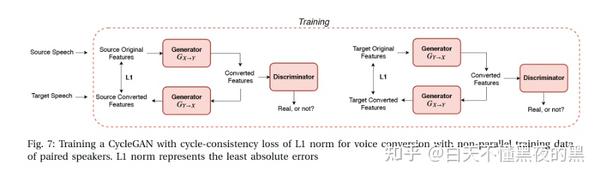

与编码器-解码器结构不同,CycleGAN遵循生成建模体系结构,该体系结构不显式地建模一些内部表示,以支持灵活的操作,如语音标识、语音持续时间和情感。因此,它更适合于特定源对和目标对之间的语音转换。尽管如此,它代表了非并行数据语音转换的一个重要里程碑。
2)利用TTS系统:我们已经讨论了不涉及文本的语音转换的深度学习架构。语音转换的一个重要方面是将语言内容从源说话人传递到目标说话人。语音转换和TTS系统在某种意义上是相似的,它们都以产生具有适当语言内容的高质量语音为目标。TTS系统为语音遵循语言内容提供了一种机制。利用TTS机制的想法可以通过不同的方式来激励。首先,在一个大型语音数据库上训练TTS系统,在给定语言内容的基础上提供高质量的语音重建机制;其次,TTS系统具有语音转换所需的质量注意机制。


近来,编码器-解码器模型在建模各种复杂的序列到序列问题方面取得了相当大的成功。Tacotron代表了一种成功的文本到语音(TTS)实现,该实现已扩展到语音转换。利用TTS知识的策略建立在共享注意知识和共享解码器体系结构的思想之上。Zhang等人提出了一种语音转换网络迁移学习技术,该技术从TTS注意力机制衍生的语音上下文向量进行学习,并与TTS系统共享解码器,是这种杠杆的典型例子。
3)利用ASR系统:用于语音转换的深度学习方法通常需要一个大型并行语料库来进行训练。这部分是因为我们想要学习描述语音系统的潜在表示法。对培训数据的要求限制了潜在应用的范围。我们知道,大多数ASR系统已经用大量的语料库进行了训练。它们已经用不同的方式很好地描述了语音系统。问题是如何利用ASR系统中的潜在表示进行语音转换。
其中一个想法是使用序列到序列学习的ASR模型产生的上下文后验概率序列来生成目标语音特征序列。在这个模型中,系统具有类似于编码器-解码器结构,只是它使用一个语音识别器作为编码器,一个语音合成器作为解码器。另一项研究是通过ASR系统来指导序列到序列语音转换模型,该系统用bottleneck特征来增强输入。最近,一种端到端语音序列换能器Parrotron被研究。Parrotron学习将任何有多个口音和缺陷的说话者的语音图谱转换为单个预定义目标说话者的声音。Parrotron通过使用辅助ASR解码器来实现这一点,以编码器潜在表示为条件来预测输出语音的文本。Parrotron的多任务训练优化解码器生成目标语音,同时约束潜在表示只保留语言信息。ASR解码器的目的是将讲话者的身份从语音中分离出来。上述技术均采用带注意力结构的编解码器。
语音转换的另一种方法是,语音由两个组成部分组成,即说话人依赖的组成部分和说话人独立的组成部分。如果我们能够将语音信号分解为这两种成分,我们就可以继续保留前者,而只对后者进行转换才能实现语音转换。PPG特性来源于ASR系统,可以认为是说话人独立的。我们从多说话人、非并行语音数据中训练映射函数。这样,就不需要为每个目标说话者训练一个完整的转换模型。在目标语音量较小的情况下,该平均模型可以适用于目标语音。对平均模型的训练和适应性进行了说明
4)区分说话人与语言内容:在语音转换的背景下,语音可以被认为是说话人语音身份和语言内容的组合。如果我们能够将说话人从语言内容中解脱出来,我们就可以独立于语言内容改变说话人的身份。自动编码器是语音解耦和重构的常用技术之一。还有其他一些技术,如实例归一化和矢量量化,可以有效地将speaker从内容中分离出来。
自动编码器学习将输入复制为输出。因此,不需要并行训练数据。编码器学习用隐码表示输入,解码器学习从隐码重建原始输入。潜在代码可以看作是一个信息瓶颈,一方面让我们传递必要的信息,如与说话人无关的语言内容,以实现完美的重构,另一方面又迫使一些信息被丢弃,如说话人、噪声和信道信息。变分自编码器(VAE)是自编码器的随机版本,其中编码器产生的分布在潜在表示,而不是确定的潜在码,而解码器训练样本来自这些分布。变分自编码器比确定性自编码器更适合于合成新样本。
Chorowski等人通过研究三种自编码神经网络如何从语音数据中学习表示,从而将说话人身份从语言内容中分离出来,提供了一种比较。研究表明,离散表示法,即从VQ- VAE获得的潜码,保留了最多的语言内容,同时也是最具说话人不变性的。最近,为了改进编码过程,研究了一种VQ-VAE的群潜伏嵌入技术,该技术将嵌入字典分组,使用最近群原子的加权平均作为潜伏嵌入。
基于VAE的语音转换框架的概念如图4所示。一种用于语音转换的典型自动编码网络,编码器和解码器解耦说话人信息和内容信息。 在推理时,源语音的语言学特征被编码成潜在变量,拼接说话人embedding信息生成目标语音。
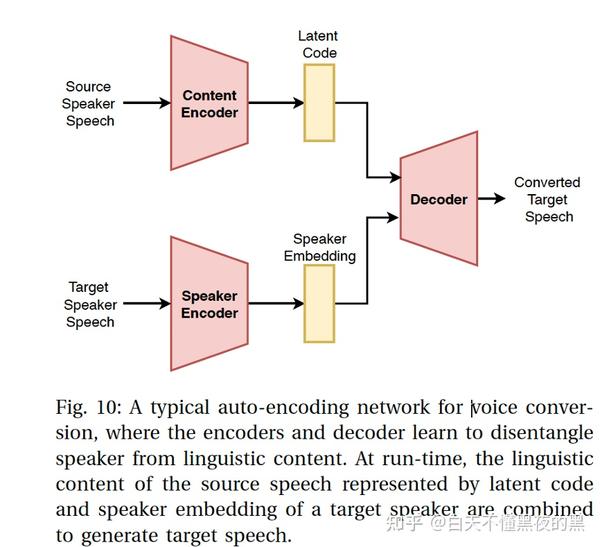
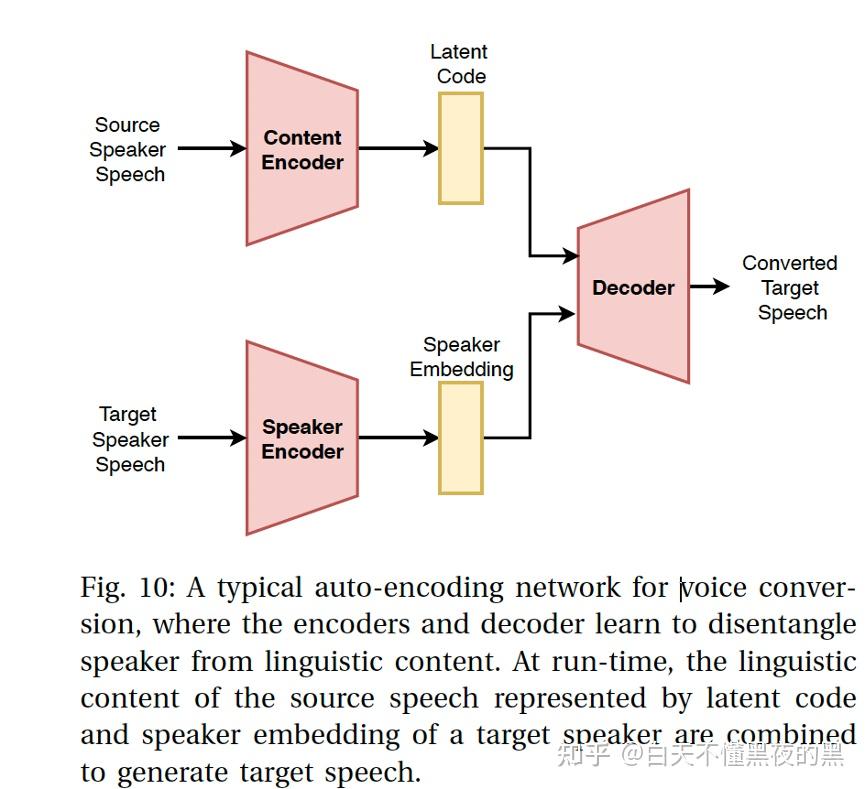
就像其他自动编码器一样,VAE解码器往往产生过平滑的语音。这对于语音转换来说是有问题的,因为网络可能会产生质量较差的嗡嗡声。生成对抗网络(GANs)被提出作为过度平滑问题的解决方案之一。GANs提供了一个训练数据生成器的一般框架,它可以欺骗试图区分生成器产生的真实数据和虚假数据的真/假鉴别器。将GAN概念融入VAE中,研究了VAE-GAN在非并行训练数据下的语音转换和跨语言语音转换。研究表明,VAE-gan比标准的VAE方法产生更自然的发音。
参考资料:
An Overview of Voice Conversion and its Challenges: From Statistical Modeling to Deep Learning
更多关于语音合成和语音转换的技术分享可关注公众号: