
深度 | 从AlphaGo的成功说起

原文发表于中国计算机学会通讯,2017年第3期,p76-81
作者: 文因互联团队张梦迪、郑锦光、张强、鲍捷
AlphaGo的基本原理
继 AlphaGo于2015年8月以5:0战胜三届欧洲冠军樊麾、2016年3月以4:1击败世界顶级棋手李世石后,今年1月,AlphGo的升级版本Master横扫各路高手,取得60:0的惊人战绩。20 年前IBM深蓝(Deep Blue)计算机击败国际象棋冠军卡斯帕罗夫的情景还历历在目,短短2年时间,人工智能在围棋领域又创造了人机对抗历史上的新里程碑。
根据谷歌DeepMind团队发表的论文[1],我们可以窥探到AlphaGo的基本设计思路。任何完全信息博弈都无非是一种搜索。搜索的复杂度取决于搜索空间的宽度(每步的选择多寡)和深度(博弈的步数)。对于围棋,宽度约为250,深度约为150。AlphaGo用价值网络(value network)消减深度,用策略网络(policy network)消减宽度,从而极大地缩小了搜索范围。
所谓价值网络,是用一个“价值”数来评估当前的棋局。如果我们把棋局上所有棋子的位置总和称为一个“状态”,每个状态可能允许若干不同的后续状态。所有可能状态的前后次序关系就构成了所谓的搜索树。一个暴力的搜索算法会遍历这个搜索树的每一个子树。但是,其实有些状态是较容易判断输赢的,也就是评估其“价值”。我们把这些状态用价值表示,就可以据此省略了对它所有后续状态的探索,即利用价值网络削减搜索深度。


所谓策略,是指在给定棋局,评估每一种应对可能的胜率,从而根据当前盘面状态来选择走棋策略。在数学上,就是估计一个在各个合法位置上下子获胜可能性的概率分布。因为有些下法的获胜概率很低,可忽略,所以用策略评估就可以消减搜索树的宽度。
更通俗地说,所谓“价值”就是能看懂棋局,一眼就能判断某给定棋局是不是能赢,这是个偏宏观的评估。所谓的“策略”,是指在每一步博弈时,各种选择的取舍,这是个偏微观的评估。AlphaGo利用模拟棋手、强化自我的方法,在宏观(价值评估)和微观(策略评估)两个方面提高了探索的效率。
在具体算法上,AlphaGo用深度卷积神经网络(CNN)来训练价值网络和策略网络。棋盘规模是(19×19),棋盘每个位置编码48种经验特征。把这些特征输入模型进行训练,经过层层卷积,更多隐含特征会被利用。
基于类似的卷积神经网络结构,AlphaGo先做策略学习(学习如何下子),再做价值学习(学习评估局面)。策略学习也分为两步。第一步是有监督学习,即“打谱”,学习既往的人类棋谱。第二步是强化学习,即“左右互搏”,通过程序的自我博弈来发现能提高胜率的策略(见图1)。
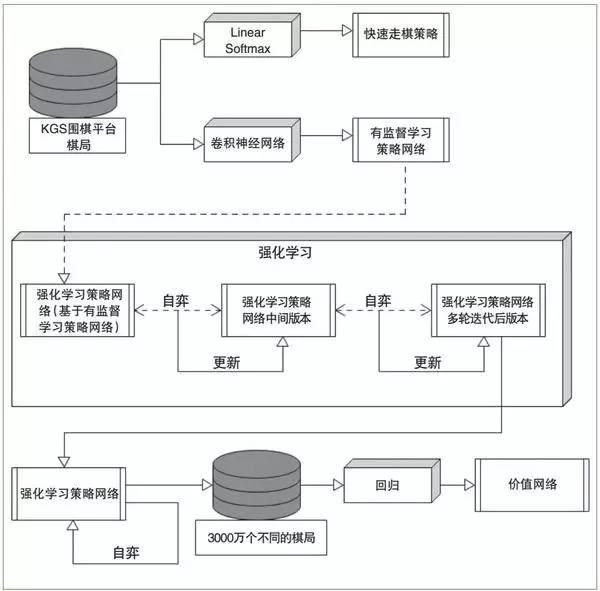

图1 策略网络和价值网络的训练过程
先说“打谱”(有监督学习)。AlphaGo学习了KGS网站上3000万个落子位置。它先随机选择落子位置,利用既往的棋谱来“训练”,试图预测人类最可能在什么位置落子。
如果仅用落子历史和位置信息,AlphaGo的预测成功率是55.7%。如果加上其他特征,预测成功率可以进一步提高到57%。
在数学上,打谱是用一种梯度下降算法训练模型。给定一个棋局和一个落子方式,为了计算人类棋手会有多大概率采用这种下法,AlphaGo用一个13层的卷积网络来训练这个概率的评估。这也是神经网络应用的经典做法,即基于梯度下降来逼近一个函数的学习,这里函数就是棋手如何落子的概率。
再说“左右互搏”(强化学习)。这是在打谱的基础上,让不同下法的程序之间相互博弈。强化学习的策略网络和有监督学习(打谱)的网络结构一样,也同样利用梯度下降的学习方法。区别在于用一个“回报”(赢棋是1,输棋是-1)来奖励那些会导致最终获胜的策略。
价值网络的学习和策略网络类似,也用类似结构的卷积神经网络。区别在于网络的输出不是一个落子的概率分布,而是一个可能获胜的数值(即“价值”)。这个训练是一种回归(regression),即调整网络的权重来逼近每一种棋局真实的输赢预测。
如果只是简单地让程序之间自由博弈,可能会导致过拟合:对训练的数据(棋谱)效果很好,但是对于没见过的棋局效果欠佳。这是因为一盘棋内不同的棋局之间是有依赖关系的,而价值函数并不考虑这些关系。解决方法是用来自不同对弈过程的棋局的落子位置进行训练,避免来自同一棋局的状态之间的“信息污染”(相关性)。
有了策略网络和价值网络,就可以进行策略的搜索了。AlphaGo使用了蒙特卡洛树搜索(MCTS)算法。所谓搜索,就是给定一个棋局,确定下一步的落子位置。这分为“往下搜”和“往回看”两个环节。在“往下搜”的环节,对给定的棋局,程序选择最可能获胜的落子位置,然后如此类推,直到搜索树上能分出结果的“叶子”节点。在“往回看”的环节,一个棋局各种不同的演化可能性被综合评估,用于更新搜索树对棋局的评估。
为了提高训练效率,AlphaGo利用图形处理器(GPU)运行深度学习算法(训练价值网络和策略网络),利用中央处理器(CPU)运行树搜索算法。因为GPU适合做大吞吐量、低逻辑判断的工作,适合深度学习这种数据量大而逻辑简单的算法。CPU则恰恰相反,适合蒙特卡洛树搜索这种逻辑复杂的算法。
AlphaGo为什么能赢
拆开看AlphaGo算法的每个部分,其实都是已有的成熟技术,创新之处是将这些技术进行组合,并在具体的问题上进行优化。
人工智能是如何打败职业棋手的?核心是机器在策略学习中的高效率和因此带来的超越人类的策略的突破。与其说AlphaGo和Master标志着机器对人类的胜利,不如说是科学家联手工程师对行业专家的胜利,是通用计算基础和理论框架日益臻熟的体现。这已不是第一次机器的胜利,情理之中,意料之外。
和当年的国际象棋程序深蓝相比,AlphaGo有哪些进步?
它可以用策略网络更“聪明”地选择应对,用价值网络更“精确”地评估局面。另外,它不再单纯依赖于手工构造的评估函数,而是利用了深度学习的特征学习能力,仅仅使用通用的监督学习算法和强化学习就实现了领域建模,降低了对人类专家的依赖。
从表面上看,AlphaGo的成功取决于对暴力搜索效率的提升。但在大规模效率提升的基础上,从量变到质变,计算机甚至可以下出人类从来没有想过的下法。人在围棋中引以为豪的大局观、棋感,可能恰恰是有限计算量限制下的无奈之举。计算机却可以跳出这些限制来开创。
中国棋手柯洁在与Master对弈后说:“人类数千年的实战演练进化,计算机却告诉我们人类全都是错的。我觉得,甚至没有一个沾到围棋真理的边。从现在开始,我们棋手将结合计算机,迈向全新的领域达到全新的境界。”
简明人机对抗史
目前,在人机对战类游戏中,人工智能解决得比较出色的基本上都是零和游戏。其中,比较出名的人工智能机器有:深蓝[2]、Watson[3]、AlphaGo[1]和最近刚刚拿了德州扑克比赛第一名的Libratus[4]。


深蓝是IBM研发的一款针对国际象棋对战的计算系统。1997年,深蓝以3.5:2.5的比分战胜了当时的国际象棋世界冠军帕斯卡罗夫。深蓝能够取得这个巨大成功,主要归功于IBM当时为之设计的高性能超级计算机。这台计算机拥有32个IBM RS/6000 SP核, 256个处理器,能够在一秒钟内完成对200万个状态的分析。即使深蓝使用的是接近“暴力搜索”的算法,这种计算能力对于深蓝在分析国际象棋局面上已然足够。
2011年,由IBM团队研发的智能问答系统Watson在问答游戏“危险边缘(Jeopardy! )”中击败了之前的人类赢家布拉德·鲁特(Brad Rutter)和肯·詹宁斯(Ken Jennings)。Watson是问答系统技术的集大成者,其中关键的技术创新有:一套复杂的证据可信度评估系统,让机器从数万种可能的选择中发现最可能的答案;运用新兴的语义网技术和结构化知识库,融合常识知识;综合运用基于知识库和基于信息检索的技术,降低知识获取和表达的成本。
在很长一段时间,围棋被认为是在游戏对战人工智能中,人类智慧守护的最后一片土地。MoGo[5]在2008年的美国围棋公开赛上,第一次在19×19的全尺寸棋盘上击败了职业选手(与AlphaGo不同,这位职业选手让了9个子)。到2016年,AlphaGo以4:1的战绩击败职业九段选手李世石,以及之后Master更以快棋60赢0负的惊人战绩横扫线上围棋平台。就如本文之前提到的,在围棋中,由于搜索的复杂度,单纯的“暴力搜索”的算法已然不再适用。
2017年1月,由卡内基梅隆大学(CMU)教授桑德霍尔姆(Sandholm)带领开发的Libratus又为人工智能攻克了一个战场:德州扑克。扑克不同于围棋,是非完整信息博弈。Libratus采用的方法里包括了博弈论。大量的经济学、金融、政治和社会问题都可以在博弈论的框架下建模,因此,Libratus的成功打开了在诸多新领域应用人工智能的大门。
从深蓝到Libratus,人机对抗中部分关键项目和算法的回顾如表1所示。
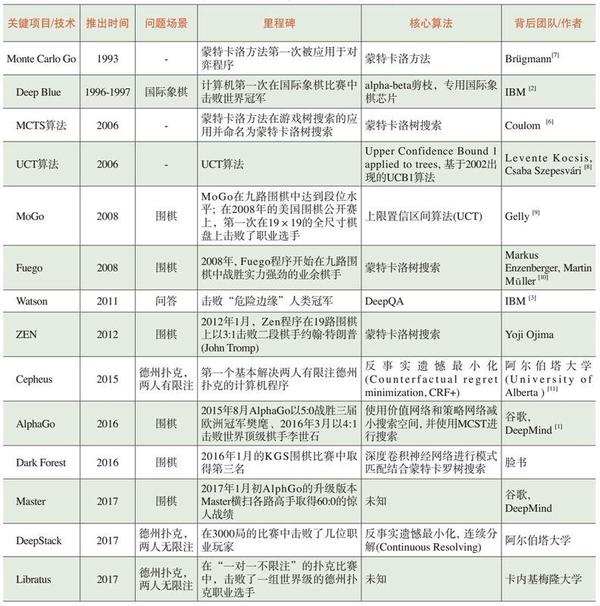

表1 人机对抗中部分关键项目和算法
下一个赛点会在哪里
可以看到,目前人工智能所攻克的棋牌类游戏,基本属于动态双人非合作的零和博弈,存在前提假设是参与者有明确的策略空间和收益函数,并且都是与时间无关的。
这里参与者策略空间是在当前的牌局或者棋局下可以采取的行为。收益函数指当所有参与者都采取某种策略后,当前参与者所获得的收益。零和意味着参与者胜/负/平的游戏结果简洁明了。在这样相对封闭的游戏空间中,给定明确参数,相对较短时间,通过海量轮次的深度学习和强化学习,人工智能技术可能会发现一些人类没有发现的特征,找出一些人类没有意识到的相关性,走出一些人类没法理解的棋,也就是人们常说的“AI棋”。
当探索人工智能所能征服的下一个领域的时候,将面临如下挑战:
- 1.面对多人合作博弈,策略空间和收益函数都难以确定。
- 2.面对非零和博弈,强化学习所依赖的回报函数难以确定。
- 3.面对开放的领域空间,时间维度因素对强化学习的影响难以确定。
为了应对这些情况,人工智能可能采取的策略是对领域抽象建模,设定前提条件,构造封闭问题空间,实现对真实领域的映射。这个过程必然会依赖人类的智慧,也是将人工智能技术扩展到其他领域的关键瓶颈所在。
那么,未来可能突破的领域会有怎样的特点呢?我们用金融投资领域作为例子。这里的金融投资是指对公司价值进行分析判断来进行的投资活动,而非日内交易型的投机活动。在该前提下,参与者的策略空间和收益函数是经过系统研究的,有一系列的价值策略投资理论作为支撑。
对于金融投资,结束条件的界定可以进行分类处理,比如单笔交易、时间周期和投资的计量结果是“可微分的”。回报函数可以抽象为在某种具体某种类型的投资约束条件下的盈亏。时间维度问题,可以依靠金融和法律知识去构建一个局部的单一时间维度的场景,也可以通过算法去把不同时间维度标准化。
对这样的领域,尽管存在领域知识要求非常高、信息不完备、非封闭世界等困难,我们是可能融合AlphaGo和Libratus的方法论,开发出优于初级人类分析师的AI程序的。
人工智能技术在向其他领域扩展的时候,很大程度上依赖于人类对该领域的建模和抽象。大众对人工智能技术好奇,核心关注点往往是人工智能是否摆脱人类影响,是否具有自由意识和思维等。这里涉及到人工智能的诸多哲学问题,包括概念框架问题、常识表征问题和现象意识问题等。


AlphaGo在过去一年的成功,引发了媒体和很多领域对人工智能的强大兴趣和一些不必要的担心。现在的人工智能,离这种担心所对应的强人工智能,还有很远的距离。给定目标问题求解的能力,和可以自主寻找问题、设定目标的能力还是有很大差距的。技术落地的设计、工程化也有很长的路要走。
参考文献
[1] Silver D, Huang A, Maddison C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484-489.
[2] Campbell M, Hoane A J, Hsu F. Deep Blue[J]. Artificial Intelligence, 2002, 134(1-2): 57-83.
[3] Ferrucci D, Brown E, Chu-Carroll J, et al. Building Watson: An overview of the DeepQA project[J]. AI Magazine, 2010, 31(3): 59-79.
[4] Brown N, Sandholm T. Strategy-based warm starting for regret minimization in games. Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16), 2016:432-438.
[5] Gelly S, Wang Y, Teytaud O, et al. Modification of UCT with patterns in Monte-Carlo Go[J]. HAL-INRIA, 2006.
[6] Coulom R. Efficient selectivity and backup operators in Monte-Carlo tree search. Proceedings of International Conference on Computers and Games. Springer Berlin Heidelberg, 2006: 72-83.
[7] Brügmann B. Monte Carlo Go[R]. Technical report, Physics Department, Syracuse University, 1993.
[8] Kocsis L, Szepesvári C. Bandit based Monte-Carlo planning. Proceedings of European Conference on Machine Learning. Springer Berlin Heidelberg, 2006: 282-293.
[9] Gelly S, Wang Y, Teytaud O, et al. Modification of UCT with patterns in Monte-Carlo Go[J]. HAL-INRIA, 2006.
[10] Enzenberger M, Muller M, Arneson B, et al. Fuego—an open-source framework for board games and Go engine based on Monte Carlo tree search[J]. IEEE Transactions on Computational Intelligence and AI in Games, 2010, 2(4): 259-270.
[11] Bowling M, Burch N, Johanson M, et al. Heads-up limit hold’em poker is solved[J]. Science, 2015, 347(6218): 145-149.
[12] Moravčík M, Schmid M, Burch N, et al. DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker. arXiv preprint arXiv:1701.01724, 2017.
[13] Tian Y, Zhu Y. Better computer go player with neural network and long-term prediction. arXiv preprint arXiv:1511.06410, 2015.
文章被以下专栏收录
