首发于 机器学习专栏
切换模式
15-【理论】AdamW 牛刀小试

Lukas-i33
冷冷清清地风风火火,认认真真地活在当下
最近因项目原因,在接触类 GPT 模型,好奇地发现对于 Transformer 模型很多工程都使用了 AdamW 作为优化器,准备看看他对于 Adam 有何不同,论文中的主要核心点在于:




以 LogisticReg 为例做下简单的推导:
1、数据

2、假设函数

3、PDF
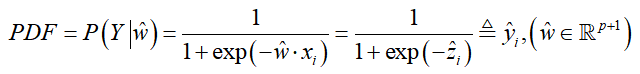

4、Likelihood


5、损失函数


6、优化目标

7、优化


7.1、GD (Gradient Descent)

for t in range(epochs):
y_hat = 1.0 / (1 + np.exp(-x_train.dot(w)))
loss = objt(y_train, y_hat)
print(f"epoch {t} loss {loss:.4f}")
dx = -1.0 * x_train.T.dot(y_train.reshape(-1, 1) - y_hat) / len(x_train)
w = w - lr * dx7.2、GDM (Gradient Descent with Momentum)

beta = 0.9
v = 0
def gradient_descent_with_momentum(beta, v, dx):
v = beta * v + (1 - beta) * dx
return v
for t in range(epochs):
y_hat = 1.0 / (1 + np.exp(-x_train.dot(w)))
loss = objt(y_train, y_hat)
print(f"epoch {t} loss {loss:.4f}")
dx = -1.0 * x_train.T.dot(y_train.reshape(-1, 1) - y_hat) / len(x_train)
v = gradient_descent_with_momentum(beta, v, dx)
w = w - lr * 7.3、Adam (Adaptive Moment Estimation)


beta1 = 0.9
beta2 = 0.999
v = 0
s = 0
decay = 0
eps = 10**-8
def adam(beta1, beta2, v, s, dx, t):
v = beta1 * v + (1 - beta1) * dx
s = beta2 * s + (1 - beta2) * (dx**2)
v = v / (1 - beta1**t)
s = s / (1 - beta2**t)
return v, s
for t in range(1, epochs+1):
y_hat = 1.0 / (1 + np.exp(-x_train.dot(w)))
loss = objt(y_train, y_hat)
print(f"epoch {t} loss {loss:.4f}")
dx = -1.0 * x_train.T.dot(y_train.reshape(-1, 1) - y_hat) / len(x_train)
v, s = adam(beta1, beta2, v, s, dx, t)
lrm = lr * (1 - decay)**t
w = w - lrm * (v / (np.sqrt(s) + eps))7.4、AdamW (Adam with decoupled weight decay)


beta1 = 0.9
beta2 = 0.999
v = 0
s = 0
decay = 0.01
eps = 10**-8
lamb = 1/8 * 0.001
for t in range(1, epochs+1):
y_hat = 1.0 / (1 + np.exp(-x_train.dot(w)))
loss = objt(y_train, y_hat)
print(f"epoch {t} loss {loss:.4f}")
dx = -1.0 * x_train.T.dot(y_train.reshape(-1, 1) - y_hat) / len(x_train)
v, s = adam(beta1, beta2, v, s, dx, t)
lrm = lr * (1 - decay)**t
w = w - lrm * (v / (np.sqrt(s) + eps) + lamb*w)8、完整代码
Demo_AdamW.py
编辑于 2023-04-26 20:02・IP 属地江苏
机器学习
深度学习(Deep Learning)
凸优化
文章被以下专栏收录
